Golang 基础语法
- Go is an open source programming language supported by Google
- Easy to learn and get started with
- Built-in concurrency and a robust standard library
- Growing ecosystem of partners, communities, and tools
安装
下载地址:https://go.dev/dl/
Linux
1
2
3
4
5
6
| $ wget https://studygolang.com/dl/golang/go1.13.6.linux-amd64.tar.gz
$ tar -zxvf go1.13.6.linux-amd64.tar.gz
$ sudo mv go /usr/local/
$ go version
go version go1.13.6 linux/amd64
|
从 Go 1.11 版本开始,Go 提供了 Go Modules 的机制,推荐设置以下环境变量,第三方包的下载将通过国内镜像,避免出现官方网址被屏蔽的问题。
1
| $ go env -w GOPROXY=https://goproxy.cn,direct
|
或在 ~/.profile 中设置环境变量
1
| export GOPROXY=https://goproxy.cn
|
Windows
官网下安装包就好啦~
默认安装路径:C:\Program Files\Go
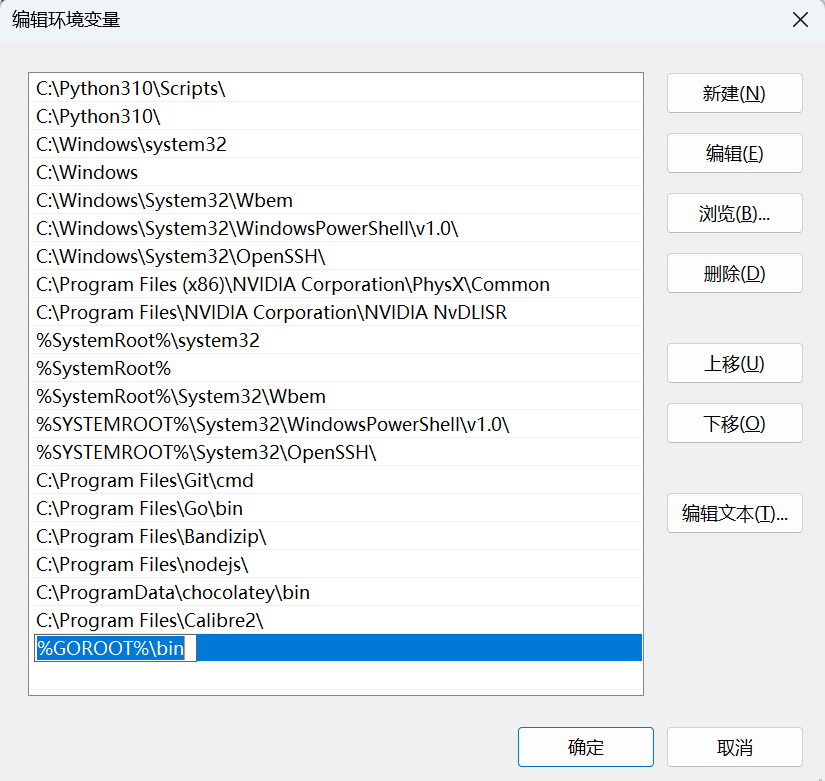
需要新建两个环境变量配置
- GOROOT ,这是 Go 环境所在目录的配置:
C:\Program Files\Go - GOPATH ,这个是 Go 项目的工作目录
- 最好建两个,第一个是默认第三方包的下载位置,第二个放自己的代码
C:\Users\<user_name>\go
然后在 path 环境变量中新建 %GOROOT%\bin
基本结构
1
2
3
4
5
6
7
| package main
import "fmt"
func main() {
fmt.Println("Hello World!")
}
|
运行
执行 go run main.go 或 go run .,将会输出
1
2
| $ go run .
Hello World!
|
go run main.go,其实是 2 步:
- go build main.go:编译成二进制可执行程序
- ./main:执行该程序
如果强制启用了 Go Modules 机制,即环境变量中设置了 GO111MODULE=on,则需要先初始化模块 go mod init hello
否则会报错误:go: cannot find main module; see ‘go help modules’
或者直接编译生成可执行文件
1
2
3
| go build main.go
# or
go build -o hello.exe ./main.go # 指定可执行文件名
|
基本结构
package main:声明了 main.go 所在的包,Go 语言中使用包来组织代码。一般一个文件夹即一个包,包内可以暴露类型或方法供其他包使用。import “fmt”:fmt 是 Go 语言的一个标准库/包,用来处理标准输入输出。func main:main 函数是整个程序的入口,main 函数所在的包名也必须为 main。fmt.Println(“Hello World!”):调用 fmt 包的 Println 方法,打印出 “Hello World!”
一些命令
go build
这个命令主要用于编译代码。在包的编译过程中,若有必要,会同时编译与之相关联的包。
如果是普通应用包,执行后不会产生任何文件。如果你需要在 $GOPATH/pkg 下生成相应的文件,那就得执行 go install。
如果是 main 包,执行后会在当前目录下生成一个可执行文件。如果你需要在 $GOPATH/bin 下生成相应的文件,需要执行 go install,或者使用 go build -o 路径/a.exe。
如果某个项目文件夹下有多个文件,而你只想编译某个文件,就可在 go build 之后加上文件名,例如 go build a.go;go build 命令默认会编译当前目录下的所有 go 文件。
你也可以指定编译输出的文件名。
- 例如
go build -o hello.exe ./main.go
go build 会忽略目录下以 “_” 或 “.” 开头的 go 文件。
如果你的源代码针对不同的操作系统需要不同的处理,那么你可以根据不同的操作系统后缀来命名文件。例如有一个读取数组的程序,它对于不同的操作系统可能有如下几个源文件:
array_linux.go, array_darwin.go, array_windows.go, array_freebsd.go
go build 的时候会选择性地编译以系统名结尾的文件(Linux、Darwin、Windows、Freebsd)。例如 Linux 系统下面编译只会选择 array_linux.go 文件,其它系统命名后缀文件全部忽略。
参数
-o 指定输出的文件名,可以带上路径,例如 go build -o a/b/c-i 安装相应的包,编译 +go install-a 更新全部已经是最新的包的,但是对标准包不适用-n 把需要执行的编译命令打印出来,但是不执行,这样就可以很容易的知道底层是如何运行的-p n 指定可以并行可运行的编译数目,默认是 CPU 数目-race 开启编译的时候自动检测数据竞争的情况,目前只支持 64 位的机器-v 打印出来我们正在编译的包名-work 打印出来编译时候的临时文件夹名称,并且如果已经存在的话就不要删除-x 打印出来执行的命令,其实就是和 -n 的结果类似,只是这个会执行-ccflags 'arg list' 传递参数给 5c, 6c, 8c 调用-compiler name 指定相应的编译器,gccgo 还是 gc-gccgoflags 'arg list' 传递参数给 gccgo 编译连接调用-gcflags 'arg list' 传递参数给 5g, 6g, 8g 调用-installsuffix suffix 为了和默认的安装包区别开来,采用这个前缀来重新安装那些依赖的包,-race 的时候默认已经是 -installsuffix race,大家可以通过 -n 命令来验证-ldflags 'flag list' 传递参数给 5l, 6l, 8l 调用-tags 'tag list' 设置在编译的时候可以适配的那些 tag
go clean
移除当前源码包和关联源码包里面编译生成的文件。这些文件包括
1
2
3
4
5
6
7
8
9
10
11
| _obj/ 旧的object目录,由Makefiles遗留
_test/ 旧的test目录,由Makefiles遗留
_testmain.go 旧的gotest文件,由Makefiles遗留
test.out 旧的test记录,由Makefiles遗留
build.out 旧的test记录,由Makefiles遗留
*.[568ao] object文件,由Makefiles遗留
DIR(.exe) 由go build产生
DIR.test(.exe) 由go test -c产生
MAINFILE(.exe) 由go build MAINFILE.go产生
*.so 由 SWIG 产生
|
可以利用这个命令清除编译文件,然后 git 递交源码,在本机测试的时候这些编译文件都是和系统相关的,但是对于源码管理来说没必要。
1
2
3
4
| $ go clean -i -n
cd /Users/astaxie/develop/gopath/src/mathapp
rm -f mathapp mathapp.exe mathapp.test mathapp.test.exe app app.exe
rm -f /Users/astaxie/develop/gopath/bin/mathapp
|
参数
-i 清除关联的安装的包和可运行文件,也就是通过 go install 安装的文件-n 把需要执行的清除命令打印出来,但是不执行,这样就可以很容易的知道底层是如何运行的-r 循环的清除在 import 中引入的包-x 打印出来执行的详细命令,其实就是 -n 打印的执行版本
go get
这个命令是用来动态获取远程代码包的,目前支持的有 BitBucket、GitHub、Google Code 和 Launchpad。
这个命令在内部实际上分成了两步操作
- 下载源码包
- 执行
go install
下载源码包的 go 工具会自动根据不同的域名调用不同的源码工具,对应关系如下:
1
2
3
4
| BitBucket (Mercurial Git)
GitHub (Git)
Google Code Project Hosting (Git, Mercurial, Subversion)
Launchpad (Bazaar)
|
所以为了 go get 能正常工作,你必须确保安装了合适的源码管理工具,并同时把这些命令加入你的 PATH 中。
参数
-d 只下载不安装-f 只有在你包含了 -u 参数的时候才有效,不让 -u 去验证 import 中的每一个都已经获取了,这对于本地 fork 的包特别有用-fix 在获取源码之后先运行 fix,然后再去做其他的事情-t 同时也下载需要为运行测试所需要的包-u 强制使用网络去更新包和它的依赖包-v 显示执行的命令
go install
这个命令在内部实际上分成了两步操作:第一步是生成结果文件(可执行文件或者 .a 包),第二步会把编译好的结果移到 $GOPATH/pkg 或者 $GOPATH/bin。
参数支持 go build 的编译参数。只要记住一个参数 -v 就好了,这个随时随地的可以查看底层的执行信息。
go test
执行这个命令,会自动读取源码目录下面名为 *_test.go 的文件,生成并运行测试用的可执行文件。
输出的信息类似
1
2
3
4
| ok archive/tar 0.011s
FAIL archive/zip 0.022s
ok compress/gzip 0.033s
...
