流畅的 Python
流畅的 Python
数据模型
(Data Model)
数据模型其实是对 Python 框架的描述,它规范了这门语言自身构建模块的接口,这些模块包括但不限于序列、迭代器、函数、类和上下文管理器
通过实现特殊方法,自定义数据类型可以表现得跟内置类型一样,从而让我们写出更具表达力的代码——或者说,更具 Python 风格的代码。
特殊方法
Python 解释器碰到特殊的句法时,会使用特殊方法去激活一些基本的对象操作,这些特殊方法的名字以两个下划线开头,以两个下划线结尾(例如 __getitem__)。比如 obj[key] 的背后就是 __getitem__ 方法,为了能求得 my_collection[key] 的值,解释器实际上会调用 my_collection.__getitem__(key)。
魔术方法(magic method)是特殊方法的昵称,也叫双下方法(dunder method)
通过实现特殊方法来利用 Python 数据模型有两个好处:
- 作为你的类的用户,他们不必去记住标准操作的各式名称(“怎么得到元素的总数?是
.size()还是.length()还是别的什么?”) - 可以更加方便地利用 Python 的标准库,比如
random.choice函数,从而不用重新发明轮子。
首先明确一点,特殊方法的存在是为了被 Python 解释器调用的,你自己并不需要调用它们。也就是说没有 my_object.__len__() 这种写法,而应该使用 len(my_object)。在执行 len(my_object) 的时候,如果 my_object 是一个自定义类的对象,那么 Python 会自己去调用其中由你实现的 __len__ 方法。
然而如果是 Python 内置的类型,比如列表(list)、字符串(str)、字节序列(bytearray)等,那么 CPython 会抄个近路,__len__ 实际上会直接返回 PyVarObject 里的 ob_size 属性。PyVarObject 是表示内存中长度可变的内置对象的 C 语言结构体。直接读取这个值比调用一个方法要快很多。
很多时候,特殊方法的调用是隐式的,比如 for i in x: 这个语句,背后其实用的是 iter(x),而这个函数的背后则是 x.__iter__() 方法。当然前提是这个方法在 x 中被实现了。
repr
Python 有一个内置的函数叫 repr,它能把一个对象用字符串的形式表达出来以便辨认,这就是 “字符串表示形式”。
repr 就是通过 __repr__ 这个特殊方法来得到一个对象的字符串表示形式的。如果没有实现 __repr__,当我们在控制台里打印一个向量的实例时,得到的字符串可能会是 <Vector object at 0x10e100070>。
__repr__ 和 __str__ 的区别在于,后者是在 str() 函数被使用,或是在用 print 函数打印一个对象的时候才被调用的,并且它返回的字符串对终端用户更友好。
如果你只想实现这两个特殊方法中的一个,__repr__ 是更好的选择,因为如果一个对象没有 __str__ 函数,而 Python 又需要调用它的时候,解释器会用 __repr__ 作为替代。前者方便我们调试和记录日志,后者则是给终端用户看的。
算术运算符
__add__ 和 __mul__ 这两个方法的返回值都是新创建的向量对象,被操作的两个向量(self 或 other)还是原封不动,代码里只是读取了它们的值而已。
中缀运算符的基本原则就是不改变操作对象,而是产出一个新的值
布尔值
尽管 Python 里有 bool 类型,但实际上任何对象都可以用于需要布尔值的上下文中(比如 if 或 while 语句,或者 and、or 和 not 运算符)。为了判定一个值 x 为真还是为假,Python 会调用 bool(x),这个函数只能返回 True 或者 False。
默认情况下,我们自己定义的类的实例总被认为是真的,除非这个类对 __bool__ 或者 __len__ 函数有自己的实现。bool(x) 的背后是调用 x.__bool__() 的结果;如果不存在 __bool__ 方法,那么 bool(x) 会尝试调用 x.__len__()。若返回 0,则 bool 会返回 False;否则返回 True。
特殊方法一览
Python 语言参考手册中的“Data Model”(https://docs.python.org/3/reference/datamodel.html)一章列出了 83 个特殊方法的名字,其中 47 个用于实现算术运算、位运算和比较操作。
跟运算符无关的特殊方法
| 类别 | 方法名 |
|---|---|
| 字符串 / 字节序列表示形式 | __repr__、__str__、__format__、__bytes__ |
| 数值转换 | __abs__、__bool__、__complex__、__int__、__float__、__hash__、__index__ |
| 集合模拟 | __len__、__getitem__、__setitem__、__delitem__、__contains__ |
| 迭代枚举 | __iter__、__reversed__、__next__ |
| 可调用模拟 | __call__ |
| 上下文管理 | __enter__、__exit__ |
| 实例创建和销毁 | __new__、__init__、__del__ |
| 属性管理 | __getattr__、__getattribute__、__setattr__、__delattr__、__dir__ |
| 属性描述符 | __get__、__set__、__delete__ |
| 跟类相关的服务 | __prepare__、__instancecheck__、__subclasscheck__ |
跟运算符相关的特殊方法
| 类别 | 方法名和对应的运算符 |
|---|---|
| 一元运算符 | __neg__ -、__pos__ +、__abs__ abs() |
| 众多比较运算符 | __lt__ <、__le__ <=、__eq__ ==、__ne__ !=、__gt__ >、__ge__ >= |
| 算术运算符 | __add__ +、__sub__ -、__mul__ *、__truediv__ /、__floordiv__ //、__mod__ %、__divmod__ divmod()、__pow__ ** 或 pow()、__round__ round() |
| 反向算术运算符 | __radd__、__rsub__、__rmul__、__rtruediv__、__rfloordiv__、__rmod__、__rdivmod__、__rpow__ |
| 增量赋值算术运算符 | __iadd__、__isub__、__imul__、__itruediv__、__ifloordiv__、__imod__、__ipow__ |
| 位运算符 | __invert__ ~、__lshift__ <<、__rshift__ >>、__and__ &、`or |
| 反向位运算符 | __rlshift__、__rrshift__、__rand__、__rxor__、__ror__ |
| 增量赋值位运算符 | __ilshift__、__irshift__、__iand__、__ixor__、__ior__ |
其他
- 对序列数据类型的模拟是特殊方法用得最多的地方
- 迭代通常是隐式的,譬如说一个集合类型没有实现
__contains__方法,那么in运算符就会按顺序做一次迭代搜索。
序列构成的数组
内置序列类型
按元素类型分
Python 标准库用 C 实现了丰富的序列类型,列举如下。
- 容器序列:
list、tuple和collections.deque这些序列能存放不同类型的数据。 - 扁平序列:
str、bytes、bytearray、memoryview和array.array,这类序列只能容纳一种类型。
✅ 容器序列存放的是它们所包含的任意类型的对象的引用,而扁平序列里存放的是值而不是引用。
换句话说,扁平序列其实是一段连续的内存空间。由此可见扁平序列其实更加紧凑,但是它里面只能存放诸如字符、字节和数值这种基础类型。
按能否被修改分
序列类型还能按照能否被修改来分类。
- 可变序列:
list、bytearray、array.array、collections.deque和memoryview。 - 不可变序列
tuple、str和bytes。
下图显示了可变序列(MutableSequence)和不可变序列(Sequence)的差异,同时也能看出前者从后者那里继承了一些方法。这个 UML 类图列举了 collections.abc 中的几个类(超类在左边,箭头从子类指向超类,斜体名称代表抽象类和抽象方法)

元组
除了用作不可变的列表,元组还可以用于没有字段名的记录。鉴于后者常常被忽略,我们先来看看元组作为记录的功用。
元组和记录
元组最大的特征是其不可变性。不可变性实际上暗含多种含义,其一是元组记录的值不会改变,其二是元组记录的值的顺序不会改变。第二条相当重要,但是常被忽略。有些时候单纯的数值没有意义,只有结合值与该值在序列中的位置才会有明确的意义(例如经纬度记录,抑或是按照一定顺序采集到的数据)。
拆包让元组可以完美地被当作记录来使用
元组拆包
拆包可以以多种方式进行:
- 平行赋值:对于一个可迭代对象,使用相同数量的变量接收其中的元素
*运算符拆包:*可以将一个可迭代对象拆包并作为传入函数的参数*运算符处理剩余元素:*除了可以拆包可迭代对象外,还可以用于接收不确定数量的拆包结果- 非常神奇的功能,类似于
*args。赋值表达式的左边最多只能由一个*,并且带有*运算符的变量总会自动接受合适数量的拆包结果
- 非常神奇的功能,类似于
| |
嵌套元组拆包
接受表达式的元组可以是嵌套式的,例如 (a, b, (c, d))。只要这个接受元组的嵌套结构符合表达式本身的嵌套结构,Python 就可以作出正确的对应。
| |
具名元组
有些情况下,我们希望元组能带有一个可以解释各位置数据的含义的字段。collections.namedtuple 即可实现这一功能
namedtuple实际上创建了一个类
用 namedtuple 构建的类的实例所消耗的内存跟元组是一样的,因为字段名都被存在对应的类里面。这个实例跟普通的对象实例比起来也要小一些,因为 Python 不会用 __dict__ 来存放这些实例的属性。
| |
使用 collections.namedtuple 创建的类的实例可以使用对应的字段名或者索引来获取对应的值。此外,还有如下常用功能:
._fields:返回包括所有字段名称的元组._make():接受一个可迭代对象以生成一个实例._asdict():将具名元组以collections.OrderedDict形式返回 ——[(key1, value1), (key2, value2), ...]
| |
切片
为什么切片和区间会忽略最后一个元素
- 当只有最后一个位置信息时,我们也可以快速看出切片和区间里有几个元素:
range(3)和my_list[:3]都返回 3 个元素。 - 当起止位置信息都可见时,我们可以快速计算出切片和区间的长度,用后一个数减去第一个下标(
stop - start)即可。 - 这样做也让我们可以利用任意一个下标来把序列分割成不重叠的两部分,只要写成
my_list[:x]和my_list[x:]就可以了
这些理由对我不是很有说服力……
具有名称标识的切片操作
| |
这个用法很实用,主要是能够对切片操作进行单独的定义。方便对不同的序列使用相同的切片操作进行切片。同样的,slice 对象也会忽略最后一个元素
| |
多维切片和省略
多维切片在处理实际数据时经常用到,例如处理图像数据或者更高维的数据。Python 内置的序列类型均是一维的,因此内置的序列类型仅支持一维的。
[] 运算符里还可以使用以逗号分开的多个索引或者是切片,外部库 NumPy 里就用到了这个特性,二维的 numpy.ndarray 就可以用 a[i, j] 这种形式来获取,抑或是用 a[m:n, k:l] 的方式来得到二维切片。
要正确处理这种 [] 运算符的话,对象的特殊方法 __getitem__ 和 __setitem__ 需要以元组的形式来接收 a[i, j] 中的索引。也就是说,如果要得到 a[i, j] 的值,Python 会调用 a.__getitem__((i, j))。
总的来说,若想实现多维切片,需要实现 __getitem__ 和 __setitem__ 。前者用于读取数据,后者用于赋值。
省略符号(…)则被用于省略无需额外指定的参数。例如,对于一个四维数组,若仅对第一维和最后一维进行切片,在 Numpy 可以写为:
| |
这些句法上的特性主要是为了支持用户自定义类或者扩展,比如 NumPy 就是个例子。
给切片赋值
若赋值的对象是一个切片,则赋值语句的右侧也必须是一个可迭代对象
但是在 Numpy 等库中,则可以直接用单个数值对切片进行赋值,这一操作主要依赖 Numpy 等库中的 broadcast 机制;基于 broadcast 机制,一些 shape 没有完全对应上的情况在 Numpy 中也可以进行赋值和运算
| |
✅ 一个有趣的极限情况
| |
上述操作按理来说应当是直接报错,因为元组中的元素不可赋值。但是实际情况是报错的同时,元组包含的列表被修改了。
对上述代码的字节码进行分析可以发现,顺序执行了下述三个操作
- 读取
test_tuple[2]并将其存入栈顶,记为TOS - 完成操作
TOS += [5, 6] - 将结果存入原位置:
test_tuple[2] = TOS
其中,第二步是对 list 进行的操作,由于 list 是可变序列因此该操作不会报错;第三步是对 tuple 进行的操作,由于 tuple 是不可变序列,当尝试赋值时会抛出错误。但是 tuple 中存放的是 list 的引用,因此此时 tuple 中的 list 实际上已经被修改。