|
默认的情况下,不需要任何的参数,它会自动把你源码包下面所有 test 文件测试完毕
参数
-bench regexp 执行相应的 benchmarks,例如 -bench=.-cover 开启测试覆盖率-run regexp 只运行 regexp 匹配的函数,例如 -run=Array 那么就执行包含有 Array 开头的函数-v 显示测试的详细命令
go get 和 go install 职责的改变
在 1.16 之后,go install 被设计为“用于构建和安装二进制文件”, go get 则被设计为 “用于编辑 go.mod 变更依赖”,并且使用时,应该与 -d 参数共用,在将来版本中 -d 可能会默认启用;
基本上 go install <package>@<version> 是用于命令的全局安装,例如:go install sigs.k8s.io/kind@v0.9.0;
而 go get 安装二进制的功能,后续版本将会删除,它主要被设计为修改 go.mod 追加依赖之类的,但还存在类似 go mod tidy 之类的命令,所以使用频率可能不会很高;
项目
GOPATH
go 命令依赖一个重要的环境变量:$GOPATH
Windows 系统中环境变量的形式为 %GOPATH%
GOPATH 允许多个目录,当有多个目录时,请注意分隔符,Windows 是分号,Linux 是冒号,当有多个 GOPATH 时,默认会将 go get 的内容放在第一个目录下
$GOPATH 目录有三个子目录:
- src 存放源代码(比如:.go .c .h .s 等)
- pkg 编译后生成的文件(比如:.a)
- bin 编译后生成的可执行文件
GOPATH 下的 src 目录就是接下来开发程序的主要目录,所有的源码都是放在这个目录下面。一般情况下,一个文件夹就是一个项目
- 例如: $GOPATH/src/mymath 表示 mymath 是个应用包或者可执行应用(根据 package 是 main 还是其他来决定,main 的话就是可执行应用)
- 允许多级目录,例如在 src 下面新建了目录 $GOPATH/src/github.com/astaxie/beedb 那么这个包路径就是 “github.com/astaxie/beedb”,包名称是最后一个目录 beedb
文件结构举例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| bin/
mathapp
pkg/
平台名/ 如:darwin_amd64、linux_amd64
mymath.a
github.com/
astaxie/
beedb.a
src/
mathapp
main.go
mymath/
sqrt.go
github.com/
astaxie/
beedb/
beedb.go
util.go
|
编写应用包例
1
2
| cd $GOPATH/src
mkdir mymath
|
新建文件 sqrt.go,内容如下
1
2
3
4
5
6
7
8
9
10
| // $GOPATH/src/mymath/sqrt.go源码如下:
package mymath
func Sqrt(x float64) float64 {
z := 0.0
for i := 0; i < 1000; i++ {
z -= (z*z - x) / (2 * x)
}
return z
}
|
这样 sqrt 应用包目录和代码已经新建完毕
建议 package 的名称和目录名保持一致
编译安装应用包
- 在任意的目录执行
go install [pkg_name] - 进入对应的应用包目录,然后执行
go install,即完成对应应用包的安装
在 pkg 目录可以看到安装好的应用包(.a 结尾)
编译程序
进入该应用目录,然后执行 go build,将在此目录下生成一个同名可执行文件
进入该目录,执行 go install,将在 $GOPATH/bin/ 下生成一个同名可执行文件
在命令行输入同名就能运行
Go Module
基本操作
初始化
1
| go mod init [module 名称]
|
检测和清理依赖
执行
第一次执行时,go mod 会自动查找依赖自动下载
go module 安装 package 的原則是先拉最新的 release tag,若无 tag 则拉最新的 commit
go 会自动生成一个 go.sum 文件来记录 dependency tree
安装指定包
1
| go get -v github.com/go-ego/gse@v0.60.0-rc4.2
|
检查可以升级的 package
下载依赖文件
更新依赖
更新指定包依赖:
1
| go get -u github.com/go-ego/gse
|
指定版本:
1
| go get -u github/com/go-ego/gse@v0.60.0-rc4.2
|
替换无法直接获取的 pkg
modules 可以通过在 go.mod 文件中使用 replace 指令替换成 github 上对应的库,比如:
1
2
3
| replace (
golang.org/x/crypto v0.0.0-20190313024323-a1f597ede03a => github.com/golang/crypto v0.0.0-20190313024323-a1f597ede03a
)
|
使用七牛的镜像源
1
| go env -w GOPROXY=https://goproxy.cn
|
数据类型
变量 Variable
Go 语言是静态类型的,变量声明时必须明确变量的类型。
Go 语言的类型在变量后面。
1
2
3
| var a int // 如果没有赋值,默认为0
var a int = 1 // 声明时赋值
var a = 1 // 声明时赋值
|
var a = 1,因为 1 是 int 类型的,所以赋值时,a 自动被确定为 int 类型,所以类型名可以省略不写,这种方式还有一种更简单的表达:
1
2
| a := 1
msg := "Hello World!"
|
:= 只能用在函数内部;在函数外部使用则会无法编译通过,所以一般用 var 方式来定义全局变量。
_(下划线)是个特殊的变量名,任何赋予它的值都会被丢弃。在这个例子中,我们将值 35 赋予 b,并同时丢弃 34:
Go 对于已声明但未使用的变量会在编译阶段报错
常量
常量可定义为数值、布尔值或字符串等类型
1
2
3
4
5
6
7
8
9
| const constantName = value
//如果需要,也可以明确指定常量的类型:
const Pi float32 = 3.1415926
// example
const Pi = 3.1415926
const i = 10000
const MaxThread = 10
const prefix = "astaxie_"
|
Go 常量和一般程序语言不同的是,可以指定相当多的小数位数 (例如 200 位), 若指定给 float32 自动缩短为 32bit,指定给 float64 自动缩短为 64bit
内置基本类型
Go 支持如下内置基本类型:
- 一种内置布尔类型:
bool。 - 11 种内置整数类型:
int8、uint8、int16、uint16、int32、uint32、int64、uint64、int、uint 和 uintptr。 - 两种内置浮点数类型:
float32 和 float64。 - 两种内置复数类型:
complex64 和 complex128。 - 一种内置字符串类型:
string。
内置类型也称为预声明类型
除了 bool 和 string 类型,其它的 15 种内置基本类型都称为数值类型(整型、浮点数型和复数型)。
Go 中有两种内置类型别名(type alias):
byte 是 uint8 的内置别名。 它们是同一个类型。rune 是 int32 的内置别名。 它们是同一个类型。
任一个类型的所有值的尺寸都是相同的,所以一个值的尺寸也常称为它的类型的尺寸。
uintptr、int 以及 uint 类型的值的尺寸依赖于具体编译器实现。
- 通常地,在 64 位的架构上,
int 和 uint 类型的值是 64 位的; - 在 32 位的架构上,它们是 32 位的。
- 编译器必须保证
uintptr 类型的值的尺寸能够存下任意一个内存地址。
一个 complex64 复数值的实部和虚部都是 float32 类型的值。 一个 complex128 复数值的实部和虚部都是 float64 类型的值。
复数的形式为 RE + IMi,其中 RE 是实数部分,IM 是虚数部分,而最后的 i 是虚数单位。下面是一个使用复数的例子:
1
2
3
| var c complex64 = 5+5i
fmt.Printf("Value is: %v", c) //output: (5+5i)
|
在内存中,所有的浮点数都使用 IEEE-754 格式存储。
从逻辑上说,一个字符串值表示一段文本。 在内存中,一个字符串存储为一个字节序列。 此字节序列体现了此字符串所表示的文本的 UTF-8 编码形式。
字符串
1
2
3
4
5
6
7
8
| //示例代码
var frenchHello string // 声明变量为字符串的一般方法
var emptyString string = "" // 声明了一个字符串变量,初始化为空字符串
func test() {
no, yes, maybe := "no", "yes", "maybe" // 简短声明,同时声明多个变量
japaneseHello := "Konichiwa" // 同上
frenchHello = "Bonjour" // 常规赋值
}
|
utf-8
在 Go 语言中,字符串使用 UTF8 编码
UTF8 的好处在于,如果基本是英文,每个字符占 1 byte,和 ASCII 编码是一样的,非常节省空间,如果是中文,一般占 3 字节。包含中文的字符串的处理方式与纯 ASCII 码构成的字符串有点区别。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| package main
import (
"fmt"
"reflect"
)
func main() {
str1 := "Golang"
str2 := "Go语言"
fmt.Println(reflect.TypeOf(str2[2]).Kind()) // uint8
fmt.Println(str1[2], string(str1[2])) // 108 l
fmt.Printf("%d %c\n", str2[2], str2[2]) // 232 è
fmt.Println("len(str2):", len(str2)) // len(str2): 8
}
|
reflect.TypeOf().Kind() 可以知道某个变量的类型,我们可以看到,字符串是以 byte 数组形式保存的,类型是 uint8,占 1 个 byte,打印时需要用 string 进行类型转换,否则打印的是编码值。- 因为字符串是以 byte 数组的形式存储的,所以,
str2[2] 的值并不等于 语。str2 的长度 len(str2) 也不是 4,而是 8( Go 占 2 byte,语言 占 6 byte)。
特性
使用 + 操作符来连接两个字符串:
1
2
3
4
| s := "hello,"
m := " world"
a := s + m
fmt.Printf("%s\n", a)
|
修改字符串也可写为:
1
2
3
| s := "hello"
s = "c" + s[1:] // 字符串虽不能更改,但可进行切片操作
fmt.Printf("%s\n", s)
|
使用反引号来声明多行字符串(没有字符转义)
处理中文
正确的处理方式是将 string 转为 rune 数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| package main
import (
"fmt"
"unicode/utf8"
)
func main() {
var str = "hello 你好"
//golang中string底层是通过byte数组实现的,座椅直接求len 实际是在按字节长度计算 所以一个汉字占3个字节算了3个长度
fmt.Println("len(str):", len(str))
//以下两种都可以得到str的字符串长度
//golang中的unicode/utf8包提供了用utf-8获取长度的方法
fmt.Println("RuneCountInString:", utf8.RuneCountInString(str))
//通过rune类型处理unicode字符
fmt.Println("rune:", len([]rune(str)))
}
|
转换成 []rune 类型后,字符串中的每个字符,无论占多少个字节都用 int32 来表示,因而可以正确处理中文。
byte 表示一个字节,可以表示英文字符等占用一个字节的字符,占用多于一个字节的字符就无法正确表示,例如占用 3 个字节的汉字
rune 表示一个字符,用来表示任何一个字符
修改字符串
在 Go 中字符串是不可变的,如果真的想要改:
1
2
3
4
5
6
7
8
9
10
| s := "hello"
c := []byte(s) // 将字符串 s 转换为 []byte 类型
c[0] = 'c'
s2 := string(c) // 再转换回 string 类型
fmt.Printf("%s\n", s2)
// or
s := "hello"
s = "c" + s[1:] // 字符串虽不能更改,但可进行切片操作
fmt.Printf("%s\n", s)
|
错误类型
Go 内置有一个 error 类型,专门用来处理错误信息,Go 的 package 里面还专门有一个包 errors 来处理错误:
1
2
3
4
| err := errors.New("emit macho dwarf: elf header corrupted")
if err != nil {
fmt.Print(err)
}
|
数据类型之间的转换
转换数据类型的方式很简单。
1
| valueOfTypeB = typeB(valueOfTypeA)
|
例如:
1
2
3
4
| // 浮点数
a := 5.0
// 转换为int类型
b := int(a)
|
Go 允许在底层结构相同的两个类型之间互转。例如:
1
2
3
4
5
6
7
8
9
10
11
| // IT类型的底层是int类型
type IT int
// a的类型为IT,底层是int
var a IT = 5
// 将a(IT)转换为int,b现在是int类型
b := int(5)
// 将b(int)转换为IT,c现在是IT类型
c := IT(b)
|
但注意:
- 不是所有数据类型都能转换的,例如字母格式的 string 类型 “abcd” 转换为 int 肯定会失败
- 低精度转换为高精度时是安全的,高精度的值转换为低精度时会丢失精度。例如 int32 转换为 int16,float32 转换为 int
- 这种简单的转换方式不能对 int(float) 和 string 进行互转,要跨大类型转换,可以使用
strconv 包提供的函数
数组 array
- 数组是值。将一个数组赋予另一个数组会复制其所有元素。
- 特别地,若将某个数组传入某个函数,它将接收到该数组的一份副本而非指针。
- 数组的大小是其类型的一部分。类型
[10]int 和 [20]int 是不同的。
声明数组
1
2
3
| var arr [5]int // 一维
var arr2 [5][5]int // 二维
var arr = [5]int{1, 2, 3, 4, 5} // 声明时初始化
|
使用 := 声明
1
2
3
| a := [3]int{1, 2, 3}
b := [10]int{1, 2, 3} // 前三个元素初始化为1、2、3,其它默认为0
c := [...]int{4, 5, 6} // 可以省略长度而采用`...`的方式,Go会自动根据元素个数来计算长度
|
声明嵌套数组
1
2
3
4
5
| // 声明了一个二维数组,该数组以两个数组作为元素,其中每个数组中又有4个int类型的元素
doubleArray := [2][4]int{[4]int{1, 2, 3, 4}, [4]int{5, 6, 7, 8}}
// 上面的声明可以简化,直接忽略内部的类型
easyArray := [2][4]int{{1, 2, 3, 4}, {5, 6, 7, 8}}
|
使用 [] 索引/修改数组
1
2
3
4
5
| arr := [5]int{1, 2, 3, 4, 5}
for i := 0; i < len(arr); i++ {
arr[i] += 100
}
fmt.Println(arr) // [101 102 103 104 105]
|
由于长度也是数组类型的一部分,因此 [3]int 与 [4]int 是不同的类型,数组也就不能改变长度。
数组之间的赋值是值的赋值,即当把一个数组作为参数传入函数的时候,传入的其实是该数组的副本,而不是它的指针。要传指针得使用 slice
切片 slice
数组的长度不能改变,如果想拼接 2 个数组,或是获取子数组,需要使用切片
切片通过对数组进行封装,为数据序列提供了更通用、强大而方便的接口。 除了矩阵变换这类需要明确维度的情况外,Go 中的大部分数组编程都是通过切片来完成的。
Go 和 Python 的切片在底层实现上完全不同
python 的切片产生的是新的对象,对新对象的成员的操作不影响旧对象;
go 的切片产生的是旧对象一部分的引用,对其成员的操作会影响旧对象。
这其实也体现了脚本语言和编译语言的不同。虽然两个语言都有类似的切片操作;但是 python 主要目标是方便;go 主要目标却是快速(并弥补丢弃指针运算的缺陷)
性质
切片是数组的抽象。
切片使用数组作为底层结构。
切片包含三个组件
切片可以随时进行扩展
slice 并不是真正意义上的动态数组,而是一个引用类型。slice 总是指向一个底层 array
声明
声明切片和 array 一样,只是不需要指定长度
1
2
3
4
5
6
7
8
9
| // 普通声明
var fslice []int
// 声明并初始化
slice := []byte{'a', 'b', 'c', 'd'}
// 从一个数组或一个已经存在的slice中再次声明
var ar = [10]byte{'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'}
a := ar[2:5]
|
或者使用 make() 创建切片
1
2
3
| slice1 := make([]float32, 0) // 长度为0的切片
slice2 := make([]float32, 3, 5) // [0 0 0] 长度为3容量为5的切片
fmt.Println(len(slice2), cap(slice2)) // 3 5
|
从 Go1.2 开始 slice 支持三个参数的声明
1
2
3
| var array [10]int
slice := array[2:4] // 一般声明方法, cap=8
slice = array[2:4:7] //使用三个参数声明, cap=7-2
|
使用
使用切片:
1
2
3
4
5
6
7
8
9
| // 添加元素,切片容量可以根据需要自动扩展
slice2 = append(slice2, 1, 2, 3, 4) // [0, 0, 0, 1, 2, 3, 4]
fmt.Println(len(slice2), cap(slice2)) // 7 12
// 子切片 [start, end)
sub1 := slice2[3:] // [1 2 3 4]
sub2 := slice2[:3] // [0 0 0]
sub3 := slice2[1:4] // [0 0 1]
// 合并切片
combined := append(sub1, sub2...) // [1, 2, 3, 4, 0, 0, 0]
|
- 声明切片时可以为切片设置容量大小,为切片预分配空间。
- 在实际使用的过程中,如果容量不够,切片容量会自动扩展。
sub2... 是切片解构的写法,将切片解构为 N 个独立的元素。
内置函数
len():获取 slice 的长度cap():获取 slice 的最大容量append():向 slice 里面追加一个或者多个元素,然后返回一个和 slice 一样类型的 slicecopy():函数 copy 从源 slice 的 src 中复制元素到目标 dst,并且返回复制的元素的个数
append 函数会改变 slice 所引用的数组的内容,从而影响到引用同一数组的其它 slice。
但当 slice 中没有剩余空间(即 (cap-len) == 0)时,此时将动态分配新的数组空间。返回的 slice 数组指针将指向这个空间,而原数组的内容将保持不变;其它引用此数组的 slice 则不受影响。
小例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| package main
import "fmt"
func fn1() {
var arr [5]int = [5]int{1, 2, 3, 4, 5}
slice := arr[:3]
slice = append(slice, 100) // 直接覆盖原数组的4
fmt.Println(slice) // [1,2,3,100]
fmt.Println(arr) // [1,2,3,100,5]
}
func fn2() {
var arr [5]int = [5]int{1, 2, 3, 4, 5}
slice := arr[:3:3]
slice = append(slice, 100) // 扩容 分配新内存 不影响原数组
fmt.Println(slice) // [1,2,3,100]
fmt.Println(arr) // [1,2,3,4,5]
}
func main() {
fn1()
fn2()
}
|
字典 / 键值对,map
map 类似于 java 的 HashMap,Python 的字典 (dict),是一种存储键值对 (Key-Value) 的数据结构。使用方式和其他语言几乎没有区别。
声明
1
2
3
4
5
6
7
8
9
10
11
| // 仅声明,这种方式的声明需要在使用之前使用make初始化
var m0 map[string]int
// 声明并用make初始化
m1 := make(map[string]int)
// 声明时初始化
m2 := map[string]string{
"Sam": "Male",
"Alice": "Female",
}
// 赋值/修改
m1["Tom"] = 18
|
特性
map 是无序的,每次打印出来的 map 都会不一样,它不能通过 index 获取,而必须通过 key 获取map 的长度不固定,和 slice 一样,也是一种引用类型- 内置的
len 函数将返回 map 拥有的 key 的数量 map 和其他基本型别不同,它不是 thread-safe,在多个 go-routine 存取时,必须使用 mutex lock 机制- 若试图通过映射中不存在的键来取值,就会返回与该映射中项的类型对应的零值。