上述结果反映:
- 将可变对象放置于不可变对象中是十分危险的操作
- 上述操作不是原子操作,因此发生了上述既完成了操作又抛出了错误的结果。
序列的增量赋值
+= 背后的特殊方法是 __iadd__ (用于“就地加法”)。但是如果一个类没有实现这个方法的话,Python 会退一步调用 __add__ 。考虑下面这个简单的表达式:
| |
如果 a 实现了 __iadd__ 方法,就会调用这个方法。同时对可变序列(例如 list、bytearray 和 array.array)来说,a 会就地改动,就像调用了 a.extend(b) 一样。但是如果 a 没有实现 __iadd__ 的话,a += b 这个表达式的效果就变得跟 a = a + b 一样了:首先计算 a + b,得到一个新的对象,然后赋值给 a。也就是说,在这个表达式中,变量名会不会被关联到新的对象,完全取决于这个类型有没有实现 __iadd__ 这个方法。
总体来讲,可变序列一般都实现了 __iadd__ 方法,因此 += 是就地加法。而不可变序列根本就不支持这个操作,对这个方法的实现也就无从谈起。
上面所说的这些关于
+=的概念也适用于*=,后者相对应的是__imul__。
接下来有个小例子,展示的是 *= 在可变和不可变序列上的作用:
| |
✅ 规律:
- 可变序列的增量赋值,id 不变
- 不可变序列的增量赋值,id 改变
对不可变序列进行重复拼接操作的话,效率会很低,因为每次都有一个新对象,而解释器需要把原来对象中的元素先复制到新的对象里,然后再追加新的元素。
str是一个例外,因为对字符串做+=实在是太普遍了,所以 CPython 对它做了优化。为str初始化内存的时候,程序会为它留出额外的可扩展空间,因此进行增量操作的时候,并不会涉及复制原有字符串到新位置这类操作。
有序序列的元素查找以及插入
bisect 模块提供了对有序序列进行元素查找以及插入的方法。
bisect.bisect可以用于元素插入位置查找:寻找一个位置,使得插入待插入元素后,有序序列仍是有序的。bisect.insort函数则直接将元素插入有序序列中。
bisect() 和 insort() 均有两种形式,分别被命名为 _right,_left。若遇到相等的元素,_right 会将元素插入到序列中相同值的元素的后面,而 _left 则会插入到前面。
bisect函数其实是bisect_right函数的别名
| |
| |
| |
insort 跟 bisect 一样,有 lo 和 hi 两个可选参数用来控制查找的范围。它也有个变体叫 insort_left,这个变体在背后用的是 bisect_left。
当列表不是首选时
虽然列表既灵活又简单,但面对各类需求时,我们可能会有更好的选择。
比如,要存放 1000 万个浮点数的话,数组(array)的效率要高得多,因为数组在背后存的并不是 float 对象,而是数字的机器翻译,也就是字节表述。这一点就跟 C 语言中的数组一样。
再比如说,如果需要频繁对序列做先进先出的操作,deque(双端队列)的速度应该会更快。
如果在你的代码里,包含操作(比如检查一个元素是否出现在一个集合中)的频率很高,用 set(集合)会更合适。set 专为检查元素是否存在做过优化。
数组
如果我们需要一个只包含数字的列表,那么 array.array 比 list 更高效。数组支持所有跟可变序列有关的操作,包括 .pop、.insert 和 .extend。另外,数组还提供从文件读取和存入文件的更快的方法,如 .frombytes 和 .tofile。
| |
| |
一个小试验告诉我,用 array.fromfile 从一个二进制文件里读出 1000 万个双精度浮点数只需要 0.1 秒,这比从文本文件里读取的速度要快 60 倍,因为后者会使用内置的 float 方法把每一行文字转换成浮点数。
另外,使用 array.tofile 写入到二进制文件,比以每行一个浮点数的方式把所有数字写入到文本文件要快 7 倍。另外,1000 万个这样的数在二进制文件里只占用 80 000 000 个字节(每个浮点数占用 8 个字节,不需要任何额外空间),如果是文本文件的话,我们需要 181 515 739 个字节。
内存视图
memoryview 是一个内置类,它能让用户在不复制内容的情况下操作同一个数组的不同切片。
实际上提供了一种在不需要赋值内容的前提下,实现不同数据结构之间的内存共享。即指定一块区域,能够使用不同的方式去存读数据,例如可以以 list 的形式创建一个序列,然后以 Numpy array 的形式去处理这个序列,而不需要额外再创建一个包含相同内容的新 array。
| |
双向队列
利用
.append和.pop方法,我们可以把列表当作栈或者队列来用(比如,把.append和.pop(0)合起来用,就能模拟栈的“先进先出”的特点)。但是删除列表的第一个元素(抑或是在第一个元素之前添加一个元素)之类的操作是很耗时的,因为这些操作会牵扯到移动列表里的所有元素。
collections.deque 类(双向队列)是一个线程安全、可以快速从两端添加或者删除元素的数据类型。
而且如果想要有一种数据类型来存放“最近用到的几个元素”,deque 也是一个很好的选择。
这是因为在新建一个双向队列的时候,你可以指定这个队列的大小,如果这个队列满员了,还可以从反向端删除过期的元素,然后在尾端添加新的元素。
| |
output
| |
双向队列实现了大部分列表所拥有的方法,也有一些额外的符合自身设计的方法,比如说 popleft 和 rotate。但是为了实现这些方法,双向队列也付出了一些代价,从队列中间删除元素的操作会慢一些,因为它只对在头尾的操作进行了优化。
append 和 popleft 都是原子操作,也就说是 deque 可以在多线程程序中安全地当作先进先出的栈使用,而使用者不需要担心资源锁的问题。
其他
对
seq[start:stop:step]进行求值的时候,Python 会调用seq.__getitem__(slice(start, stop, step))key参数能让你对一个混有数字字符和数值的列表进行排序。你只需要决定到底是把字符看作数值,还是把数值看作字符:1 2 3 4 5>>> l = [28, 14, '28', 5, '9', '1', 0, 6, '23', 19] >>> sorted(l, key=int) [0, '1', 5, 6, '9', 14, 19, '23', 28, '28'] >>> sorted(l, key=str) [0, '1', 14, 19, '23', 28, '28', 5, 6, '9']
字典和集合
字典这个数据结构活跃在所有 Python 程序的背后,即便你的源码里并没有直接用到它
跟字典有关的内置函数都在 __builtins__.__dict__ 模块中。
正是因为字典至关重要,Python 对它的实现做了高度优化,而散列表则是字典类型性能出众的根本原因。
泛映射(mapping)类型
字典属于泛映射类型数据结构,不同于序列类型,字典总是由 key-value(键值对)构成。
collections.abc 中定义了 Mapping 和 MutableMapping 两个抽象基类,这些基类为 dict 等数据结构定义了形式接口。

箭头由子类指向超类
这些基类主要是作为形式化的文档并定义里构建一个映射类型需要的最基本接口。使用 isinstance 就可以判断某一个对象是否是广义上的映射类型。
| |
可散列的数据类型
散列函数的使用能够更快速的访问某一特定关键字对应的数据。
如果一个对象是可散列的,那么在这个对象的生命周期中,它的散列值是不变的,而且这个对象需要实现 __hash__() 方法和 __qe__() 方法,这样才能跟其他键做比较。
如果两个可散列对象是相等的,那么它们的散列值一定是一样的。
原子不可变数据类型(str、bytes 和数值类型)都是可散列类型,frozenset 也是可散列的,因为根据其定义,frozenset 里只能容纳可散列类型。
元组的话,只有当一个元组包含的所有元素都是可散列类型的情况下,它才是可散列的。来看下面的元组 tt、tl 和 tf:
| |
一般来讲用户自定义的类型的对象都是可散列的,散列值就是它们的
id()函数的返回值,所以所有这些对象在比较的时候都是不相等的。如果一个对象实现了
__eq__方法,并且在方法中用到了这个对象的内部状态的话,那么只有当所有这些内部状态都是不可变的情况下,这个对象才是可散列的。
根据这些定义,字典提供了很多种构造方法,“Built-in Types”
| |
常见的映射方法
| dict | defaultdict | OrderedDict | ||
|---|---|---|---|---|
d.clear() | • | • | • | 移除所有元素 |
d.__contains__(k) | • | • | • | 检查 k 是否在 d 中 |
d.copy() | • | • | • | 浅复制 |
d.__copy__() | • | 用于支持 copy.copy | ||
d.default_factory | • | 在 __missing__ 函数中被调用的函数,用以给未找到的元素设置值 * | ||
d.__delitem__(k) | • | • | • | del d[k],移除键为 k 的元素 |
d.fromkeys(it, [initial]) | • | • | • | 将迭代器 it 里的元素设置为映射里的键,如果有 initial 参数,就把它作为这些键对应的值(默认是 None) |
d.get(k, [default]) | • | • | • | 返回键 k 对应的值,如果字典里没有键 k,则返回 None 或者 default |
d.__getitem__(k) | • | • | • | 让字典 d 能用 d[k] 的形式返回键 k 对应的值 |
d.items() | • | • | • | 返回 d 里所有的键值对 |
d.__iter__() | • | • | • | 获取键的迭代器 |
d.keys() | • | • | • | 获取所有的键 |
d.__len__() | • | • | • | 可以用 len(d) 的形式得到字典里键值对的数量 |
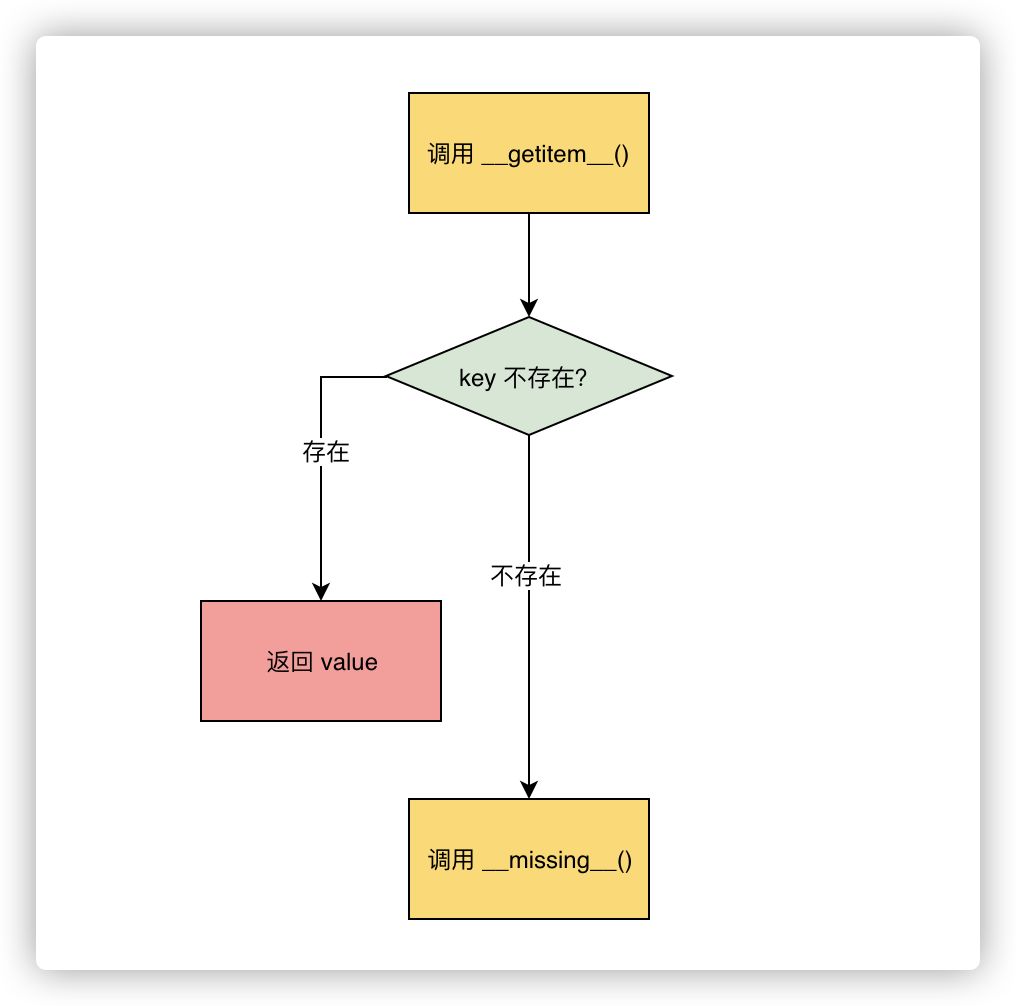
d.__missing__(k) | • | 当 __getitem__ 找不到对应键的时候,这个方法会被调用 | ||
d.move_to_end(k, [last]) | • | 把键为 k 的元素移动到最靠前或者最靠后的位置(last 的默认值是 True) | ||
d.pop(k, [defaul] | • | • | • | 返回键 k 所对应的值,然后移除这个键值对。如果没有这个键,返回 None 或者 defaul |
d.popitem() | • | • | • | 随机返回一个键值对并从字典里移除它# |
d.__reversed__() | • | 返回倒序的键的迭代器 | ||
d.setdefault(k, [default]) | • | • | • | 若字典里有键 k,则把它对应的值设置为 default,然后返回这个值;若无,则让 d[k] = default,然后返回 default |
d.__setitem__(k, v) | • | • | • | 实现 d[k] = v 操作,把 k 对应的值设为 v |
d.update(m, [**kargs]) | • | • | • | m 可以是映射或者键值对迭代器,用来更新 d 里对应的条目 |
d.values() | • | • | • | 返回字典里的所有值 |
映射的弹性键查询
get() & setdefault()
get() 能够规避对 dict 中某一个 key 赋值时,由于 key 不存在于 dict 中导致的 keyError。但是利用 get() 方法处理这种情况需要经过多次键查询操作(get() 是一次,然后赋值又是一次,并且还需要创建临时变量用于存放取得的值以及对值的操作)
setdefault() 则可以一步完成上述工作
| |
但有时候为了方便起见,就算某个键在映射里不存在,我们也希望在通过这个键读取值的时候能得到一个默认值。有两个途径能帮我们达到这个目的:
- 一个是通过
defaultdict这个类型而不是普通的dict - 另一个是给自己定义一个
dict的子类,然后在子类中实现__missing__方法。
下面将介绍这两种方法。
defaultdict
有些时候,希望某个键不存在于映射中也会返回一个默认值,collections.defaultdict 实现了 __missing__ 方法,用于应对这种需求。
defaultdict 会按照如下步骤处理映射类型中不存在的键
- 调用定义时指定的方法,创建一个新的对象(例如,若默认创建一个列表类型,则会调用
list()方法创建一个新 list) - 将新对象作为值,构建键值对并记录到原字典中
- 返回新创建的键值对的值的引用
| |
defaultdict 依赖 default_factory 方法实现上述操作,值得注意的是,defaultfactory 仅会在 __getitem__ 中被调用,对于一个不存在于字典中的键 “new_key”,若直接用 get() 函数获取其对应的值则会返回 None。
__getitem__ 并不会直接调用 default_factory,而是按照如下流程进行调用:
- 执行
defaultdict["new_key"],希望获得 “new_key” 对应的值 - 调用
__getitem__()方法,结果没有在键列表中查询到 “new_key” - 调用
__missing__()方法,处理未知键 “new_key” - 调用
default_factory()方法,赋予 “new_key” 默认值