因为 map 也是一种引用类型,如果两个 map 同时指向一个底层,那么一个改变,另一个也相应的改变:
1
2
3
4
| m := make(map[string]string)
m["Hello"] = "Bonjour"
m1 := m
m1["Hello"] = "Salut" // 现在m["hello"]的值已经是Salut了
|
删除
1
2
3
4
5
6
7
8
9
10
11
| // 初始化一个字典
rating := map[string]float32{"C":5, "Go":4.5, "Python":4.5, "C++":2 }
// map有两个返回值,第二个返回值,如果不存在key,那么ok为false,如果存在ok为true
csharpRating, ok := rating["C#"]
if ok {
fmt.Println("C# is in the map and its rating is ", csharpRating)
} else {
fmt.Println("We have no rating associated with C# in the map")
}
delete(rating, "C") // 删除key为C的元素
|
make, new 操作
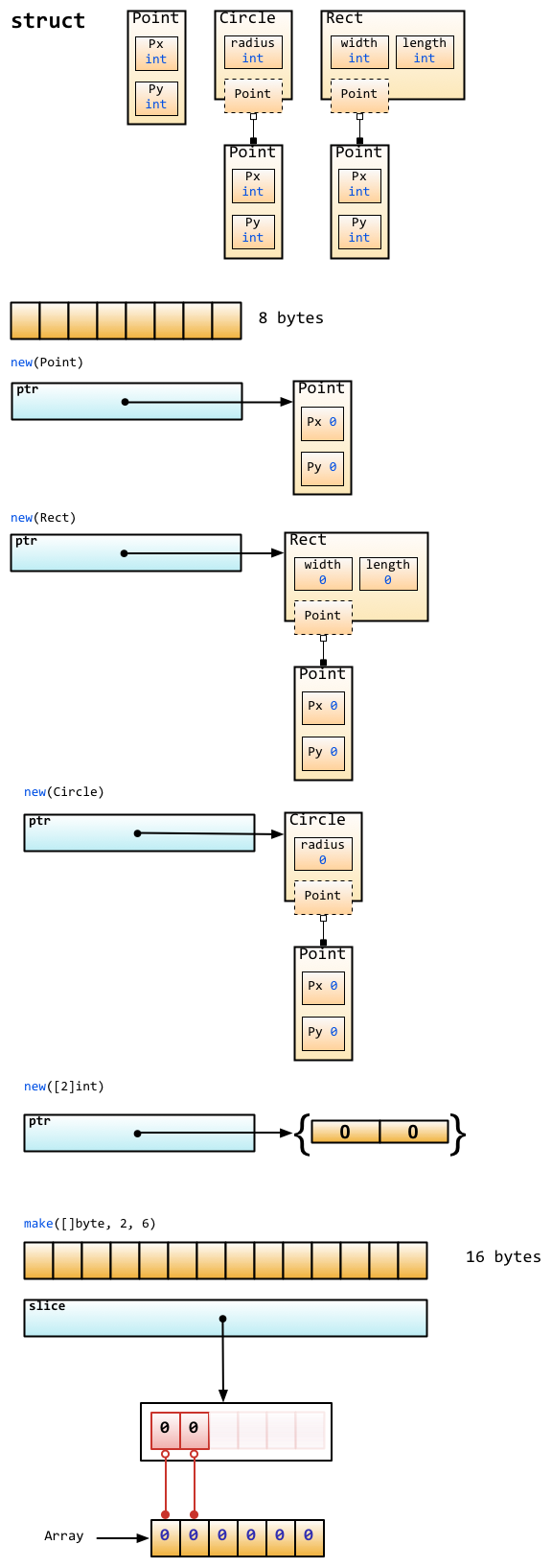
make 用于内建类型(map、slice 和 channel)的内存分配。new 用于各种类型的内存分配。
内建函数 new 本质上说跟其它语言中的同名函数功能一样:new(T) 分配了零值填充的 T 类型的内存空间,并且返回其地址,即一个 *T 类型的值。用 Go 的术语说,它返回了一个指针,指向新分配的类型 T 的零值。
一言以蔽之:new 返回指针。
内建函数 make(T, args) 与 new(T) 有着不同的功能,make 只能创建 slice、map 和 channel,并且返回一个有初始值 (非零) 的 T 类型,而不是 *T。
本质来讲,导致这三个类型有所不同的原因是指向数据结构的引用在使用前必须被初始化。例如,一个 slice,是一个包含指向数据(内部 array)的指针、长度和容量的三项描述符;在这些项目被初始化之前,slice 为 nil。对于 slice、map 和 channel 来说,make 初始化了内部的数据结构,填充适当的值。
一言以蔽之:make 返回初始化后的(非零)值。
下面这个图详细的解释了 new 和 make 之间的区别。
零值
关于“零值”,所指并非是空值,而是一种“变量未填充前”的默认值,通常为 0。 此处罗列部分类型的“零值”
1
2
3
4
5
6
7
8
9
10
11
| int 0
int8 0
int32 0
int64 0
uint 0x0
rune 0 //rune的实际类型是 int32
byte 0x0 // byte的实际类型是 uint8
float32 0 //长度为 4 byte
float64 0 //长度为 8 byte
bool false
string ""
|
布尔类型的零值(初始值)为 false,数值类型的零值为 0,字符串类型的零值为空字符串 "",而指针、切片、映射、通道、函数和接口的零值则是 nil。
指针 pointer
指针即某个值的地址,类型定义时使用符号 *,对一个已经存在的变量,使用 & 获取该变量的地址。
1
2
3
4
| str := "Golang"
var p *string = &str // p 是指向 str 的指针
*p = "Hello"
fmt.Println(str) // Hello 修改了 p,str 的值也发生了改变
|
一般来说,指针通常在函数传递参数,或者给某个类型定义新的方法时使用。
Go 语言中,参数是按值传递的,如果不使用指针,函数内部将会拷贝一份参数的副本,对参数的修改并不会影响到外部变量的值。如果参数使用指针,对参数的传递将会影响到外部变量。
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| func add(num int) {
num += 1
}
func realAdd(num *int) {
*num += 1
}
func main() {
num := 100
add(num)
fmt.Println(num) // 100,num 没有变化
realAdd(&num)
fmt.Println(num) // 101,指针传递,num 被修改
}
|
- 传指针使得多个函数能操作同一个对象。
- 传指针比较轻量级 (8bytes),只是传内存地址,我们可以用指针传递体积大的结构体。如果用参数值传递的话, 在每次 copy 上面就会花费相对较多的系统开销(内存和时间)。所以当你要传递大的结构体的时候,用指针是一个明智的选择。
- Go 语言中
channel,slice,map 这三种类型的实现机制类似指针,所以可以直接传递,而不用取地址后传递指针。(注:若函数需改变 slice 的长度,则仍需要取地址传递指针)
位运算
| 符号 | 描述 | 运算规则 |
|---|
| & | 与 | 两个位都为 1 时,结果才为 1 |
| | | 或 | 两个位都为 0 时,结果才为 0 |
| ^ | 异或 | 两个位相同为 0,相异为 1 |
| ~ | 取反 | 0 变 1,1 变 0 |
| « | 左移 | 各二进位全部左移若干位,高位丢弃,低位补 0 |
| » | 右移 | 各二进位全部右移若干位,对无符号数,高位补 0,有符号数,各编译器处理方法不一样,有的补符号位(算术右移),有的补 0(逻辑右移) |
按位与
- 清零
- 如果想将一个单元清零,即使其全部二进制位为 0,只要与一个各位都为零的数值相与,结果为零。
- 取一个数的指定位
- 比如取数 X=1010 1110 的低 4 位,只需要另找一个数 Y,令 Y 的低 4 位为 1,其余位为 0,即 Y=0000 1111,然后将 X 与 Y 进行按位与运算(X&Y=0000 1110)即可得到 X 的指定位。
- 判断奇偶
- 只要根据最末位是 0 还是 1 来决定,为 0 就是偶数,为 1 就是奇数。
- 因此可以用
if ((a & 1) == 0) 代替 if (a % 2 == 0) 来判断 a 是不是偶数。
按位或
- 常用来对一个数据的某些位设置为 1
- 比如将数 X=1010 1110 的低 4 位设置为 1,只需要另找一个数 Y,令 Y 的低 4 位为 1,其余位为 0,即 Y=0000 1111,然后将 X 与 Y 进行按位或运算(X|Y=1010 1111)即可得到。
异或
- 异或 1 来翻转指定位
- 比如将数 X=1010 1110 的低 4 位进行翻转,只需要另找一个数 Y,令 Y 的低 4 位为 1,其余位为 0,即 Y=0000 1111,然后将 X 与 Y 进行异或运算(X^Y=1010 0001)即可得到。
- 与 0 相异或值不变
- 例如:1010 1110 ^ 0000 0000 = 1010 1110
- 交换两个数
1
2
3
4
5
6
7
| void Swap(int &a, int &b){
if (a != b){
a ^= b;
b ^= a;
a ^= b;
}
}
|
取反
- 使一个数的最低位为零
- 使 a 的最低位为 0,可以表示为:
a & ~1。~1 的值为 1111 1111 1111 1110,再按 " 与 " 运算,最低位一定为 0。 - 因为 " ~" 运算符的优先级比算术运算符、关系运算符、逻辑运算符和其他运算符都高。
左移
每左移一位,相当于该数乘以 2
右移
每右移一位,相当于该数除以 2
流程控制
条件语句 if else
1
2
3
4
5
6
7
8
9
10
11
12
13
| age := 18
if age < 18 {
fmt.Printf("Kid")
} else {
fmt.Printf("Adult")
}
// 可以简写为:
if age := 18; age < 18 {
fmt.Printf("Kid")
} else {
fmt.Printf("Adult")
}
|
多个条件
1
2
3
4
5
6
7
| if integer == 3 {
fmt.Println("The integer is equal to 3")
} else if integer < 3 {
fmt.Println("The integer is less than 3")
} else {
fmt.Println("The integer is greater than 3")
}
|
goto
Go 有 goto 语句——请明智地使用它。用 goto 跳转到必须在当前函数内定义的标签。例如假设这样一个循环:
1
2
3
4
5
6
7
| func myFunc() {
i := 0
Here: //这行的第一个词,以冒号结束作为标签
println(i)
i++
goto Here //跳转到Here去
}
|
标签名是大小写敏感的。
switch
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| type Gender int8
const (
MALE Gender = 1
FEMALE Gender = 2
)
gender := MALE
switch gender {
case FEMALE:
fmt.Println("female")
case MALE:
fmt.Println("male")
default:
fmt.Println("unknown")
}
// male
|
- 在这里,使用了
type 关键字定义了一个新的类型 Gender。 - 使用 const 定义了 MALE 和 FEMALE 2 个常量,Go 语言中没有枚举 (enum) 的概念,一般可以用常量的方式来模拟枚举。
- 和其他语言不同的地方在于,Go 语言的 switch 不需要 break,匹配到某个 case,执行完该 case 定义的行为后,默认不会继续往下执行。如果需要继续往下执行,需要使用
fallthrough,例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
| switch gender {
case FEMALE:
fmt.Println("female")
fallthrough
case MALE:
fmt.Println("male")
fallthrough
default:
fmt.Println("unknown")
}
// 输出结果
// male
// unknown
|
可以将很多值聚合在一个 case 里
1
2
3
4
5
6
7
8
9
10
11
| i := 10
switch i {
case 1:
fmt.Println("i is equal to 1")
case 2, 3, 4:
fmt.Println("i is equal to 2, 3 or 4")
case 10:
fmt.Println("i is equal to 10")
default:
fmt.Println("All I know is that i is an integer")
}
|
switch 用于判断变量类型
A type switch compares types instead of values. You can use this to discover the type of an interface value. In this example, the variable t will have the type corresponding to its clause.