上述流程中最为关键的是 __missing__() 方法的实现。它会在 defaultdict 遇到找不到的键的时候调用 default_factory。
自定义 __missing__
实际上,对于自定义的映射数据类型,若想处理未知键的查询和创建任务,也仅需要实现 __missing__() 方法就好。
| |
如果要自定义一个映射类型,更合适的策略其实是继承
collections.UserDict类(示例 3-8 就是如此)。这里我们从dict继承,只是为了演示__missing__是如何被dict.__getitem__调用的。
字典的变种
dict 类型是最常用的映射类型,defaultdict 和 OrderedDict 则是 dict 的变种,这两个类型支持一些特殊的用法。此外还有如 ChainMap(可容纳多个映射对象并在进行键查找时,在所有的映射对象中进行查找)、Counter(具有计数器功能,相当适用于计数任务)、UserDict(开箱即用的自定义映射类型基类)等
总的来说,这些变种均具有 dict 具有的功能,此外还为了应对不同的应用场合提供了更为丰富的功能。
collections.defaultdict
defaultdict 对未知键提供了特殊支持,当传入字典中不存在的键获取数据时,dict 会直接报错,而 defaultdict 则会默认为这个新键创建对应的键值对(在建立字典的时候非常非常非常好用,之前都是首先用 if 判断字典中是否存在该键,然后根据判断结果创建或者修改键值对)
collections.OrderedDict
OrderedDict 则对顺序提供了额外支持,普通的 dict 并不会记录键值对的顺序,或者说 dict 中的键值对都是无序的,但是 OrderedDict 则提供了额外的键值对顺序功能支持,支持类似于先入先出的功能。
OrderedDict 的 popitem 方法默认删除并返回的是字典里的最后一个元素,但是如果像 my_odict.popitem(last=False) 这样调用它,那么它删除并返回第一个被添加进去的元素。
collections.ChainMap
详见 https://www.cnblogs.com/mangmangbiluo/p/9882097.html
该类型可以容纳数个不同的映射对象,然后在进行键查找操作的时候,这些对象会被当作一个整体被逐个查找,直到键被找到为止。这个功能在给有嵌套作用域的语言做解释器的时候很有用,可以用一个映射对象来代表一个作用域的上下文。
| |
这是 ChainMap 最基本的使用,可以用来合并两个或者更多个字典,当查询的时候,从前往后依次查询。
从原理上面讲,ChainMap 实际上是把放入的字典存储在一个队列中,当进行字典的增加删除等操作只会在第一个字典上进行,当进行查找的时候会依次查找
有一个注意点就是当对 ChainMap 进行修改的时候总是只会对第一个字典进行修改
| |
collections.Counter
这个映射类型会给键准备一个整数计数器。每次更新一个键的时候都会增加这个计数器。
所以这个类型可以用来给可散列表对象计数,或者是当成多重集来用——多重集合就是集合里的元素可以出现不止一次。
Counter 实现了 + 和 - 运算符用来合并记录,还有像 most_common([n]) 这类很有用的方法。most_common([n]) 会按照次序返回映射里最常见的 n 个键和它们的计数
下面的小例子利用 Counter 来计算单词中各个字母出现的次数:
| |
UserDict
这个类其实就是把标准 dict 用纯 Python 又实现了一遍。
跟 OrderedDict、ChainMap 和 Counter 这些开箱即用的类型不同,UserDict 是让用户继承写子类的。
子类化 UserDict
而更倾向于从 UserDict 而不是从 dict 继承的主要原因是,后者有时会在某些方法的实现上走一些捷径,导致我们不得不在它的子类中重写这些方法,但是 UserDict 就不会带来这些问题
另外一个值得注意的地方是,UserDict 并不是 dict 的子类,但是 UserDict 有一个叫作 data 的属性,是 dict 的实例,这个属性实际上是 UserDict 最终存储数据的地方。这样做的好处是,比起示例 3-7,UserDict 的子类就能在实现 __setitem__ 的时候避免不必要的递归,也可以让 __contains__ 里的代码更简洁。
| |
不可变的映射类型
从 Python 3.3 开始,types 模块中引入了一个封装类名叫 MappingProxyType。如果给这个类一个映射,它会返回一个只读的映射视图。
虽然是个只读视图,但是它是动态的。这意味着如果对原映射做出了改动,我们通过这个视图可以观察到,但是无法通过这个视图对原映射做出修改。
| |
集合
集合在 Python 中是一个较新的概念,其描述了唯一对象的集合。集合有如下特点:
- 元素的唯一性:集合中不会有两个一样的对象(这里的唯一性指的是 hash 的唯一性)
- 集合中的元素必须是可散列的,但是**
set本身是不可散列的**,set类型本身是不可散列的,但是frozenset可以。因此可以创建一个包含不同frozenset的set。 - 集合允许各种基于集合的二元运算,例如交集、并集以及差集
a | b返回的是它们的合集,a & b得到的是交集,而a - b得到的是差集。
集合的字面量
| |
像 {1, 2, 3} 这种字面量句法相比于构造方法(set([1, 2, 3]))要更快且更易读。后者的速度要慢一些,因为 Python 必须先从 set 这个名字来查询构造方法,然后新建一个列表,最后再把这个列表传入到构造方法里。但是如果是像 {1, 2, 3} 这样的字面量,Python 会利用一个专门的叫作 BUILD_SET 的字节码来创建集合。
用 dis.dis(反汇编函数)来看看两个方法的字节码的不同:
| |
➊ 检查 {1} 字面量背后的字节码。
➋ 特殊的字节码 BUILD_SET 几乎完成了所有的工作。
➌ set([1]) 的字节码。
➍ 3 种不同的操作代替了上面的 BUILD_SET:LOAD_NAME、BUILD_LIST 和 CALL_FUNCTION。
集合推导
| |
dict 和 set 的背后
散列表其实是一个稀疏数组(总是有空白元素的数组称为稀疏数组)。在一般的数据结构教材中,散列表里的单元通常叫作表元(bucket)。在 dict 的散列表当中,每个键值对都占用一个表元,每个表元都有两个部分,一个是对键的引用,另一个是对值的引用。因为所有表元的大小一致,所以可以通过偏移量来读取某个表元。
因为 Python 会设法保证大概还有三分之一的表元是空的,所以在快要达到这个阈值的时候,原有的散列表会被复制到一个更大的空间里面。
如果要把一个对象放入散列表,那么首先要计算这个元素键的散列值。Python 中可以用 hash() 方法来做这件事情。
散列值和相等性
内置的 hash() 方法可以用于所有的内置类型对象。如果是自定义对象调用 hash() 的话,实际上运行的是自定义的 __hash__。
如果两个对象在比较的时候是相等的,那它们的散列值必须相等,否则散列表就不能正常运行了。例如,如果 1 == 1.0 为真,那么 hash(1) == hash(1.0) 也必须为真,但其实这两个数字(整型和浮点)的内部结构是完全不一样的
为了让散列值能够胜任散列表索引这一角色,它们必须在索引空间中尽量分散开来。这意味着在最理想的状况下,越是相似但不相等的对象,它们散列值的差别应该越大。
总结一下,一个可散列的对象必须满足以下要求。
- 支持
hash()函数,并且通过__hash__()方法所得到的散列值是不变的。 - 支持通过
__eq__()方法来检测相等性。 - 若
a == b为真,则hash(a) == hash(b)也为真。
所有由用户自定义的对象默认都是可散列的,因为它们的散列值由 id() 来获取,而且它们都是不相等的
如果你实现了一个类的
__eq__方法,并且希望它是可散列的,那么它一定要有个恰当的__hash__方法,保证在a == b为真的情况下hash(a) == hash(b)也必定为真。否则就会破坏恒定的散列表算法,导致由这些对象所组成的字典和集合完全失去可靠性,这个后果是非常可怕的。另一方面,如果一个含有自定义的
__eq__依赖的类处于可变的状态,那就不要在这个类中实现__hash__方法,因为它的实例是不可散列的。
一个例子
在 32 位的 Python 中,1、1.0001、1.0002 和 1.0003 这几个数的散列值的二进制表达对比(上下两个二进制间不同的位被 ! 高亮出来,表格的最右列显示了有多少位不相同)
| |
从 Python 3.3 开始,
str、bytes和datetime对象的散列值计算过程中多了随机的“加盐”这一步。所加盐值是 Python 进程内的一个常量,但是每次启动 Python 解释器都会生成一个不同的盐值。随机盐值的加入是为了防止 DOS 攻击而采取的一种安全措施。
散列表算法
为了获取 my_dict[search_key] 背后的值,Python 首先会调用 hash(search_key) 来计算 search_key 的散列值,把这个值最低的几位数字当作偏移量,在散列表里查找表元(具体取几位,得看当前散列表的大小)。若找到的表元是空的,则抛出 KeyError 异常。若不是空的,则表元里会有一对 found_key:found_value。这时候 Python 会检验 search_key == found_key 是否为真,如果它们相等的话,就会返回 found_value。
如果 search_key 和 found_key 不匹配的话,这种情况称为散列冲突。发生这种情况是因为,散列表所做的其实是把随机的元素映射到只有几位的数字上,而散列表本身的索引又只依赖于这个数字的一部分。为了解决散列冲突,算法会在散列值中另外再取几位,然后用特殊的方法处理一下,把新得到的数字再当作索引来寻找表元;若这次找到的表元是空的,则同样抛出 KeyError;若非空,或者键匹配,则返回这个值;或者又发现了散列冲突,则重复以上的步骤。
总结一下:
- 计算键的散列值
- 使用散列值的一部分来定位散列表中的一个表元
- 判断表元是否为空
- 若为空,抛出 KeyError
- 若不为空,执行第 4 步
- 检查是否是期望的元素
- 若是期望的元素,返回表元中的值
- 若不是期望的元素,执行第 5 步
- 发生冲突,使用散列值的另一部分来定位散列表中的另一行,并返回第 3 步
添加新元素和更新现有键值的操作几乎跟查找一样。只不过对于前者,在发现空表元的时候会放入一个新元素;对于后者,在找到相对应的表元后,原表里的值对象会被替换成新值。。此外,为了保证散列表的稀疏性,当元素数量增添到一定阈值时,Python 会自动将这个散列表复制到更大的空间中以避免冲突。
一些特点
字典在内存上的开销巨大
由于字典使用了散列表,而散列表又必须是稀疏的,这导致它在空间上的效率低下。
举例而言,如果你需要存放数量巨大的记录,那么放在由元组或是具名元组构成的列表中会是比较好的选择;最好不要根据 JSON 的风格,然后用字典组成的列表来存放这些记录。
用元组取代字典就能节省空间的原因有两个:其一是避免了散列表所耗费的空间,其二是无需把记录中字段的名字在每个元素里都存一遍。
在用户自定义的类型中,
__slots__属性可以改变实例属性的存储方式,由dict变成tuple
总结
- 正是由于 dict 和 set 使用散列表来进行数据存储,在进行元素查找时不需要对所有元素进行遍历,这使得搜索特定元素的效率大大提高。
- 并且由于稀疏性,查找时间不会随着 dict 和 set 中元素数量的增加而线性增长。
- 由于使用散列表进行存储,dict 和 set 中的元素也没有固定的顺序,在添加新元素时原有的顺序可能会被改变
- dict 和 set 使用散列表进行数据存储,因此这两个数据类型要求元素时可散列的。
- 即,在 Python 中某元素必须支持
__hash__()函数,并且通过__hash__()函数取得的散列值在生命周期中不发生变化。 - 此外,Python 还要求可散列的元素支持
__eq__()方法以判断相等性。这些条件使得不是所有的对象均可以作为 dict 的键或者 set 的元素。
- 即,在 Python 中某元素必须支持
- 与 2 类似,由于添加元素后很可能改变原有的顺序,因此在 dict 和 set 中讨论元素的顺序没有意义,除非使用类似于 OrderedDict 这样的特殊类型。
- 由于元素的顺序不确定,在循环迭代 dict 或者 set 的同时删增元素可能会导致跳过某些元素。
- 若使用
.keys()、.values()以及.items()等函数对 dict 进行循环迭代,Python3 中这些方法返回的字典视图具有动态的特性。即,循环迭代过程中对 dict 的改变会实时反馈到循环条件上,这显然会导致不可预测的错误。
- 若使用
- dict 和 set 是空间换时间的典型例子。散列表需要保证稀疏性以尽可能避免冲突
- 因此,相较于 list,dict 和 set 需要维护更大的内存空间以保证散列表的稀疏性
其他
- 像
k in my_dict.keys()这种操作在 Python 3 中是很快的,而且即便映射类型对象很庞大也没关系。这是因为dict.keys()的返回值是一个 “视图”。- 视图就像一个集合,而且跟字典类似的是,在视图里查找一个元素的速度很快。Python 2 的
dict.keys()返回的是个列表,因此虽然上面的方法仍然是正确的,它在处理体积大的对象的时候效率不会太高,因为k in my_list操作需要扫描整个列表。
- 视图就像一个集合,而且跟字典类似的是,在视图里查找一个元素的速度很快。Python 2 的
- CPython 的实现细节里有一条是:如果有一个整型对象,而且它能被存进一个机器字中,那么它的散列值就是它本身的值