1
2
3
4
5
6
7
8
9
10
11
12
13
| whatAmI := func(i interface{}) {
switch t := i.(type) {
case bool:
fmt.Println("I'm a bool")
case int:
fmt.Println("I'm an int")
default:
fmt.Printf("Don't know type %T\n", t)
}
}
whatAmI(true)
whatAmI(1)
whatAmI("hey")
|
配合标签
break 语句可以使 switch 提前终止。不仅是 switch, 有时候也必须打破层层的循环。在 Go 中,我们只需将标签放置到循环外,然后 “蹦” 到那里即可。下面的例子展示了二者的用法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| Loop:
for n := 0; n < len(src); n += size {
switch {
case src[n] < sizeOne:
if validateOnly {
break
}
size = 1
update(src[n])
case src[n] < sizeTwo:
if n+1 >= len(src) {
err = errShortInput
break Loop // here, jump to Loop tag
}
if validateOnly {
break
}
size = 2
update(src[n] + src[n+1]<<shift)
}
}
|
当然,continue 语句也能接受一个可选的标签,不过它只能在循环中使用。
for 循环
一个简单的累加的例子,break 和 continue 的用法与其他语言没有区别。
1
2
3
4
5
6
7
| sum := 0
for i := 0; i < 10; i++ {
if sum > 50 {
break
}
sum += i
}
|
当忽略 expression1 和 expression3 时,; 可以省略
1
2
3
4
5
6
7
8
9
| sum := 1
for ; sum < 1000; {
sum += sum
}
// 冒号可以省略
sum := 1
for sum < 1000 {
sum += sum
}
|
break 和 continue 还可以跟着标号,用来跳到多重循环中的外层循环
对数组 (arr)、切片 (slice)、字典 (map) 可以使用 for range 遍历:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| nums := []int{10, 20, 30, 40}
for i, num := range nums {
fmt.Println(i, num)
}
// 0 10
// 1 20
// 2 30
// 3 40
m2 := map[string]string{
"Sam": "Male",
"Alice": "Female",
}
for key, value := range m2 {
fmt.Println(key, value)
}
// Sam Male
// Alice Female
|
函数 functions
参数与返回值
一个典型的函数定义如下,使用关键字 func,参数可以有多个,返回值也支持有多个。特别地,package main 中的 func main() 约定为可执行程序的入口。
1
2
3
4
| func funcName(param1 Type1, param2 Type2, ...) (return1 Type3, ...) {
// body
return value1, value2
}
|
例如,实现 2 个数的加法(一个返回值)和除法(多个返回值):
1
2
3
4
5
6
7
8
9
10
11
12
| func add(num1 int, num2 int) int {
return num1 + num2
}
func div(num1 int, num2 int) (int, int) {
return num1 / num2, num1 % num2
}
func main() {
quo, rem := div(100, 17)
fmt.Println(quo, rem) // 5 15
fmt.Println(add(100, 17)) // 117
}
|
也可以给返回值命名,简化 return,例如 add 函数可以改写为
1
2
3
4
| func add(num1 int, num2 int) (ans int) {
ans = num1 + num2
return
}
|
不建议这样做,虽然使得代码更加简洁了,但是会造成生成的文档可读性差
函数参数的类型默认为离它最近的类型
1
2
3
4
5
6
| func max(a, b int) int {
if a > b {
return a
}
return b
}
|
上述代码中,max 函数有两个参数,它们的类型都是 int,那么第一个变量的类型就可以省略(即 a,b int, 而非 a int, b int)
变参 ...
Go 函数支持变参。接受变参的函数是有着不定数量的参数的。为了做到这点,首先需要定义函数使其接受变参:
1
| func myfunc(arg ...int) {}
|
arg ...int 告诉 Go 这个函数接受不定数量的参数。注意,这些参数的类型全部是 int。在函数体中,变量 arg 是一个 int 的 slice:
1
2
3
| for _, n := range arg {
fmt.Printf("And the number is: %d\n", n)
}
|
延迟语句 defer
Go 语言中有种不错的设计,即延迟(defer)语句,你可以在函数中添加多个 defer 语句。
当函数执行到最后时,这些 defer 语句会按照逆序执行(栈),最后该函数返回。
即:先执行 defer,后返回
特别是当你在进行一些打开资源的操作时,遇到错误需要提前返回,在返回前你需要关闭相应的资源,不然很容易造成资源泄露等问题。
如下代码所示,我们一般写打开一个资源是这样操作的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| func ReadWrite() bool {
file.Open("file")
// 做一些工作
if failureX {
file.Close()
return false
}
if failureY {
file.Close()
return false
}
file.Close()
return true
}
|
我们看到上面有很多重复的代码,Go 的 defer 有效解决了这个问题。使用它后,不但代码量减少了很多,而且程序变得更优雅。在 defer 后指定的函数会在函数退出前调用。
1
2
3
4
5
6
7
8
9
10
11
| func ReadWrite() bool {
file.Open("file")
defer file.Close()
if failureX {
return false
}
if failureY {
return false
}
return true
}
|
如果有很多调用 defer,那么 defer 是采用后进先出模式,所以如下代码会输出 4 3 2 1 0
1
2
3
| for i := 0; i < 5; i++ {
defer fmt.Printf("%d ", i)
}
|
函数作为值、类型
在 Go 中函数也是一种变量,我们可以通过 type 来定义它,它的类型就是所有拥有相同的参数,相同的返回值的一种类型
1
| type typeName func(input1 inputType1 , input2 inputType2 [, ...]) (result1 resultType1 [, ...])
|
将函数作为类型后,可以把这个类型的函数当做值来传递
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| package main
import "fmt"
type testInt func(int) bool // 声明了一个函数类型
func isOdd(integer int) bool {
if integer%2 == 0 {
return false
}
return true
}
func isEven(integer int) bool {
if integer%2 == 0 {
return true
}
return false
}
// 声明的函数类型在这个地方当做了一个参数
func filter(slice []int, f testInt) []int {
var result []int
for _, value := range slice {
if f(value) {
result = append(result, value)
}
}
return result
}
func main(){
slice := []int {1, 2, 3, 4, 5, 7}
fmt.Println("slice = ", slice)
odd := filter(slice, isOdd) // 函数当做值来传递了
fmt.Println("Odd elements of slice are: ", odd)
even := filter(slice, isEven) // 函数当做值来传递了
fmt.Println("Even elements of slice are: ", even)
}
|
函数当做值和类型在我们写一些通用接口的时候非常有用
上面例子中 testInt 类型是一个函数类型,然后两个 filter 函数的参数和返回值与 testInt 类型是一样的,但是我们可以实现很多种的逻辑,这样使得我们的程序变得非常的灵活。
闭包 Closures
Go supports anonymous functions, which can form closures. Anonymous functions are useful when you want to define a function inline without having to name it.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| package main
import "fmt"
func intSeq() func() int {
i := 0
return func() int {
i++
return i
}
}
func main() {
nextInt := intSeq()
fmt.Println(nextInt())
fmt.Println(nextInt())
fmt.Println(nextInt())
newInts := intSeq()
fmt.Println(newInts())
}
/* output:
* 1
* 2
* 3
* 1
|
This function intSeq returns another function, which we define anonymously in the body of intSeq.