- 在散列冲突的情况下,用 C 语言写的用来打乱散列值位的算法的名字很有意思,叫
perturb。详见 CPython 源码里的dictobject.c(https://hg.python.org/cpython/file/tip/Objects/dictobject.c) - PHP 和 Ruby 的散列语法借鉴了 Perl,它们都用
=>作为键和值的连接。JavaScript 则从 Python 那儿偷师,使用了:。而 JSON 又从 JavaScript 发展而来,它的语法正好是 Python 句法的子集。因此,除了在true、false和null这几个值的拼写上有出入之外,JSON 和 Python 是完全兼容的。于是,现在大家用来交换数据的格式全是 Python 的dict和list。
文本和字节序列
本章将要讨论 Unicode 字符串、二进制序列,以及在二者之间转换时使用的编码
字符问题
字符串即字符的序列,重点是“字符”如何定义。
对于 Python,“字符” 即 Unicode 字符。字符的相关操作涉及到两个问题:
- 字符的标识,即码位,是特定字符在字符集中的唯一标识。
- 码位是 0~1 114 111 的数字(十进制),在 Unicode 标准中以 4~6 个十六进制数字表示,而且加前缀“U+”。例如,字母 A 的码位是 U+0041,欧元符号的码位是 U+20AC,高音谱号的码位是 U+1D11E。
- 字符的字节表述,是字符的具体表述,通过特定的编码算法连接字符和对应的字节表述。
- 在 UTF-8 编码中,A(U+0041)的码位编码成单个字节
\x41,而在 UTF-16LE 编码中编码成两个字节\x41\x00。再举个例子,欧元符号(U+20AC)在 UTF-8 编码中是三个字节——\xe2\x82\xac,而在 UTF-16LE 中编码成两个字节:\xac\x20。
- 在 UTF-8 编码中,A(U+0041)的码位编码成单个字节
编码:将码位转换为字节序列的过程
解码:将字节序列转换为码位的过程
Python 对字符和字节进行了完全的区分,具体来说,所有的字节序列的字面量均会以特定标识开头。下述为编 / 解码的一个示例
| |
Python 3 的
str类型基本相当于 Python 2 的unicode类型Python 3 的
bytes类型基本相当于 Python2 的str类型
字符串比较关键的问题是字符的编码算法以及文本文件的处理。前者涉及到的问题众多,而且相关的乱码问题时不时会出现,例如 matplotlib 的中文支持问题,后者则在读写文件时时常会遇到。
字节概要
bytes 是一种不可变数据类型,其元素是 0~255 之间的整数,并且 bytes 类型数据的切片依然是 bytes 类型。
bytearray 类型和 bytes 类型密切相关,bytearray 没有自己的字面量语法,但是和 bytes 类型的行为一致,其切片依然是 bytearray 类型。
| |
my_bytes[0]获取的是一个整数,而my_bytes[:1]返回的是一个长度为 1 的bytes对象——这一点应该不会让人意外。s[0] == s[:1]只对str这个序列类型成立。不过,
str类型的这个行为十分罕见。对其他各个序列类型来说,s[i]返回一个元素,而s[i:i+1]返回一个相同类型的序列,里面是s[i]元素。
字节的字面量表示
虽然二进制序列其实是整数序列,但是它们的字面量表示法表明其中有 ASCII 文本。因此,各个字节的值可能会使用下列三种不同的方式显示。
- 可打印的 ASCII 范围内的字节(从空格到
~),使用 ASCII 字符本身。 - 制表符、换行符、回车符和
\对应的字节,使用转义序列\t、\n、\r和\\。 - 其他字节的值,使用十六进制转义序列(例如,
\x00是空字节)。
因此,在上面的代码中 5,我们看到的是 b'caf\xc3\xa9':前 3 个字节 b'caf' 在可打印的 ASCII 范围内,后两个字节则不然。
编解码器
Python 自带了相当数量的编解码器,常用的例如 utf-8、gbk 等
| |
编解码问题会导致一些异常的抛出:
- UnicodeEncodeError:str 转 bytes 时
- UnicodeDecodeError:bytes 转 str 时
- SyntaxError:源码的编码错误
处理文本文件
处理文本的最佳实践是 “Unicode 三明治”
- 要尽早把输入(例如读取文件时)的字节序列解码成字符串。
- 这种三明治中的“肉片”是程序的业务逻辑,在这里只能处理字符串对象。在其他处理过程中,一定不能编码或解码。
- 对输出来说,则要尽量晚地把字符串编码成字节序列。

在 Python 3 中能轻松地采纳 Unicode 三明治的建议,因为内置的 open 函数会在读取文件时做必要的解码,以文本模式写入文件时还会做必要的编码,所以调用 my_file.read() 方法得到的以及传给 my_file.write(text) 方法的都是字符串对象
为了正确比较而规范化 Unicode 字符串
因为 Unicode 有组合字符(变音符号和附加到前一个字符上的记号,打印时作为一个整体),所以字符串比较起来很复杂。
例如,“café” 这个词可以使用两种方式构成,分别有 4 个和 5 个码位,但是结果完全一样:
| |
U+0301 是 COMBINING ACUTE ACCENT,加在“e”后面得到“é”。在 Unicode 标准中,'é' 和 'e\u0301' 这样的序列叫“标准等价物”(canonical equivalent),应用程序应该把它们视作相同的字符。但是,Python 看到的是不同的码位序列,因此判定二者不相等。
这个问题的解决方案是使用 unicodedata.normalize 函数提供的 Unicode 规范化。这个函数的第一个参数是这 4 个字符串中的一个:'NFC'、'NFD'、'NFKC' 和 'NFKD'。
- NFC:使用最少码位构成等价字符串
- NFD:将所有的组合字符解析为基字符和单独的组合字符
- NFKC:基本上就是 NFC 的兼容模式,添加了对兼容字符的处理
- NFKD:基本上就是 NFD 的兼容模式,添加了对兼容字符的处理
| |
保存文本之前,最好使用
normalize('NFC', user_text)清洗字符串。NFC 也是 W3C 的 “Character Model for the World Wide Web: String Matching and Searching” 规范推荐的规范化形式。
使用 NFC 时,有些单字符会被规范成另一个单字符。例如,电阻的单位欧姆(Ω)会被规范成希腊字母大写的欧米加。这两个字符在视觉上是一样的,但是比较时并不相等,因此要规范化,防止出现意外:
| |
下面是 NFKC 的具体应用:
| |
使用 '1/2' 替代 '½' 可以接受,微符号也确实是小写的希腊字母 'µ',但是把 '4²' 转换成 '42' 就改变原意了。某些应用程序可以把 '4²' 保存为 '4<sup>2</sup>',但是 normalize 函数对格式一无所知。
因此,NFKC 或 NFKD 可能会损失或曲解信息,但是可以使用 NFKC 和 NFKD 规范化形式时要小心,而且只能在特殊情况中使用,例如搜索和索引,而不能用于持久存储,因为这两种转换会导致数据损失。:用户搜索 '1 / 2 inch' 时,如果还能找到包含 '½ inch' 的文档,那么用户会感到满意。
使用 NFKC 和 NFKD 规范化形式时要小心,而且只能在特殊情况中使用,例如搜索和索引,而不能用于持久存储,因为这两种转换会导致数据损失。
大小写折叠
除了组合字符以及兼容字符外,字母的大小写也是一些语言中非常重要的处理对象。对此,显然最常见的方法是 str.lower(),此外,还有 str.casefold(),即大小写折叠。
这两个函数对绝大多数字符来说是等价的,但是对于极少数的特殊字符会得到不同的结果(自 Python3.4 起,有 116 个字符的处理结果不一致)
这是一个规范化字符串匹配函数的示例:
| |
除了 Unicode 规范化和大小写折叠(二者都是 Unicode 标准的一部分)之外,有时需要进行更为深入的转换,例如把 'café' 变成 'cafe'。下一节说明何时以及如何进行这种转换。
极端“规范化”:去掉变音符号
去掉变音符号不是正确的规范化方式,因为这往往会改变词的意思,而且可能误判搜索结果,但是在搜索领域往往需要这么做。
除了搜索,去掉变音符号还能让 URL 更易于阅读,至少对拉丁语系语言是如此。下面是维基百科中介绍圣保罗市(São Paulo)的文章的 URL:
| |
其中,“%C3%A3” 是 UTF-8 编码 “ã” 字母(带有波形符的 “a”)转义后得到的结果。下述形式更友好,尽管拼写是错误的:
| |
这里提供一个去除变音符号的算法。具体而言,首先将所有的组合字符解析为基字符和组合字符(NFD 格式),然后滤除所有的组合字符,最后进行重组即可(NFC 格式)
| |
更进一步地,只把拉丁基字符中所有的变音符号删除
| |
一等函数
不管别人怎么说或怎么想,我从未觉得 Python 受到来自函数式语言的太多影响。我非常熟悉命令式语言,如 C 和 Algol 68,虽然我把函数定为一等对象,但是我并不把 Python 当作函数式编程语言。
——Guido van Rossum,Python 仁慈的独裁者
把函数作为对象
在 Python 中,函数是一等对象。编程语言理论家把“一等对象”定义为满足下述条件的程序实体:
- 在运行时创建
- 能赋值给变量或数据结构中的元素
- 能作为参数传给函数
- 能作为函数的返回结果
在 Python 中,整数、字符串和字典都是一等对象——没什么特别的。
| |
高阶函数
接受函数为参数,或者把函数作为结果返回的函数是高阶函数(higher-order function)
在函数式编程范式中,最为人熟知的高阶函数有 map、filter、reduce
map、filter 和 reduce 的现代替代品
列表推导或生成器表达式具有 map 和 filter 两个函数的功能,而且更易于阅读
| |
匿名函数
为了使用高阶函数,有时创建一次性的小型函数会更便利,这便是匿名函数存在的原因。
lambda 关键字在 Python 表达式内创建匿名函数。
然而,Python 简单的句法限制了 lambda 函数的定义体只能使用纯表达式。换句话说,lambda 函数的定义体中不能赋值,也不能使用 while 和 try 等 Python 语句。
| |
除了作为参数传给高阶函数之外,Python 很少使用匿名函数。由于句法上的限制,非平凡的 lambda 表达式要么难以阅读,要么无法写出。
可调用对象
除了用户定义的函数,调用运算符(即 ())还可以应用到其他对象上。如果想判断对象能否调用,可以使用内置的 callable() 函数。
| |
Python 数据模型文档列出了 7 种可调用对象。
- 自定义的函数
- 内置函数
- 使用 C 语言(CPython)实现的函数,如
len或time.strftime
- 使用 C 语言(CPython)实现的函数,如
- 内置方法
- 使用 C 语言实现的方法,如
dict.get
- 使用 C 语言实现的方法,如
- 方法
- 类(创建实例时)
- 调用类时会运行类的
__new__方法创建一个实例,然后运行__init__方法,初始化实例,最后把实例返回给调用方。因为 Python 没有new运算符,所以调用类相当于调用函数。
- 调用类时会运行类的
- 类的实例(要求实现
__call__方法) - 生成器函数(yield)
__call__
下面的示例实现了 BingoCage 类。这个类的实例使用任何可迭代对象构建,而且会在内部存储一个随机顺序排列的列表。调用实例会取出一个元素。
| |
| |
实现 __call__ 方法的类是创建函数类对象的简便方式,此时必须在内部维护一个状态,让它在调用之间可用,例如 BingoCage 中的剩余元素。装饰器就是这样。装饰器必须是函数,而且有时要在多次调用之间“记住”某些事 (例如备忘(memoization),即缓存消耗大的计算结果,供后面使用)。
另一种对 __call__ 的解释
该方法的功能类似于在类中重载 () 运算符,使得类实例对象可以像调用普通函数那样,以 对象名() 的形式使用。
函数内省
同样的,Python 的函数也可以被视为对象。 函数有很多属性,这一特点使得函数表现得像一个对象。通过函数内省 dir() 能够得到这些属性的列表。
| |
其中大多数属性是 Python 对象共有的
下面的示例列出了常规对象没有而函数有的属性
| |
| 名称 | 类型 | 说明 |
|---|---|---|
__annotations__ | dict | 参数和返回值的注解 |
__call__ | method-wrapper | 实现 () 运算符;即可调用对象协议 |
__closure__ | tuple | 函数闭包,即自由变量的绑定(通常是 None) |
__code__ | code | 编译成字节码的函数元数据和函数定义体 |
__defaults__ | tuple | 形式参数的默认值 |
__get__ | method-wrapper | 实现只读描述符协议(参见第 20 章) |
__globals__ | dict | 函数所在模块中的全局变量 |
__kwdefaults__ | dict | 仅限关键字形式参数的默认值 |
__name__ | str | 函数名称 |
__qualname__ | str | 函数的限定名称,如 Random.choice |
定位参数与仅限关键字参数
两类实参:
- 位置参数 (positional):传参时前面不带 " 变量名 =",顺序不可变,按顺序赋给相应的局部变量.
- 关键字参数 (keyword):传参时前面加上 " 变量名=",顺序可变,按名称赋给同名的局部变量.
Python 最好的特性之一是提供了极为灵活的参数处理机制
仅限关键字参数 (keyword-only) 是 Python 3 新增的特性,它是在 * 后面定义的参数(或在 *args 后面定义),传参时必需带变量名
下面示例中的 tag 函数用于生成 HTML 标签;使用名为 cls 的关键字参数传入 “class” 属性,这是一种变通方法,因为 “class” 是 Python 的关键字
| |
| |
在上面的示例中,cls 参数只能通过关键字参数指定,它一定不会捕获未命名的定位参数。
定义函数时若想指定仅限关键字参数,要把它们放到前面有 * 的参数后面。如果不想支持数量不定的定位参数,但是想支持仅限关键字参数,在签名中放一个 *,如下所示:
| |
获取关于参数的信息
使用内置方法
Python 的函数有大量可用于获取函数参数信息的内置方法:
.__defaults__: 获取参数的默认值.__code__.co_varnames: 参数名称,包括函数中创建的临时变量.__code__.co_argcount: 参数总数
| |
| |
上述方法能够获取函数参数信息,但是不易处理和后续分析
- 参数名称在
__code__.co_varnames中,不过里面还有函数定义体中创建的局部变量。 - 因此,参数名称是前 N 个字符串,N 的值由
__code__.co_argcount确定。- 顺便说一下,这里不包含前缀为
*或**的变长参数。
- 顺便说一下,这里不包含前缀为
- 参数的默认值只能通过它们在
__defaults__元组中的位置确定,因此要从后向前扫描才能把参数和默认值对应起来。- 在这个示例中
clip函数有两个参数,text和max_len,其中一个有默认值,即80,因此它必然属于最后一个参数,即max_len。这有违常理。
- 在这个示例中
inspect 模块则提供了快速分析函数参数的功能
使用 inspect
inspect.signature 函数返回一个 inspect.Signature 对象,它有一个 parameters 属性,这是一个有序映射,把参数名和 inspect.Parameter 对象对应起来。各个 Parameter 属性也有自己的属性,例如 name、default 和 kind。特殊的 inspect._empty 值表示没有默认值,考虑到 None 是有效的默认值(也经常这么做),而且这么做是合理的:
| |
kind 属性的值是 _ParameterKind 类中的 5 个值之一,列举如下。
- POSITIONAL_OR_KEYWORD
- 可以通过定位参数和关键字参数传入的形参(多数 Python 函数的参数属于此类)。
- VAR_POSITIONAL
- 定位参数元组。
- VAR_KEYWORD
- 关键字参数字典。
- KEYWORD_ONLY
- 仅限关键字参数(Python 3 新增)。
- POSITIONAL_ONLY
- 仅限定位参数;目前,Python 声明函数的句法不支持,但是有些使用 C 语言实现且不接受关键字参数的函数(如
divmod)支持。
- 仅限定位参数;目前,Python 声明函数的句法不支持,但是有些使用 C 语言实现且不接受关键字参数的函数(如
inspect.Signature 对象有个 bind 方法,它可以把任意个参数绑定到签名中的形参上,所用的规则与实参到形参的匹配方式一样。框架可以使用这个方法在真正调用函数前验证参数
| |
函数注解
Python 允许对函数的形参以及函数本身进行注释。例如标注某一参数的类型为 “int” 或者 “str”。
| |
注解中最常用的类型是类(如 str 或 int)和字符串(如 'int > 0')。在上面的示例中,max_len 参数的注解用的是字符串。
Python 不会对这些注释进行任何处理,不会根据注释对参数进行检查、强制处理或者验证,仅是存储到 __annotations__ 属性中,以供 IDE(例如为 IDE 的静态类型检查功能提供信息)、框架和装饰器使用。
| |
支持函数式编程的包
虽然 Guido 明确表明,Python 的目标不是变成函数式编程语言,但是得益于 operator 和 functools 等包的支持,函数式编程风格也可以信手拈来
operator 模块
在函数式编程中,经常需要把算术运算符当作函数使用。例如,不使用递归计算阶乘。求和可以使用 sum 函数,但是求积则没有这样的函数。我们可以使用 reduce 函数,但是需要一个函数计算序列中两个元素之积:
| |
operator 模块为多个算术运算符提供了对应的函数,从而避免编写 lambda a, b: a*b 这种平凡的匿名函数。
| |
operator 模块中还有一类函数,能替代从序列中取出元素或读取对象属性的 lambda 表达式:因此,itemgetter 和 attrgetter 其实会自行构建函数。
itemgetter
itemgetter 的常见用途:根据元组的某个字段给元组列表排序。
下面的示例使用了 itemgetter 排序一个元组列表
| |
如果把多个参数传给 itemgetter,它构建的函数会返回提取的值构成的元组:
| |
itemgetter使用[]运算符,因此它不仅支持序列,还支持映射和任何实现__getitem__方法的类
attrgetter
attrgetter 与 itemgetter 作用类似,它创建的函数根据名称提取对象的属性。如果把多个属性名传给 attrgetter,它也会返回提取的值构成的元组。此外,如果参数名中包含 .(点号),attrgetter 会深入嵌套对象,获取指定的属性。
| |
methodcaller
methodcaller 的作用与 attrgetter 和 itemgetter 类似,它会自行创建函数
methodcaller 创建的函数会在对象上调用参数指定的方法
| |
其他
| |
这 52 个名称中大部分的作用不言而喻。以 i 开头、后面是另一个运算符的那些名称(如 iadd、iand 等),对应的是增量赋值运算符(如 +=、&= 等)。如果第一个参数是可变的,那么这些运算符函数会就地修改它;否则,作用与不带 i 的函数一样,直接返回运算结果。
使用 functools.partial 冻结参数
functools 模块提供了一系列高阶函数,其中最为人熟知的或许是 reduce。余下的函数中,最有用的是 partial 及其变体,partialmethod。
functools.partial 这个高阶函数用于部分应用一个函数。部分应用是指,基于一个函数创建一个新的可调用对象,把原函数的某些参数固定。使用这个函数可以把接受一个或多个参数的函数改编成需要回调的 API,这样参数更少。
| |
使用一等函数实现设计模式
符合模式并不表示做得对。
——Ralph Johnson,经典的《设计模式:可复用面向对象软件的基础》的作者之一
有时,设计模式或 API 要求组件实现单方法接口,而那个方法的名称很宽泛,例如“execute”“run”或“doIt”。在 Python 中,这些模式或 API 通常可以使用一等函数或其他可调用的对象实现,从而减少样板代码。
案例分析:重构“策略”模式
定义:定义一系列算法,把它们一一封装起来,并且使它们可以相互替换。本模式使得算法可以独立于使用它的客户而变化。
策略模式描述了在一个需要根据上下文内容选择合适算法的问题中,如何更好的组织这些算法的设计模式。
策略模式有如下关键组件:
- 上下文:提供进行算法选择的关键信息
- 策略:不同算法的共用接口
- 具体策略:策略的子类,不同算法的实现
经典的“策略”模式
假如一个网店制定了下述折扣规则。
- 有 1000 或以上积分的顾客,每个订单享 5% 折扣。
- 同一订单中,单个商品的数量达到 20 个或以上,享 10% 折扣。
- 订单中的不同商品达到 10 个或以上,享 7% 折扣。
下图是使用“策略”设计模式处理订单折扣的 UML 类图

在这个电商示例中,上下文是 Order,它会根据不同的算法计算促销折扣。
在这个示例中,名为 Promotion 的抽象类扮演策略这个角色
fidelityPromo、BulkPromo 和 LargeOrderPromo 是这里实现的三个具体策略。
| |
演示
| |
这个示例完全可用,但是利用 Python 中作为对象的函数,可以使用更少的代码实现相同的功能。详情参见下一节。
使用函数实现“策略”模式
在上个示例中,每个具体策略都是一个类,而且都只定义了一个方法,即 discount。此外,策略实例没有状态(没有实例属性)。你可能会说,它们看起来像是普通的函数——的确如此。下面的示例是对之前示例的重构,把具体策略换成了简单的函数,而且去掉了 Promo 抽象类。
| |
使用起来更简单,不需要实例化具体逻辑,只需要传入函数即可
| |
值得注意的是,《设计模式:可复用面向对象软件的基础》一书的作者指出:“策略对象通常是很好的享元(flyweight)。” 那本书的另一部分对 “享元” 下了定义:“享元是可共享的对象,可以同时在多个上下文中使用。”
共享是推荐的做法,这样不必在每个新的上下文(这里是
Order实例)中使用相同的策略时不断新建具体策略对象,从而减少消耗。
在复杂的情况下,需要具体策略维护内部状态时,可能需要把“策略”和“享元”模式结合起来。但是,具体策略一般没有内部状态,只是处理上下文中的数据。此时,一定要使用普通的函数,别去编写只有一个方法的类,再去实现另一个类声明的单函数接口。
函数比用户定义的类的实例轻量,而且无需使用“享元”模式,因为各个策略函数在 Python 编译模块时只会创建一次。普通的函数也是“可共享的对象,可以同时在多个上下文中使用”。
选择最佳策略:简单的方式
假设我们想创建一个“元策略”,让它为指定的订单选择最佳折扣。
| |
promos 是函数列表。习惯函数是一等对象后,自然而然就会构建那种数据结构存储函数
虽然示例可用,而且易于阅读,但是有些重复可能会导致不易察觉的缺陷:若想添加新的促销策略,要定义相应的函数,还要记得把它添加到 promos 列表中;否则,当新促销函数显式地作为参数传给 Order 时,它是可用的,但是 best_promo 不会考虑它。
找出模块中的全部策略
在 Python 中,模块也是一等对象,而且标准库提供了几个处理模块的函数。
Python 文档是这样说明内置函数 globals 的:
返回一个字典,表示当前的全局符号表。这个符号表始终针对当前模块(对函数或方法来说,是指定义它们的模块,而不是调用它们的模块)。
下面的示例使用 globals 函数帮助 best_promo 自动找到其他可用的 *_promo 函数,过程有点曲折。
| |
收集所有可用促销的另一种方法是,在一个单独的模块中保存所有策略函数,把 best_promo 排除在外
在下面的示例中,最大的变化是内省名为 promotions 的独立模块,构建策略函数列表。注意,示例要导入 promotions 模块,以及提供高阶内省函数的 inspect 模块(简单起见,这里没有给出导入语句,因为导入语句一般放在文件顶部)。
| |
inspect.getmembers 函数用于获取对象(这里是 promotions 模块)的属性,第二个参数是可选的判断条件(一个布尔值函数)。我们使用的是 inspect.isfunction,只获取模块中的函数。
不管怎么命名策略函数,示例 6-8 都可用;唯一重要的是,promotions 模块只能包含计算订单折扣的函数。当然,这是对代码的隐性假设。如果有人在 promotions 模块中使用不同的签名定义函数,那么 best_promo 函数尝试将其应用到订单上时会出错。
我们可以添加更为严格的测试,审查传给实例的参数,进一步过滤函数。这个示例的目的不是提供完善的方案,而是强调模块内省的一种用途。
动态收集促销折扣函数更为显式的一种方案是使用简单的装饰器,之后会讨论这种实现
命令模式
“命令”设计模式也可以通过把函数作为参数传递而简化
下面是菜单驱动的文本编辑器的 UML 类图,使用“命令”设计模式实现。各个命令可以有不同的接收者(实现操作的对象)。对 PasteCommand 来说,接收者是 Document。对 OpenCommand 来说,接收者是应用程序

“命令”模式的目的是解耦调用操作的对象(调用者)和提供实现的对象(接收者)
这个模式的做法是,在二者之间放一个 Command 对象,让它实现只有一个方法(execute)的接口,调用接收者中的方法执行所需的操作。这样,调用者无需了解接收者的接口,而且不同的接收者可以适应不同的 Command 子类。调用者有一个具体的命令,通过调用 execute 方法执行。注意,图 6-2 中的 MacroCommand 可能保存一系列命令,它的 execute() 方法会在各个命令上调用相同的方法。
命令模式是回调机制的面向对象替代品。问题是,我们需要回调机制的面向对象替代品吗?有时确实需要,但并非始终需要。
我们可以不为调用者提供一个 Command 实例,而是给它一个函数。此时,调用者不用调用 command.execute(),直接调用 command() 即可。MacroCommand 可以实现成定义了 __call__ 方法的类。这样,MacroCommand 的实例就是可调用对象,各自维护着一个函数列表,供以后调用
| |
使用一等函数对“命令”模式的重新审视到此结束。站在一定高度上看,这里采用的方式与“策略”模式所用的类似:把实现单方法接口的类的实例替换成可调用对象。毕竟,每个 Python 可调用对象都实现了单方法接口,这个方法就是 __call__。
⭐ 函数装饰器和闭包
函数装饰器用于在源码中“标记”函数,以某种方式增强函数的行为。这是一项强大的功能,但是若想掌握,必须理解闭包
除了在装饰器中有用处之外,闭包还是回调式异步编程和函数式编程风格的基础
装饰器基础知识
装饰器是可调用的对象,其参数是另一个函数(被装饰的函数)。装饰器可能会处理被装饰的函数,然后把它返回,或者将其替换成另一个函数或可调用对象。
假如有个名为 decorate 的装饰器:
| |
上述代码的效果与下述写法一样:
| |
两种写法的最终结果一样:上述两个代码片段执行完毕后得到的 target 不是原来那个 target 函数,而是 decorate(target) 返回的函数。
而且 target = decorate(target) 这句语句,在定义 target 函数时就会执行。
装饰器通常把函数替换成另一个函数
| |
严格来说,装饰器只是语法糖。如前所示,装饰器可以像常规的可调用对象那样调用,其参数是另一个函数。有时,这样做更方便,尤其是做元编程(在运行时改变程序的行为)时
综上,装饰器的一大特性是,能把被装饰的函数替换成其他函数。第二个特性是,装饰器在加载模块时立即执行
Python 何时执行装饰器
装饰器的一个关键特性是,它们在被装饰的函数定义之后立即运行。这通常是在导入时(即 Python 加载模块时)
| |
作为脚本运行
| |
注意,register 在模块中其他函数之前运行(两次)。调用 register 时,传给它的参数是被装饰的函数,例如 <function f1 at 0x100631bf8>。
加载模块后,registry 中有两个被装饰函数的引用:f1 和 f2。这两个函数,以及 f3,只在 main 明确调用它们时才执行。
如果导入 registration.py 模块(不作为脚本运行),输出如下:
| |
函数装饰器在导入模块时立即执行,而被装饰的函数只在明确调用时运行。这突出了 Python 程序员所说的导入时和运行时之间的区别。
虽然示例中的 register 装饰器原封不动地返回被装饰的函数,但是这种技术并非没有用处。很多 Python Web 框架使用这样的装饰器把函数添加到某种中央注册处,例如把 URL 模式映射到生成 HTTP 响应的函数上的注册处。这种注册装饰器可能会也可能不会修改被装饰的函数。下一节会举例说明。
使用装饰器改进“策略”模式
回顾一下,之前策略模式示例的主要问题是,定义体中有函数的名称,但是 best_promo 用来判断哪个折扣幅度最大的 promos 列表中也有函数名称。这种重复是个问题,因为新增策略函数后可能会忘记把它添加到 promos 列表中,导致 best_promo 忽略新策略,而且不报错,为系统引入了不易察觉的缺陷。下面的示例使用注册装饰器解决了这个问题。
| |
与老方案相比,这个方案有几个优点:
- 促销策略函数无需使用特殊的名称(即不用以
_promo结尾)。 @promotion装饰器突出了被装饰的函数的作用,还便于临时禁用某个促销策略:只需把装饰器注释掉。- 促销折扣策略可以在其他模块中定义,在系统中的任何地方都行,只要使用
@promotion装饰即可。
不过,多数装饰器会修改被装饰的函数。通常,它们会定义一个内部函数,然后将其返回,替换被装饰的函数。使用内部函数的代码几乎都要靠闭包才能正确运作。为了理解闭包,我们要退后一步,先了解 Python 中的变量作用域。
变量作用域规则
在下面的示例中,我们定义并测试了一个函数,它读取两个变量的值:一个是局部变量 a,是函数的参数;另一个是变量 b,这个函数没有定义它。
| |
出现错误并不奇怪。
在下个示例中,如果先给全局变量 b 赋值,然后再调用 f,那就不会出错:
| |
下面看一个可能会让你吃惊的示例。
| |
f2 好像没有读取全局变量 b,b 被定义为局部变量,因为在函数的定义体中给它赋值了
⭐ 这不是缺陷,而是设计选择:Python 不要求声明变量,但是假定在函数定义体中赋值的变量是局部变量。
这比 JavaScript 的行为好多了,JavaScript 也不要求声明变量,但是如果忘记把变量声明为局部变量(使用 var),可能会在不知情的情况下获取全局变量。
如果在函数中赋值时想让解释器把 b 当成全局变量,要使用 global 声明:
| |
了解 Python 的变量作用域之后,下一节可以讨论闭包了
闭包
人们有时会把闭包和匿名函数弄混。这是有历史原因的:在函数内部定义函数不常见,直到开始使用匿名函数才会这样做。而且,只有涉及嵌套函数时才有闭包问题。因此,很多人是同时知道这两个概念的。
其实,闭包指延伸了作用域的函数,其中包含函数定义体中引用、但是不在定义体中定义的非全局变量。函数是不是匿名的没有关系,关键是它能访问定义体之外定义的非全局变量。
这个概念难以掌握,最好通过示例理解。
假如有个名为 avg 的函数,它的作用是计算不断增加的系列值的均值;例如,整个历史中某个商品的平均收盘价。每天都会增加新价格,因此平均值要考虑至目前为止所有的价格。
起初,avg 是这样使用的:
| |
avg 从何而来,它又在哪里保存历史值呢?