The returned function closes over the variable i to form a closure.
We call intSeq, assigning the result (a function) to nextInt. This function value captures its own i value, which will be updated each time we call nextInt.
错误处理 error handling
如果函数实现过程中,如果出现不能处理的错误,可以返回给调用者处理。比如我们调用标准库函数 os.Open 读取文件,os.Open 有 2 个返回值,第一个是 *File,第二个是 error, 如果调用成功,error 的值是 nil,如果调用失败,例如文件不存在,我们可以通过 error 知道具体的错误信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
| import (
"fmt"
"os"
)
func main() {
_, err := os.Open("filename.txt")
if err != nil {
fmt.Println(err)
}
}
// open filename.txt: no such file or directory
|
可以通过 errorw.New 返回自定义的错误
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| import (
"errors"
"fmt"
)
func hello(name string) error {
if len(name) == 0 {
return errors.New("error: name is null")
}
fmt.Println("Hello,", name)
return nil
}
func main() {
if err := hello(""); err != nil {
fmt.Println(err)
}
}
// error: name is null
|
panic 和 recover
error 往往是能预知的错误,但是也可能出现一些不可预知的错误,例如数组越界,这种错误可能会导致程序非正常退出,在 Go 语言中称之为 panic。
Panic
- 它是一个内建函数,可以中断原有的控制流程,进入一个
panic 状态中。 - 当函数
F 调用 panic,函数的执行被中断,但是 F 中的延迟函数 defer 会正常执行,然后 F 返回到调用它的地方。 - 在调用的地方,
F 的行为就像调用了 panic。这一过程继续向上,直到发生 panic 的 goroutine 中所有调用的函数返回,此时程序退出。 panic 可以直接调用 panic 产生。也可以由运行时错误产生,例如访问越界的数组。
Recover
- 它是一个内建的函数,可以让进入
panic 状态的 goroutine 恢复过来。 recover 仅在延迟函数 defer 中有效。- 在正常的执行过程中,调用
recover 会返回 nil,并且没有其它任何效果。 - 如果当前的
goroutine 陷入 panic 状态,调用 recover 可以捕获到 panic 的输入值,并且恢复正常的执行。
例一:下面这个函数演示了如何在过程中使用 panic
1
2
3
4
5
6
7
| var user = os.Getenv("USER")
func init() {
if user == "" {
panic("no value for $USER")
}
}
|
下面这个函数检查作为其参数的函数在执行时是否会产生 panic:
1
2
3
4
5
6
7
8
9
| func throwsPanic(f func()) (b bool) {
defer func() {
if x := recover(); x != nil {
b = true
}
}()
f() //执行函数f,如果f中出现了panic,那么就可以恢复回来
return
}
|
例二:数组越界的情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| func get(index int) int {
arr := [3]int{2, 3, 4}
return arr[index]
}
func main() {
fmt.Println(get(5))
fmt.Println("finished")
}
$ go run .
panic: runtime error: index out of range [5] with length 3
goroutine 1 [running]:
exit status 2
|
使用 panic 和 recover 来捕获错误
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| func get(index int) (ret int) {
defer func() {
if r := recover(); r != nil {
fmt.Println("Some error happened!", r)
ret = -1
}
}()
arr := [3]int{2, 3, 4}
return arr[index]
}
func main() {
fmt.Println(get(5))
fmt.Println("finished")
}
$ go run .
Some error happened! runtime error: index out of range [5] with length 3
-1
finished
|
- 在 get 函数中,使用 defer 定义了异常处理的函数,在协程退出前,会执行完 defer 挂载的任务。因此如果触发了 panic,控制权就交给了 defer。
- 在 defer 的处理逻辑中,使用 recover,使程序恢复正常,并且将返回值设置为 -1,在这里也可以不处理返回值,如果不处理返回值,返回值将被置为默认值 0。
应当在关键的时刻使用 panic 和 recover,而不能滥用
main 函数和 init 函数
Go 里面有两个保留的函数:init 函数(能够应用于所有的 package)和 main 函数(只能应用于 package main)。这两个函数在定义时不能有任何的参数和返回值。
每个 package 中的 init 函数都是可选的,但 package main 必须包含一个 main 函数。
虽然一个 package 里面可以写任意多个 init 函数,但无论是对于可读性还是以后的可维护性来说,建议只写一个 init 函数。
Go 程序会自动调用 init() 和 main(),你不需要在任何地方调用这两个函数。
程序的初始化过程
程序的初始化和执行都起始于 main 包。如果 main 包还导入了其它的包,那么就会在编译时将它们依次导入。
有时一个包会被多个包同时导入,那么它只会被导入一次(例如很多包可能都会用到 fmt 包,但它只会被导入一次,因为没有必要导入多次)。
当一个包被导入时,如果该包还导入了其它的包,那么会先将其它包导入进来,然后再对这些包中的包级常量和变量进行初始化,接着执行 init 函数(如果有的话),依次类推。
等所有被导入的包都加载完毕了,就会开始对 main 包中的包级常量和变量进行初始化,然后执行 main 包中的 init 函数(如果存在的话),最后执行 main 函数。下图详细地解释了整个执行过程:

import
点操作
点操作允许使用省略前缀的包名
别名操作
别名操作允许使用别名来使用包
_ 操作
1
2
3
4
| import (
"database/sql"
_ "github.com/ziutek/mymysql/godrv"
)
|
_ 操作引入了包,而不直接使用包里面的函数,而是调用了该包里面的 init 函数
结构体,方法和接口
结构体 struct
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| package main
import "fmt"
// 声明一个新的类型
type person struct {
name string
age int
}
// 比较两个人的年龄,返回年龄大的那个人,并且返回年龄差
// struct也是传值的
func Older(p1, p2 person) (person, int) {
if p1.age>p2.age { // 比较p1和p2这两个人的年龄
return p1, p1.age-p2.age
}
return p2, p2.age-p1.age
}
func main() {
// 赋值初始化
var tom person
tom.name, tom.age = "Tom", 18
// 两个字段都写清楚的初始化
bob := person{age:25, name:"Bob"}
// 按照struct定义顺序初始化值
paul := person{"Paul", 43}
// 当然也可以通过new函数分配一个指针,此处P的类型为*person
// P := new(person)
tb_Older, tb_diff := Older(tom, bob)
tp_Older, tp_diff := Older(tom, paul)
bp_Older, bp_diff := Older(bob, paul)
fmt.Printf("Of %s and %s, %s is older by %d years\n",
tom.name, bob.name, tb_Older.name, tb_diff)
fmt.Printf("Of %s and %s, %s is older by %d years\n",
tom.name, paul.name, tp_Older.name, tp_diff)
fmt.Printf("Of %s and %s, %s is older by %d years\n",
bob.name, paul.name, bp_Older.name, bp_diff)
}
|
匿名字段
Go 语言支持只提供类型,而不写字段名的方式,也就是匿名字段,或称为嵌入字段。
当匿名字段是一个 struct 的时候,那么这个 struct 所拥有的全部字段以及方法都被隐式地引入了当前定义的这个 struct
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| package main
import "fmt"
type Human struct {
name string
age int
weight int
}
type Student struct {
Human // 匿名字段,那么默认Student就包含了Human的所有字段
speciality string
}
func main() {
// 初始化一个学生
mark := Student{Human{"Mark", 25, 120}, "Computer Science"}
// 访问相应的字段
fmt.Println("His name is ", mark.name)
fmt.Println("His age is ", mark.age)
fmt.Println("His weight is ", mark.weight)
fmt.Println("His speciality is ", mark.speciality)
// 修改对应的备注信息
mark.speciality = "AI"
fmt.Println("Mark changed his speciality")
fmt.Println("His speciality is ", mark.speciality)
// 修改其年龄信息
fmt.Println("Mark become old")
mark.age = 46
fmt.Println("His age is", mark.age)
// 修改其体重信息
fmt.Println("Mark is not an athlet anymore")
mark.weight += 60
fmt.Println("His weight is", mark.weight)
}
|
匿名字段能够实现字段的继承
student 还能访问 Human 这个字段作为字段名。
1
2
| mark.Human = Human{"Marcus", 55, 220}
mark.Human.age -= 1
|
不仅仅是 struct,所有的内置类型和自定义类型都可以作为匿名字段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| package main
import "fmt"
type Skills []string
type Human struct {
name string
age int
weight int
}
type Student struct {
Human // 匿名字段,struct
Skills // 匿名字段,自定义的类型string slice
int // 内置类型作为匿名字段
speciality string
}
func main() {
// 初始化学生Jane
jane := Student{Human:Human{"Jane", 35, 100}, speciality:"Biology"}
// 访问相应的字段
fmt.Println("Her name is ", jane.name)
fmt.Println("Her age is ", jane.age)
fmt.Println("Her weight is ", jane.weight)
fmt.Println("Her speciality is ", jane.speciality)
// 修改其skill技能字段
jane.Skills = []string{"anatomy"}
fmt.Println("Her skills are ", jane.Skills)
fmt.Println("She acquired two new ones ")
jane.Skills = append(jane.Skills, "physics", "golang")
fmt.Println("Her skills now are ", jane.Skills)
// 修改匿名内置类型字段
jane.int = 3
fmt.Println("Her preferred number is", jane.int)
}
|
当存在两个相同的字段时,最外层的优先访问,这就允许我们去重载通过匿名字段继承的一些字段
如果想要访问重载后对应匿名类型里面的字段,可以通过匿名字段名来访问。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| package main
import "fmt"
type Human struct {
name string
age int
phone string // Human类型拥有的字段
}
type Employee struct {
Human // 匿名字段Human
speciality string
phone string // 雇员的phone字段
}
func main() {
Bob := Employee{Human{"Bob", 34, "777-444-XXXX"}, "Designer", "333-222"}
fmt.Println("Bob's work phone is:", Bob.phone)
// 如果我们要访问Human的phone字段
fmt.Println("Bob's personal phone is:", Bob.Human.phone)
}
|
interface 作为匿名字段
详见:https://segmentfault.com/a/1190000018865258
方法 methods
1
| func (r ReceiverType) funcName(parameters) (results)
|
“A method is a function with an implicit first argument, called a receiver.”