初学者可能会像示例 7-8 那样使用类实现。
示例 7-8 average_oo.py:计算移动平均值的类
| |
Averager 的实例是可调用对象:
| |
示例 7-9 是函数式实现,使用高阶函数 make_averager。
示例 7-9 average.py:计算移动平均值的高阶函数
| |
| |
注意,这两个示例有共通之处:调用 Averager() 或 make_averager() 得到一个可调用对象 avg,它会更新历史值,然后计算当前均值。
Averager 类的实例 avg 在哪里存储历史值很明显:self.series 实例属性。但是第二个示例中的 avg 函数在哪里寻找 series 呢?
注意,series 是 make_averager 函数的局部变量,因为那个函数的定义体中初始化了 series:series = []。可是,调用 avg(10) 时,make_averager 函数已经返回了,而它的本地作用域也一去不复返了。
在 averager 函数中,series 是自由变量(free variable)。这是一个技术术语,指未在本地作用域中绑定的变量

审查返回的 averager 对象,我们发现 Python 在 __code__ 属性(表示编译后的函数定义体)中保存局部变量和自由变量的名称,如示例 7-11 所示。
示例 7-11 审查
make_averager(见示例 7-9)创建的函数
| |
series 的绑定在返回的 avg 函数的 __closure__ 属性中。avg.__closure__ 中的各个元素对应于 avg.__code__.co_freevars 中的一个名称。这些元素是 cell 对象,有个 cell_contents 属性,保存着真正的值。这些属性的值如示例 7-12 所示。
示例 7-12 接续示例 7-11
| |
⭐ 综上,闭包是一种函数,它会保留定义函数时存在的自由变量的绑定,这样调用函数时,虽然定义作用域不可用了,但是仍能使用那些绑定。
注意,只有嵌套在其他函数中的函数才可能需要处理不在全局作用域中的外部变量。
nonlocal 声明
前面实现 make_averager 函数的方法效率不高。在示例 7-9 中,我们把所有值存储在历史数列中,然后在每次调用 averager 时使用 sum 求和。更好的实现方式是,只存储目前的总值和元素个数,然后使用这两个数计算均值。
示例 7-13 中的实现有缺陷,只是为了阐明观点。
示例 7-13 计算移动平均值的高阶函数,不保存所有历史值,但有缺陷
| |
尝试使用示例 7-13 中定义的函数,会得到如下结果:
| |
问题是,当 count 是数字或任何不可变类型时,count += 1 语句的作用其实与 count = count + 1 一样。因此,我们在 averager 的定义体中为 count 赋值了,这会把 count 变成局部变量。total 变量也受这个问题影响。
示例 7-9 没遇到这个问题,因为我们没有给 series 赋值,我们只是调用 series.append,并把它传给 sum 和 len。也就是说,我们利用了列表是可变的对象这一事实。
但是对数字、字符串、元组等不可变类型来说,只能读取,不能更新。如果尝试重新绑定,例如 count = count + 1,其实会隐式创建局部变量 count。这样,count 就不是自由变量了,因此不会保存在闭包中。
为了解决这个问题,**Python 3 引入了 nonlocal 声明。它的作用是把变量标记为自由变量,即使在函数中为变量赋予新值了,也会变成自由变量。**如果为 nonlocal 声明的变量赋予新值,闭包中保存的绑定会更新。最新版 make_averager 的正确实现如示例 7-14 所示。
示例 7-14 计算移动平均值,不保存所有历史(使用
nonlocal修正)
| |
至此,我们了解了 Python 闭包,下面可以使用嵌套函数正式实现装饰器了。
实现一个简单的装饰器
示例 7-15 定义了一个装饰器,它会在每次调用被装饰的函数时计时,然后把经过的时间、传入的参数和调用的结果打印出来。
示例 7-15 一个简单的装饰器,输出函数的运行时间
| |
示例 7-16 使用
clock装饰器
| |
| |
原理
在两个示例中,factorial 会作为 func 参数传给 clock(参见示例 7-15)。然后, clock 函数会返回 clocked 函数,Python 解释器在背后会把 clocked 赋值给 factorial。其实,导入 clockdeco_demo 模块后查看 factorial 的 __name__ 属性,会得到如下结果:
| |
所以,现在 factorial 保存的是 clocked 函数的引用。自此之后,每次调用 factorial(n),执行的都是 clocked(n)。
改进
示例 7-15 中实现的 clock 装饰器有几个缺点:
- 不支持关键字参数
- 遮盖了被装饰函数的
__name__和__doc__属性。
示例 7-17 使用 functools.wraps 装饰器把相关的属性从 func 复制到 clocked 中。此外,这个新版还能正确处理关键字参数。
示例 7-17 改进后的
clock装饰器
| |
functools.wraps 只是标准库中拿来即用的装饰器之一。下一节将介绍 functools 模块中最让人印象深刻的两个装饰器:lru_cache 和 singledispatch。
标准库中的装饰器
Python 内置了三个用于装饰方法的函数:property、classmethod 和 staticmethod。
另一个常见的装饰器是 functools.wraps,它的作用是协助构建行为良好的装饰器。我们在示例 7-17 中用过。标准库中最值得关注的两个装饰器是 lru_cache 和全新的 singledispatch(Python 3.4 新增)。这两个装饰器都在 functools 模块中定义。接下来分别讨论它们。
使用 functools.lru_cache 做备忘
functools.lru_cache 是非常实用的装饰器,它实现了备忘(memoization)功能。这是一项优化技术,它把耗时的函数的结果保存起来,避免传入相同的参数时重复计算。
LRU 三个字母是“Least Recently Used”的缩写,表明缓存不会无限制增长,一段时间不用的缓存条目会被扔掉。
生成第 n 个斐波纳契数这种慢速递归函数适合使用 lru_cache:
| |
除了优化递归算法之外,lru_cache 在从 Web 中获取信息的应用中也能发挥巨大作用。
特别要注意,lru_cache 可以使用两个可选的参数来配置。它的签名是:
| |
maxsize参数指定存储多少个调用的结果。- 缓存满了之后,旧的结果会被扔掉,腾出空间。
- 为了得到最佳性能,
maxsize应该设为 2 的幂。
typed参数如果设为True,把不同参数类型得到的结果分开保存,即把通常认为相等的浮点数和整数参数(如1和1.0)区分开。- 顺便说一下,因为
lru_cache使用字典存储结果,而且键根据调用时传入的定位参数和关键字参数创建,所以被lru_cache装饰的函数,它的所有参数都必须是可散列的。
- 顺便说一下,因为
单分派泛函数 functools.singledispatch
假设我们在开发一个调试 Web 应用的工具,我们想生成 HTML,显示不同类型的 Python 对象。
我们可能会编写这样的函数:
| |
这个函数适用于任何 Python 类型,但是现在我们想做个扩展,让它使用特别的方式显示某些类型。
str:把内部的换行符替换为'<br>\n';不使用<pre>,而是使用<p>。int:以十进制和十六进制显示数字。list:输出一个 HTML 列表,根据各个元素的类型进行格式化。
我们想要的行为如示例 7-20 所示。
示例 7-20 生成 HTML 的
htmlize函数,调整了几种对象的输出
| |
因为 Python 不支持重载方法或函数,所以我们不能使用不同的签名定义 htmlize 的变体,也无法使用不同的方式处理不同的数据类型。
在 Python 中,一种常见的做法是把 htmlize 变成一个分派函数,使用一串 if/elif/elif,调用专门的函数,如 htmlize_str、htmlize_int,等等。这样不便于模块的用户扩展,还显得笨拙:时间一长,分派函数 htmlize 会变得很大,而且它与各个专门函数之间的耦合也很紧密。
Python 3.4 新增的 functools.singledispatch 装饰器可以把整体方案拆分成多个模块,甚至可以为你无法修改的类提供专门的函数。
使用 @singledispatch 装饰的普通函数会变成泛函数(generic function):根据第一个参数的类型,以不同方式执行相同操作的一组函数
示例 7-21
singledispatch创建一个自定义的htmlize.register装饰器,把多个函数绑在一起组成一个泛函数
| |
只要可能,注册的专门函数应该处理抽象基类(如 numbers.Integral 和 abc.MutableSequence),不要处理具体实现(如 int 和 list)。
这样,代码支持的兼容类型更广泛。例如,Python 扩展可以子类化 numbers.Integral,使用固定的位数实现 int 类型。
singledispatch 机制的一个显著特征是,你可以在系统的任何地方和任何模块中注册专门函数。如果后来在新的模块中定义了新的类型,可以轻松地添加一个新的专门函数来处理那个类型。
此外,你还可以为不是自己编写的或者不能修改的类添加自定义函数。
@singledispatch不是为了把 Java 的那种方法重载带入 Python。在一个类中为同一个方法定义多个重载变体,比在一个函数中使用一长串if/elif/elif/elif块要更好。但是这两种方案都有缺陷,因为它们让代码单元(类或函数)承担的职责太多。
@singledispath的优点是支持模块化扩展:各个模块可以为它支持的各个类型注册一个专门函数。
叠放装饰器
把 @d1 和 @d2 两个装饰器按顺序应用到 f 函数上,作用相当于 f = d1(d2(f))。
也就是说,下述代码:
| |
等同于:
| |
参数化装饰器
怎么让装饰器接受其他参数呢?答案是:创建一个装饰器工厂函数,把参数传给它,返回一个装饰器,然后再把它应用到要装饰的函数上。
示例 7-22 示例 7-2 中 registration.py 模块的删减版,这里再次给出是为了便于讲解
| |
一个参数化的注册装饰器
为了便于启用或禁用 register 执行的函数注册功能,我们为它提供一个可选的 active 参数,设为 False 时,不注册被装饰的函数。实现方式参见示例 7-23。
从概念上看,这个新的 register 函数不是装饰器,而是装饰器工厂函数。调用它会返回真正的装饰器,这才是应用到目标函数上的装饰器。
示例 7-23 为了接受参数,新的
register装饰器必须作为函数调用
| |
这里的关键是,register() 要返回 decorate,然后把它应用到被装饰的函数上
如果不使用 @ 句法,那就要像常规函数那样使用 register;若想把 f 添加到 registry 中,则装饰 f 函数的句法是 register()(f);不想添加(或把它删除)的话,句法是 register(active=False)(f)
参数化装饰器的原理相当复杂,我们刚刚讨论的那个比大多数都简单。参数化装饰器通常会把被装饰的函数替换掉,而且结构上需要多一层嵌套。接下来会探讨这种函数金字塔
参数化 clock 装饰器
本节再次探讨 clock 装饰器,为它添加一个功能:让用户传入一个格式字符串,控制被装饰函数的输出
示例 7-25 clockdeco_param.py 模块:参数化
clock装饰器
| |
| |
| |
对象引用、可变性和垃圾回收
变量不是盒子
Python 变量类似于 Java 中的引用式变量,因此最好把它们理解为附加在对象上的标注。
下面的例子说明了在 Python 中为什么不能使用盒子比喻,而便利贴则指出了变量的正确工作方式。
示例 8-1 变量
a和b引用同一个列表,而不是那个列表的副本
| |
如果把变量想象为盒子,那么无法解释 Python 中的赋值;应该把变量视作便利贴,这样示例 8-1 中的行为就好解释了

对引用式变量来说,说把变量分配给对象更合理,反过来说就有问题。毕竟,对象在赋值之前就创建了
因为变量只不过是标注,所以无法阻止为对象贴上多个标注。贴的多个标注,就是别名
标识、相等性和别名
charles和lewis指代同一个对象
| |
示例 8-4
alex与charles比较的结果是相等,但alex不是charles
| |
示例 8-3 体现了别名。在那段代码中,lewis 和 charles 是别名,即两个变量绑定同一个对象。而 alex 不是 charles 的别名,因为二者绑定的是不同的对象。alex 和 charles 绑定的对象具有相同的值(== 比较的就是值),但是它们的标识不同。
每个变量都有标识、类型和值。对象一旦创建,它的标识绝不会变;你可以把标识理解为对象在内存中的地址。is 运算符比较两个对象的标识;id() 函数返回对象标识的整数表示。
对象 ID 的真正意义在不同的实现中有所不同。在 CPython 中,id() 返回对象的内存地址,但是在其他 Python 解释器中可能是别的值。关键是,ID 一定是唯一的数值标注,而且在对象的生命周期中绝不会变。
其实,编程中很少使用 id() 函数。标识最常使用 is 运算符检查,而不是直接比较 ID
在 == 和 is 之间选择
**== 运算符比较两个对象的值(对象中保存的数据),而 is 比较对象的标识。**
通常,我们关注的是值,而不是标识,因此 Python 代码中 == 出现的频率比 is 高。
然而,在变量和单例值之间比较时,应该使用 is。目前,最常使用 is 检查变量绑定的值是不是 None。下面是推荐的写法:
| |
否定的正确写法是:
| |
is 运算符比 == 速度快,因为它不能重载,所以 Python 不用寻找并调用特殊方法,而是直接比较两个整数 ID。
而 a == b 是语法糖,等同于 a.__eq__(b)。继承自 object 的 __eq__ 方法比较两个对象的 ID,结果与 is 一样。但是多数内置类型使用更有意义的方式覆盖了 __eq__ 方法,会考虑对象属性的值。相等性测试可能涉及大量处理工作,例如,比较大型集合或嵌套层级深的结构时。
元组的相对不可变性
元组与多数 Python 集合(列表、字典、集,等等)一样,保存的是对象的引用。如果引用的元素是可变的,即便元组本身不可变,元素依然可变。
而 str、bytes 和 array.array 等单一类型序列是扁平的,它们保存的不是引用,而是在连续的内存中保存数据本身(字符、字节和数字)
也就是说,元组的不可变性其实是指 tuple 数据结构的物理内容(即保存的引用)不可变,与引用的对象无关。
默认做浅复制
复制列表(或多数内置的可变集合)最简单的方式是使用内置的类型构造方法。例如:
| |
l1 和 l2 指代不同的列表,但是二者引用同一个列表 [66, 55, 44] 和元组 (7, 8, 9)

示例 8-6 为一个包含另一个列表的列表做浅复制;把这段代码复制粘贴到 Python Tutor 网站中,看看动画效果
| |
示例 8-7 示例 8-6 的输出
| |
l1 和 l2 的最终状态:二者依然引用同一个列表对象,现在列表的值是 [66, 44, 33, 22],不过 l2[2] += (10, 11) 创建一个新元组,内容是 (7, 8, 9, 10, 11),它与 l1[2] 引用的元组 (7, 8, 9) 无关

浅复制容易操作,但是得到的结果可能并不是你想要的
为任意对象做深复制和浅复制
浅复制没什么问题,但有时我们需要的是深复制(即副本不共享内部对象的引用)。
copy 模块提供的 deepcopy 和 copy 函数能为任意对象做深复制和浅复制。
注意,一般来说,深复制不是件简单的事。如果对象有循环引用,那么这个朴素的算法会进入无限循环。deepcopy 函数会记住已经复制的对象,因此能优雅地处理循环引用
示例 8-10 循环引用:
b引用a,然后追加到a中;deepcopy会想办法复制a
| |
函数的参数作为引用时
Python 唯一支持的参数传递模式是共享传参(call by sharing)。多数面向对象语言都采用这一模式,包括 Ruby、Smalltalk 和 Java(Java 的引用类型是这样,基本类型按值传参)。
共享传参指函数的各个形式参数获得实参中各个引用的副本。也就是说,函数内部的形参是实参的别名
这种方案的结果是,函数可能会修改作为参数传入的可变对象,但是无法修改那些对象的标识(即不能把一个对象替换成另一个对象)
示例 8-11 函数可能会修改接收到的任何可变对象
| |
不要使用可变类型作为参数的默认值
一个正常的 Bus
| |
我们以 Bus 类为基础定义一个新类, HauntedBus,然后修改 __init__ 方法。这一次,passengers 的默认值不是 None,而是 [],这样就不用像之前那样使用 if 判断了。这个“聪明的举动”会让我们陷入麻烦。
示例 8-12 一个简单的类,说明可变默认值的危险
| |
HauntedBus 的诡异行为如示例 8-13 所示。
示例 8-13 备受幽灵乘客折磨的校车
| |
问题在于,没有指定初始乘客的 HauntedBus 实例会共享同一个乘客列表
⭐ 出现这个问题的根源是,默认值在定义函数时计算(通常在加载模块时),因此默认值变成了函数对象的属性。因此,如果默认值是可变对象,而且修改了它的值,那么后续的函数调用都会受到影响。
运行示例 8-13 中的代码之后,可以审查 HauntedBus.__init__ 对象,看看它的 __defaults__ 属性中的那些幽灵学生:
| |
最后,我们可以验证 bus2.passengers 是一个别名,它绑定到 HauntedBus.__init__.__defaults__ 属性的第一个元素上:
| |
可变默认值导致的这个问题说明了为什么通常使用 None 作为接收可变值的参数的默认值
防御可变参数
如果定义的函数接收可变参数,应该谨慎考虑调用方是否期望修改传入的参数。
例如,如果函数接收一个字典,而且在处理的过程中要修改它,那么这个副作用要不要体现到函数外部?具体情况具体分析。这其实需要函数的编写者和调用方达成共识。
在本章最后一个校车示例中,TwilightBus 实例与客户共享乘客列表,这会产生意料之外的结果。在分析实现之前,我们先从客户的角度看看 TwilightBus 类是如何工作的。
示例 8-14 从
TwilightBus下车后,乘客消失了
| |
TwilightBus 违反了设计接口的最佳实践,即“最少惊讶原则”。学生从校车中下车后,她的名字就从篮球队的名单中消失了,这确实让人惊讶。
示例 8-15 是 TwilightBus 的实现,随后解释了出现这个问题的原因。
示例 8-15 一个简单的类,说明接受可变参数的风险
| |
这里的问题是,校车为传给构造方法的列表创建了别名。正确的做法是,校车自己维护乘客列表。
修正的方法很简单:在 __init__ 中,传入 passengers 参数时,应该把参数值的副本赋值给 self.passengers
| |
除非这个方法确实想修改通过参数传入的对象,否则在类中直接把参数赋值给实例变量之前一定要三思,因为这样会为参数对象创建别名。如果不确定,那就创建副本。这样客户会少些麻烦。
del 和垃圾回收
del 语句删除名称,而不是对象。del 命令可能会导致对象被当作垃圾回收,但是仅当删除的变量保存的是对象的最后一个引用,或者无法得到对象时。
重新绑定也可能会导致对象的引用数量归零,导致对象被销毁。
如果两个对象相互引用,当它们的引用只存在二者之间时,垃圾回收程序会判定它们都无法获取,进而把它们都销毁。
有个
__del__特殊方法,但是它不会销毁实例,不应该在代码中调用。即将销毁实例时,Python 解释器会调用__del__方法,给实例最后的机会,释放外部资源。自己编写的代码很少需要实现__del__代码,有些 Python 新手会花时间实现,但却吃力不讨好,因为__del__很难用对
在 CPython 中,垃圾回收使用的主要算法是引用计数。实际上,每个对象都会统计有多少引用指向自己。当引用计数归零时,对象立即就被销毁:CPython 会在对象上调用 __del__ 方法(如果定义了),然后释放分配给对象的内存
CPython2.0 增加了分代垃圾回收算法,用于检测引用循环中涉及的对象组——如果一组对象之间全是相互引用,即使再出色的引用方式也会导致组中的对象不可获取。Python 的其他实现有更复杂的垃圾回收程序,而且不依赖引用计数,这意味着,对象的引用数量为零时可能不会立即调用 __del__ 方法
为了演示对象生命结束时的情形,示例 8-16 使用 weakref.finalize 注册一个回调函数,在销毁对象时调用。
示例 8-16 没有指向对象的引用时,监视对象生命结束时的情形
| |
示例 8-16 的目的是明确指出 del 不会删除对象,但是执行 del 操作后可能会导致对象不可获取,从而被删除
你可能觉得奇怪,为什么示例 8-16 中的 {1, 2, 3} 对象被销毁了?毕竟,我们把 s1 引用传给 finalize 函数了,而为了监控对象和调用回调,必须要有引用。这是因为,finalize 持有 {1, 2, 3} 的弱引用,参见下一节。
弱引用
正是因为有引用,对象才会在内存中存在。当对象的引用数量归零后,垃圾回收程序会把对象销毁。但是,有时需要引用对象,而不让对象存在的时间超过所需时间。这经常用在缓存中。
弱引用不会增加对象的引用数量。引用的目标对象称为所指对象(referent)。因此我们说,弱引用不会妨碍所指对象被当作垃圾回收。
弱引用在缓存应用中很有用,因为我们不想仅因为被缓存引用着而始终保存缓存对象。
示例 8-17 展示了如何使用 weakref.ref 实例获取所指对象。如果对象存在,调用弱引用可以获取对象;否则返回 None。
示例 8-17 弱引用是可调用的对象,返回的是被引用的对象;如果所指对象不存在了,返回
None
| |
示例 8-17 是一个控制台会话,Python 控制台会自动把 _ 变量绑定到结果不为 None 的表达式结果上。
这对我想演示的行为有影响,不过却凸显了一个实际问题:微观管理内存时,往往会得到意外的结果,因为不明显的隐式赋值会为对象创建新引用。控制台中的 _ 变量是一例。调用跟踪对象也常导致意料之外的引用。
weakref.ref类其实是低层接口,供高级用途使用,多数程序最好使用weakref集合和finalize。也就是说,应该使用WeakKeyDictionary、WeakValueDictionary、WeakSet和finalize(在内部使用弱引用),不要自己动手创建并处理weakref.ref实例。我们在示例 8-17 中那么做是希望借助实际使用weakref.ref来褪去它的神秘色彩。但是实际上,多数时候 Python 程序都使用weakref集合。
WeakValueDictionary 简介
WeakValueDictionary 类实现的是一种可变映射,里面的值是对象的弱引用。
被引用的对象在程序中的其他地方被当作垃圾回收后,对应的键会自动从 WeakValueDictionary 中删除。因此,WeakValueDictionary 经常用于缓存。
示例 8-18
Cheese有个kind属性和标准的字符串表示形式
| |
在示例 8-19 中,我们把 catalog 中的各种奶酪载入 WeakValueDictionary 实现的 stock 中。然而,删除 catalog 后,stock 中只剩下一种奶酪了。
示例 8-19 顾客:“你们店里到底有没有奶酪?”