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| package main
import (
"fmt"
"math"
)
type Rectangle struct {
width, height float64
}
type Circle struct {
radius float64
}
func (r Rectangle) area() float64 {
return r.width * r.height
}
func (c Circle) area() float64 {
return c.radius * c.radius * math.Pi
}
func main() {
r1 := Rectangle{12, 2}
r2 := Rectangle{9, 4}
c1 := Circle{10}
c2 := Circle{25}
fmt.Println("Area of r1 is: ", r1.area())
fmt.Println("Area of r2 is: ", r2.area())
fmt.Println("Area of c1 is: ", c1.area())
fmt.Println("Area of c2 is: ", c2.area())
}
|
method 可以定义在任何你自定义的类型、内置类型、struct 等各种类型上面。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
| package main
import "fmt"
const(
WHITE = iota
BLACK
BLUE
RED
YELLOW
)
type Color byte
type Box struct {
width, height, depth float64
color Color
}
type BoxList []Box //a slice of boxes
func (b Box) Volume() float64 {
return b.width * b.height * b.depth
}
func (b *Box) SetColor(c Color) {
b.color = c
}
func (bl BoxList) BiggestColor() Color {
v := 0.00
k := Color(WHITE)
for _, b := range bl {
if bv := b.Volume(); bv > v {
v = bv
k = b.color
}
}
return k
}
func (bl BoxList) PaintItBlack() {
for i := range bl {
bl[i].SetColor(BLACK)
}
}
func (c Color) String() string {
strings := []string {"WHITE", "BLACK", "BLUE", "RED", "YELLOW"}
return strings[c]
}
func main() {
boxes := BoxList {
Box{4, 4, 4, RED},
Box{10, 10, 1, YELLOW},
Box{1, 1, 20, BLACK},
Box{10, 10, 1, BLUE},
Box{10, 30, 1, WHITE},
Box{20, 20, 20, YELLOW},
}
fmt.Printf("We have %d boxes in our set\n", len(boxes))
fmt.Println("The volume of the first one is", boxes[0].Volume(), "cm³")
fmt.Println("The color of the last one is",boxes[len(boxes)-1].color.String())
fmt.Println("The biggest one is", boxes.BiggestColor().String())
fmt.Println("Let's paint them all black")
boxes.PaintItBlack()
fmt.Println("The color of the second one is", boxes[1].color.String())
fmt.Println("Obviously, now, the biggest one is", boxes.BiggestColor().String())
}
|
值类型调用与指针类型调用
https://learnku.com/docs/effective-go/2020/method/6245
如果一个 method 的 receiver 是 *T,你可以在一个 T 类型的实例变量 V 上面调用这个 method,而不需要 &V 去调用这个 method
如果一个 method 的 receiver 是 T,你可以在一个 *T 类型的变量 P 上面调用这个 method,而不需要 *P 去调用这个 method
但是一切结果取决于 receiver 的类型
1
2
3
4
5
6
7
8
9
10
11
12
13
| type Data struct {
x int
}
// 值类型调用
func (u User) NotifyValue() {
fmt.Printf("%v : %v \n", u.Name, u.Email)
}
// 指针类型调用
func (u *User) NotifyPointer() {
fmt.Printf("%v : %v \n", u.Name, u.Email)
}
|
当接受者不是一个指针时,方法操作对应接受者的值的副本——即使你使用了指针调用函数,但是函数的接受者是值类型,所以函数内部操作还是对副本的操作,而不是指针操作。
1
2
3
4
5
6
7
8
9
10
11
| func main() {
// 值类型调用方法
u1 := User{"golang", "golang@golang.com"}
u1.NotifyValue() //正常
// 指针类型调用方法
u2 := User{"go", "go@go.com"}
u3 := &u2
// 可以简写成 u3 := &User{"go", "go@go.com"}
u3.NotifyValue() //当我们使用指针时,Go 调整和解引用指针使得调用可以被执行
}
|
同理,当接受者是指针时,即使用值类型调用那么函数内部也是对指针的操作
所以,是值调用还是指针调用,一切取决于接受者的类型
普通函数与方法的区别
- 对于普通函数,接收者为值类型时,不能将指针类型的数据直接传递,反之亦然。
- 对于方法(如 struct 的方法),接收者为值类型时,可以直接用指针类型的变量调用方法,反过来同样也可以。
method 继承
如果匿名字段实现了一个 method,那么包含这个匿名字段的 struct 也能调用该 method
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| package main
import "fmt"
type Human struct {
name string
age int
phone string
}
type Student struct {
Human //匿名字段
school string
}
type Employee struct {
Human //匿名字段
company string
}
//在human上面定义了一个method
func (h *Human) SayHi() {
fmt.Printf("Hi, I am %s you can call me on %s\n", h.name, h.phone)
}
func main() {
mark := Student{Human{"Mark", 25, "222-222-YYYY"}, "MIT"}
sam := Employee{Human{"Sam", 45, "111-888-XXXX"}, "Golang Inc"}
mark.SayHi()
sam.SayHi()
}
|
method 重写
可以在 Employee 上面定义一个 method,重写匿名字段的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
| // Employee的method重写Human的method
func (e *Employee) SayHi() {
fmt.Printf("Hi, I am %s, I work at %s. Call me on %s\n", e.name,
e.company, e.phone) //Yes you can split into 2 lines here.
}
func main() {
mark := Student{Human{"Mark", 25, "222-222-YYYY"}, "MIT"}
sam := Employee{Human{"Sam", 45, "111-888-XXXX"}, "Golang Inc"}
mark.SayHi()
sam.SayHi()
}
|
interface 函数参数
interface 的变量可以持有任意实现该 interface 类型的对象,这给我们编写函数 (包括 method ) 提供了一些额外的思考,我们是不是可以通过定义 interface 参数,让函数接受各种类型的参数。
举个例子:fmt.Println 是我们常用的一个函数,但是它可以接受任意类型的数据。打开 fmt 的源码文件,你会看到这样一个定义:
1
2
3
| type Stringer interface {
String() string
}
|
也就是说,任何实现了 String 方法的类型都能作为参数被 fmt.Println 调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| package main
import (
"fmt"
"strconv"
)
type Human struct {
name string
age int
phone string
}
// 通过这个方法 Human 实现了 fmt.Stringer
func (h Human) String() string {
return "❰"+h.name+" - "+strconv.Itoa(h.age)+" years - ✆ " +h.phone+"❱"
}
func main() {
Bob := Human{"Bob", 39, "000-7777-XXX"}
fmt.Println("This Human is : ", Bob)
}
|
接口 interfaces
一般而言,接口定义了一组方法的集合,我们通过 interface 来定义对象的一组行为。
- 如果某个对象实现了某个接口的所有方法,则此对象就实现了此接口
- 接口不能被实例化
- 一个类型可以实现多个接口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
type Human struct {
name string
age int
phone string
}
type Student struct {
Human //匿名字段Human
school string
loan float32
}
type Employee struct {
Human //匿名字段Human
company string
money float32
}
//Human对象实现Sayhi方法
func (h *Human) SayHi() {
fmt.Printf("Hi, I am %s you can call me on %s\n", h.name, h.phone)
}
// Human对象实现Sing方法
func (h *Human) Sing(lyrics string) {
fmt.Println("La la, la la la, la la la la la...", lyrics)
}
//Human对象实现Guzzle方法
func (h *Human) Guzzle(beerStein string) {
fmt.Println("Guzzle Guzzle Guzzle...", beerStein)
}
// Employee重载Human的Sayhi方法
func (e *Employee) SayHi() {
fmt.Printf("Hi, I am %s, I work at %s. Call me on %s\n", e.name,
e.company, e.phone) //此句可以分成多行
}
//Student实现BorrowMoney方法
func (s *Student) BorrowMoney(amount float32) {
s.loan += amount // (again and again and...)
}
//Employee实现SpendSalary方法
func (e *Employee) SpendSalary(amount float32) {
e.money -= amount // More vodka please!!! Get me through the day!