| |
临时变量引用了对象,这可能会导致该变量的存在时间比预期长。通常,这对局部变量来说不是问题,因为它们在函数返回时会被销毁。
但是在示例 8-19 中,for 循环中的变量 cheese 是全局变量,除非显式删除,否则不会消失。
与 WeakValueDictionary 对应的是 WeakKeyDictionary,后者的键是弱引用。它可以为应用中其他部分拥有的对象附加数据,这样就无需为对象添加属性。这对覆盖属性访问权限的对象尤其有用。
weakref 模块还提供了 WeakSet 类,按照文档的说明,这个类的作用很简单:“保存元素弱引用的集合类。元素没有强引用时,集合会把它删除。”如果一个类需要知道所有实例,一种好的方案是创建一个 WeakSet 类型的类属性,保存实例的引用。如果使用常规的 set,实例永远不会被垃圾回收,因为类中有实例的强引用,而类存在的时间与 Python 进程一样长,除非显式删除类。
弱引用的局限
不是每个 Python 对象都可以作为弱引用的目标(或称所指对象)。
基本的 list 和 dict 实例不能作为所指对象,但是它们的子类可以轻松地解决这个问题:
| |
set 实例可以作为所指对象。用户定义的类型也没问题,这就解释了示例 8-19 中为什么使用那个简单的 Cheese 类。
但是,int 和 tuple 实例不能作为弱引用的目标,甚至它们的子类也不行。
这些局限基本上是 CPython 的实现细节,在其他 Python 解释器中情况可能不一样。这些局限是内部优化导致的结果
Python 对不可变类型施加的把戏
对元组 t 来说,t[:] 不创建副本,而是返回同一个对象的引用。此外,tuple(t) 获得的也是同一个元组的引用
文档明确指出了这个行为。在 Python 控制台中输入
help(tuple),你会看到这句话:“如果参数是一个元组,那么返回值是同一个对象。
示例 8-20 使用另一个元组构建元组,得到的其实是同一个元组
| |
str、bytes 和 frozenset 实例也有这种行为。注意,frozenset 实例不是序列,因此不能使用 fs[:](fs 是一个 frozenset 实例)。但是,fs.copy() 具有相同的效果:它会欺骗你,返回同一个对象的引用,而不是创建一个副本(tuple 同理)
copy方法不会复制所有对象,这是一个善意的谎言,为的是接口的兼容性:这使得frozenset的兼容性比set强。两个不可变对象是同一个对象还是副本,反正对最终用户来说没有区别。
示例 8-21 字符串字面量可能会创建共享的对象
| |
共享字符串字面量是一种优化措施,称为驻留(interning)。CPython 还会在小的整数上使用这个优化措施,防止重复创建“热门”数字,如 0、-1 和 42。
注意,CPython 不会驻留所有字符串和整数,驻留的条件是实现细节,而且没有文档说明。
千万不要依赖字符串或整数的驻留!比较字符串或整数是否相等时,应该使用
==,而不是is。驻留是 Python 解释器内部使用的一个特性
本节讨论的把戏,包括 frozenset.copy() 的行为,是“善意的谎言”,能节省内存,提升解释器的速度。别担心,它们不会为你带来任何麻烦,因为只有不可变类型会受到影响。或许这些细枝末节的最佳用途是与其他 Python 程序员打赌,提高自己的胜算
细节
- 其实,对象的类型也可以变,方法只有一种:为
__class__属性指定其他类。但这是在作恶。 - 在“纯”函数式编程中,所有数据都是不可变的,如果为集合追加元素,那么其实会创建新的集合
符合 Python 风格的对象
在本章中,我们将开发一个简单的二维欧几里得向量类型
对象表示形式
每门面向对象的语言至少都有一种获取对象的字符串表示形式的标准方式。Python 提供了两种方式。
repr():以便于开发者理解的方式返回对象的字符串表示形式。str():以便于用户理解的方式返回对象的字符串表示形式。
在 Python 3 中,
__repr__、__str__和__format__都必须返回 Unicode 字符串(str类型)。只有__bytes__方法应该返回字节序列(bytes类型)
构建向量类
示例 9-2 vector2d_v0.py:目前定义的都是特殊方法
| |
示例 9-2 中的
__eq__方法,在两个操作数都是Vector2d实例时可用,不过拿Vector2d实例与其他具有相同数值的可迭代对象相比,结果也是True(如Vector(3, 4) == [3, 4])。这个行为可以视作特性,也可以视作缺陷。
备选构造方法
我们可以把 Vector2d 实例转换成字节序列了;同理,也应该能从字节序列转换成 Vector2d 实例。在标准库中探索一番之后,我们发现 array.array 有个类方法 .frombytes 正好符合需求。
| |
classmethod 与 staticmethod
classmethod 定义操作类,而不是操作实例的方法。classmethod 改变了调用方法的方式,因此类方法的第一个参数是类本身,而不是实例。
classmethod 最常见的用途是定义备选构造方法,例如上个例子中的 frombytes。注意,frombytes 的最后一行使用 cls 参数构建了一个新实例,即 cls(*memv)。
按照约定,类方法的第一个参数名为 cls(但是 Python 不介意具体怎么命名)。
staticmethod 装饰器也会改变方法的调用方式,但是第一个参数不是特殊的值。其实,静态方法就是普通的函数,只是碰巧在类的定义体中,而不是在模块层定义。
示例 9-4 比较
classmethod和staticmethod的行为
| |
格式化显示
内置的 format() 函数和 str.format() 方法把各个类型的格式化方式委托给相应的 .__format__(format_spec) 方法。format_spec 是格式说明符,它是:
format(my_obj, format_spec)的第二个参数,或者str.format()方法的格式字符串,{}里代换字段中冒号后面的部分
| |
'{0.mass:5.3e}' 这样的格式字符串其实包含两部分
- 冒号左边的
'0.mass'在代换字段句法中是字段名 - 冒号后面的
'5.3e'是格式说明符。
格式说明符使用的表示法叫格式规范微语言(Format Specification Mini-Language)
格式规范微语言为一些内置类型提供了专用的表示代码。比如,b 和 x 分别表示二进制和十六进制的 int 类型,f 表示小数形式的 float 类型,而 % 表示百分数形式:
| |
格式规范微语言是可扩展的,因为各个类可以自行决定如何解释 format_spec 参数。例如, datetime 模块中的类,它们的 __format__ 方法使用的格式代码与 strftime() 函数一样。下面是内置的 format() 函数和 str.format() 方法的几个示例:
| |
如果类没有定义 __format__ 方法,从 object 继承的方法会返回 str(my_object)。我们为 Vector2d 类定义了 __str__ 方法,因此可以这样做:
| |
我们将实现自己的微语言来解决这个问题。首先,假设用户提供的格式说明符是用于格式化向量中各个浮点数分量的。我们想达到的效果是:
| |
实现这种输出的 __format__ 方法如示例 9-5 所示。
示例 9-5
Vector2d.__format__方法,第 1 版
| |
下面要在微语言中添加一个自定义的格式代码:如果格式说明符以 'p' 结尾,那么在极坐标中显示向量,即 <r, θ >,其中 r 是模,θ(西塔)是弧度;其他部分('p' 之前的部分)像往常那样解释
为自定义的格式代码选择字母时,最好避免使用其他类型用过的字母。
在格式规范微语言中,整数使用的代码有
'bcdoxXn',浮点数使用的代码有'eEfFgGn%',字符串使用的代码有's'。因此,为极坐标选的代码是
'p'。各个类使用自己的方式解释格式代码,在自定义的格式代码中重复使用代码字母不会出错,但是可能会让用户困惑。
对极坐标来说,我们已经定义了计算模的 __abs__ 方法,因此还要定义一个简单的 angle 方法,使用 math.atan2() 函数计算角度:
| |
这样便可以增强 __format__ 方法,计算极坐标,如示例 9-6 所示。
示例 9-6
Vector2d.__format__方法,第 2 版,现在能计算极坐标了
| |
| |
如本节所示,为用户自定义的类型扩展格式规范微语言并不难
可散列化
按照定义,目前 Vector2d 实例是不可散列的,因此不能放入集合(set)中:
| |
为了把 Vector2d 实例变成可散列的,必须使用 __hash__ 方法(还需要 __eq__ 方法,前面已经实现了)。此外,还要让向量不可变
目前,我们可以为分量赋新值,如 v1.x = 7,Vector2d 类的代码并不阻止这么做。我们想要的行为是这样的:
| |
为此,我们要把 x 和 y 分量设为只读特性
示例 9-7 vector2d_v3.py:这里只给出了让
Vector2d不可变的代码,完整的代码清单在示例 9-9 中
| |
注意,我们让这些向量不可变是有原因的,因为这样才能实现 __hash__ 方法。这个方法应该返回一个整数,理想情况下还要考虑对象属性的散列值(__eq__ 方法也要使用),因为相等的对象应该具有相同的散列值。
最好使用位运算符异或(^)混合各分量的散列值 —— 我们会这么做。Vector2d.__hash__ 方法的代码十分简单,如示例 9-8 所示。
示例 9-8 vector2d_v3.py:实现
__hash__方法
| |
添加 __hash__ 方法之后,向量变成可散列的了:
| |
要想创建可散列的类型,不一定要实现特性,也不一定要保护实例属性。只需正确地实现
__hash__和__eq__方法即可。但是,实例的散列值绝不应该变化,因此我们借机提到了只读特性。
Python 的私有属性和“受保护的”属性
Python 有个简单的机制,能避免子类意外覆盖“私有”属性。
举个例子。有人编写了一个名为 Dog 的类,这个类的内部用到了 mood 实例属性,但是没有将其开放。现在,你创建了 Dog 类的子类:Beagle。如果你在毫不知情的情况下又创建了名为 mood 的实例属性,那么在继承的方法中就会把 Dog 类的 mood 属性覆盖掉。这是个难以调试的问题。
为了避免这种情况,如果以 __mood 的形式(两个前导下划线,尾部没有或最多有一个下划线)命名实例属性,Python 会把属性名存入实例的 __dict__ 属性中,而且会在前面加上一个下划线和类名。因此,对 Dog 类来说,__mood 会变成 _Dog__mood;对 Beagle 类来说,会变成 _Beagle__mood。这个语言特性叫名称改写(name mangling)。
示例 9-10 私有属性的名称会被“改写”,在前面加上下划线和类名
| |
名称改写是一种安全措施,不能保证万无一失:它的目的是避免意外访问,不能防止故意做错事(图 9-1 也是一种保护装置)。
如示例 9-10 中的最后一行所示,只要知道改写私有属性名的机制,任何人都能直接读取私有属性——这对调试和序列化倒是有用。此外,只要编写 v1._Vector__x = 7 这样的代码,就能轻松地为 Vector2d 实例的私有分量直接赋值。如果真在生产环境中这么做了,出问题时可别抱怨。
不是所有 Python 程序员都喜欢名称改写功能,也不是所有人都喜欢 self.__x 这种不对称的名称。有些人不喜欢这种句法,他们约定使用一个下划线前缀编写“受保护”的属性(如 self._x)。批评使用两个下划线这种改写机制的人认为,应该使用命名约定来避免意外覆盖属性。
Python 解释器不会对使用单个下划线的属性名做特殊处理,不过这是很多 Python 程序员严格遵守的约定,他们不会在类外部访问这种属性。遵守使用一个下划线标记对象的私有属性很容易,就像遵守使用全大写字母编写常量那样容易。
不过在模块中,顶层名称使用一个前导下划线的话,的确会有影响:对
from mymod import *来说,mymod中前缀为下划线的名称不会被导入。然而,依旧可以使用from mymod import _privatefunc将其导入。
Python 文档的某些角落把使用一个下划线前缀标记的属性称为“受保护的”属性。9 使用 self._x 这种形式保护属性的做法很常见,但是很少有人把这种属性叫作“受保护的”属性。有些人甚至将其称为“私有”属性。
⭐ 使用 slots 类属性节省空间
默认情况下,Python 在各个实例中名为 __dict__ 的字典里存储实例属性。为了使用底层的散列表提升访问速度,字典会消耗大量内存。
如果要处理数百万个属性不多的实例,通过 __slots__ 类属性,能节省大量内存,方法是让解释器在元组中存储实例属性,而不用字典。
继承自超类的
__slots__属性没有效果。Python 只会使用各个类中定义的__slots__属性
定义 __slots__ 的方式是,创建一个类属性,使用 __slots__ 这个名字,并把它的值设为一个字符串构成的可迭代对象,其中各个元素表示各个实例属性。推荐使用元组,因为这样定义的 __slots__ 中所含的信息不会变化:
| |
在类中定义 __slots__ 属性的目的是告诉解释器:“这个类中的所有实例属性都在这儿了!”这样,Python 会在各个实例中使用类似元组的结构存储实例变量,从而避免使用消耗内存的 __dict__ 属性。如果有数百万个实例同时活动,这样做能节省大量内存。
在类中定义
__slots__属性之后,实例不能再有__slots__中所列名称之外的其他属性。这只是一个副作用,不是__slots__存在的真正原因。不要使用__slots__属性禁止类的用户新增实例属性。__slots__是用于优化的,不是为了约束程序员。
然而,“节省的内存也可能被再次吃掉”:如果把 '__dict__' 这个名称添加到 __slots__ 中,实例会在元组中保存各个实例的属性,此外还支持动态创建属性,这些属性存储在常规的 __dict__ 中。当然,把 '__dict__' 添加到 __slots__ 中可能完全违背了初衷,这取决于各个实例的静态属性和动态属性的数量及其用法。粗心的优化甚至比提早优化还糟糕。
此外,还有一个实例属性可能需要注意,即 __weakref__ 属性,为了让对象支持弱引用,必须有这个属性。用户定义的类中默认就有 __weakref__ 属性。可是,如果类中定义了 __slots__ 属性,而且想把实例作为弱引用的目标,那么要把 '__weakref__' 添加到 __slots__ 中。
处理列表数据时 __slots__ 属性最有用,例如模式固定的数据库记录,以及特大型数据集。
总之,如果使用得当,__slots__ 能显著节省内存,不过有几点要注意。
- 每个子类都要定义
__slots__属性,因为解释器会忽略继承的__slots__属性。 - 实例只能拥有
__slots__中列出的属性,除非把'__dict__'加入__slots__中(这样做就失去了节省内存的功效)。 - 如果不把
'__weakref__'加入__slots__,实例就不能作为弱引用的目标。
如果你的程序不用处理数百万个实例,或许不值得费劲去创建不寻常的类,那就禁止它创建动态属性或者不支持弱引用。与其他优化措施一样,仅当权衡当下的需求并仔细搜集资料后证明确实有必要时,才应该使用 __slots__ 属性。
覆盖类属性
Python 有个很独特的特性:类属性可用于为实例属性提供默认值。Vector2d 中有个 typecode 类属性,__bytes__ 方法两次用到了它,而且都故意使用 self.typecode 读取它的值。因为 Vector2d 实例本身没有 typecode 属性,所以 self.typecode 默认获取的是 Vector2d.typecode 类属性的值。
但是,如果为不存在的实例属性赋值,会新建实例属性。假如我们为 typecode 实例属性赋值,那么同名类属性不受影响。然而,自此之后,实例读取的 self.typecode 是实例属性 typecode,也就是把同名类属性遮盖了。借助这一特性,可以为各个实例的 typecode 属性定制不同的值。
Vector2d.typecode 属性的默认值是 'd',即转换成字节序列时使用 8 字节双精度浮点数表示向量的各个分量。如果在转换之前把 Vector2d 实例的 typecode 属性设为 'f',那么使用 4 字节单精度浮点数表示各个分量,如示例 9-13 所示。
示例 9-13 设定从类中继承的
typecode属性,自定义一个实例属性
| |
现在你应该知道为什么要在得到的字节序列前面加上 typecode 的值了:为了支持不同的格式
如果想修改类属性的值,必须直接在类上修改,不能通过实例修改。如果想修改所有实例(没有 typecode 实例变量)的 typecode 属性的默认值,可以这么做:
| |
然而,有种修改方法更符合 Python 风格,而且效果持久,也更有针对性。类属性是公开的,因此会被子类继承,于是经常会创建一个子类,只用于定制类的数据属性。Django 基于类的视图就大量使用了这个技术。具体做法如示例 9-14 所示。
示例 9-14
ShortVector2d是Vector2d的子类,只用于覆盖typecode的默认值
| |