}
// 定义interface
type Men interface {
SayHi()
Sing(lyrics string)
Guzzle(beerStein string)
}
type YoungChap interface {
SayHi()
Sing(song string)
BorrowMoney(amount float32)
}
type ElderlyGent interface {
SayHi()
Sing(song string)
SpendSalary(amount float32)
}
|
任意的类型都实现了空 interface(我们这样定义:interface{}),也就是包含 0 个方法的 interface。
- 对象不需要显式地声明实现了哪一个接口,只需要直接实现该接口对应的方法即可。
- 如果我们定义了一个 interface 的变量,那么这个变量里面可以存实现这个 interface 的任意类型的对象
总而言之,interface 就是一组抽象方法的集合,它必须由其他非 interface 类型来实现,而不能自我实现; Go 通过 interface 实现了 duck-typing:" 当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子 “。
空接口
如果定义了一个没有任何方法的空接口,那么这个接口可以表示任意类型,有点类似于 C 语言的 void* 类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| func main() {
// 定义a为空接口
var a interface{}
var i int = 5
s := "Hello world"
// a可以存储任意类型的数值
a = i
a = s
m := make(map[string]interface{})
m["name"] = "Tom"
m["age"] = 18
m["scores"] = [3]int{98, 99, 85}
fmt.Println(m) // map[age:18 name:Tom scores:[98 99 85]]
}
|
类型断言
类型断言(Type Assertion)是一个使用在接口值上的操作,用于检查接口类型变量所持有的值是否实现了期望的接口或者具体的类型。
x 表示一个接口的类型,T 表示一个具体的类型(也可为接口类型)。
1
2
3
4
5
6
7
8
9
10
| package main
import (
"fmt"
)
func main() {
var x interface{}
x = 10
value, ok := x.(int)
fmt.Print(value, ",", ok)
}
|
输出
并发编程 goroutine
不要通过共享来通信,而要通过通信来共享
sync
Go 语言提供了 sync 和 channel 两种方式支持协程 (goroutine) 的并发。
例如我们希望并发下载 N 个资源,多个并发协程之间不需要通信,那么就可以使用 sync.WaitGroup,等待所有并发协程执行结束。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func download(url string) {
fmt.Println("start to download", url)
time.Sleep(time.Second) // 模拟耗时操作
wg.Done()
}
func main() {
for i := 0; i < 3; i++ {
wg.Add(1)
go download("a.com/" + string(i+'0'))
}
wg.Wait()
fmt.Println("Done!")
}
|
wg.Add(1):为 wg 添加一个计数,wg.Done(),减去一个计数。go download():启动新的协程并发执行 download 函数。wg.Wait():等待所有的协程执行结束。
1
2
3
4
5
6
7
| $ time go run .
start to download a.com/2
start to download a.com/0
start to download a.com/1
Done!
real 0m1.563s
|
可以看到串行需要 3s 的下载操作,并发后,只需要 1s。
channel
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| var ch = make(chan string, 10) // 创建大小为 10 的缓冲信道
func download(url string) {
fmt.Println("start to download", url)
time.Sleep(time.Second)
ch <- url // 将 url 发送给信道
}
func main() {
for i := 0; i < 3; i++ {
go download("a.com/" + string(i+'0'))
}
for i := 0; i < 3; i++ {
msg := <-ch // 等待信道返回消息。
fmt.Println("finish", msg)
}
fmt.Println("Done!")
}
|
使用 channel 信道,可以在协程之间传递消息。阻塞等待并发协程返回消息。
1
2
3
4
5
6
7
8
9
10
| $ time go run .
start to download a.com/2
start to download a.com/0
start to download a.com/1
finish a.com/2
finish a.com/1
finish a.com/0
Done!
real 0m1.528s
|
单元测试 (unit test)
假设我们希望测试 package main 下 calc.go 中的函数,要只需要新建 calc_test.go 文件,在 calc_test.go 中新建测试用例即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| // calc.go
package main
func add(num1 int, num2 int) int {
return num1 + num2
}
// calc_test.go
package main
import "testing"
func TestAdd(t *testing.T) {
if ans := add(1, 2); ans != 3 {
t.Error("add(1, 2) should be equal to 3")
}
}
|
运行 go test,将自动运行当前 package 下的所有测试用例,如果需要查看详细的信息,可以添加 -v 参数。
1
2
3
4
5
| $ go test -v
=== RUN TestAdd
--- PASS: TestAdd (0.00s)
PASS
ok example 0.040s
|
包 (Package) 和模块 (Modules)
Package
一般来说,一个文件夹可以作为 package,同一个 package 内部变量、类型、方法等定义可以相互看到。
比如我们新建一个文件 calc.go, main.go 平级,分别定义 add 和 main 方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| // calc.go
package main
func add(num1 int, num2 int) int {
return num1 + num2
}
// main.go
package main
import "fmt"
func main() {
fmt.Println(add(3, 5)) // 8
}
|
运行 go run main.go,会报错,add 未定义:
1
| ./main.go:6:14: undefined: add
|
因为 go run main.go 仅编译 main.go 一个文件,所以命令需要换成
1
2
| $ go run main.go calc.go
8
|
或
Go 语言也有 Public 和 Private 的概念,粒度是包。如果类型/接口/方法/函数/字段的首字母大写,则是 Public 的,对其他 package 可见,如果首字母小写,则是 Private 的,对其他 package 不可见。
Modules
Go Modules 是 Go 1.11 版本之后引入的,Go 1.11 之前使用 $GOPATH 机制。
Go Modules 可以算作是较为完善的包管理工具。同时支持代理,国内也能享受高速的第三方包镜像服务。
Go Modules 在 1.13 版本仍是可选使用的,环境变量 GO111MODULE 的值默认为 AUTO,强制使用 Go Modules 进行依赖管理,可以将 GO111MODULE 设置为 ON。
在一个空文件夹下,初始化一个 Module
1
2
| $ go mod init example
go: creating new go.mod: module example
|
此时,在当前文件夹下生成了 go.mod,这个文件记录当前模块的模块名以及所有依赖包的版本。
接着,我们在当前目录下新建文件 main.go,添加如下代码:
1
2
3
4
5
6
7
8
9
10
11
| package main
import (
"fmt"
"rsc.io/quote"
)
func main() {
fmt.Println(quote.Hello()) // Ahoy, world!
}
|
运行 go run .,将会自动触发第三方包 rsc.io/quote 的下载,具体的版本信息也记录在了 go.mod 中:
1
2
3
4
5
| module example
go 1.13
require rsc.io/quote v3.1.0+incompatible
|
我们在当前目录,添加一个子 package calc,代码目录如下:
1
2
3
4
| demo/
|--calc/
|--calc.go
|--main.go
|
在 calc.go 中写入
1
2
3
4
5
| package calc
func Add(num1 int, num2 int) int {
return num1 + num2
}
|
在 package main 中如何使用 package cal 中的 Add 函数呢?import 模块名/子目录名 即可,修改后的 main 函数如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| package main
import (
"fmt"
"example/calc"
"rsc.io/quote"
)
func main() {
fmt.Println(quote.Hello())
fmt.Println(calc.Add(10, 3))
}
$ go run .
Ahoy, world!
13
|
一些技巧和特性
零散的特性
拷贝 slice
两种方法
copy
1
2
3
4
| originalSlice := []int{1, 2, 3, 4, 5}
newSlice := make([]int, len(originalSlice))
copy(newSlice, originalSlice)
|
append
1
2
3
| originalSlice := []int{1, 2, 3, 4, 5}
newSlice := append([]int{}, originalSlice...)
|
分组声明
在 Go 语言中,同时声明多个常量、变量,或者导入多个包时,可采用分组的方式进行声明。
例如下面的代码:
1
2
3
4
5
6
7
8
9
10
| import "fmt"
import "os"
const i = 100
const pi = 3.1415
const prefix = "Go_"
var i int
var pi float32
var prefix string
|
可以分组写成如下形式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import(
"fmt"
"os"
)
const(
i = 100
pi = 3.1415
prefix = "Go_"
)
var(
i int
pi float32
prefix string
)
|
iota 枚举
Go 里面有一个关键字 iota,这个关键字用来声明 enum 的时候采用,它默认开始值是 0,const 中每增加一行加 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| package main
import (
"fmt"
)
const (
x = iota // x == 0
y = iota // y == 1
z = iota // z == 2
w // 常量声明省略值时,默认和之前一个值的字面相同。这里隐式地说w = iota,因此w == 3。其实上面y和z可同样不用"= iota"
)
const v = iota // 每遇到一个const关键字,iota就会重置,此时v == 0
const (
h, i, j = iota, iota, iota //h=0,i=0,j=0 iota在同一行值相同
)
const (
a = iota // a=0
b = "B"
c = iota //c=2
d, e, f = iota, iota, iota //d=3,e=3,f=3
g = iota //g = 4
)
func main() {
fmt.Println(a, b, c, d, e, f, g, h, i, j, x, y, z, w, v)
}
|
除非被显式设置为其它值或 iota,每个 const 分组的第一个常量被默认设置为它的 0 值,第二及后续的常量被默认设置为它前面那个常量的值,如果前面那个常量的值是 iota,则它也被设置为 iota。
变量、函数命名原则
- 大写字母开头的变量是可导出的,也就是其它包可以读取的,是公有变量;小写字母开头的就是不可导出的,是私有变量。
- 大写字母开头的函数也是一样,相当于
class 中的带 public 关键词的公有函数;小写字母开头的就是有 private 关键词的私有函数。
切片中删除元素(已知索引)
Go 语言并没有对删除切片元素提供专用的语法或者接口,需要使用切片本身的特性来删除元素,根据要删除元素的位置有三种情况,分别是从开头位置删除、从中间位置删除和从尾部删除,其中删除切片尾部的元素速度最快。
从开头位置删除
删除开头的元素可以直接移动数据指针:
1
2
| a = []int{1, 2, 3}a = a[1:] // 删除开头1个元素
a = a[N:] // 删除开头N个元素
|
也可以不移动数据指针,但是将后面的数据向开头移动,可以用 append() 原地完成(所谓原地完成是指在原有的切片数据对应的内存区间内完成,不会导致内存空间结构的变化):
1
2
| a = []int{1, 2, 3}a = append(a[:0], a[1:]...) // 删除开头1个元素
a = append(a[:0], a[N:]...) // 删除开头N个元素
|
还可以用 copy() 函数来删除开头的元素:
1
2
| a = []int{1, 2, 3}a = a[:copy(a, a[1:])] // 删除开头1个元素
a = a[:copy(a, a[N:])] // 删除开头N个元素
|
从中间位置删除
对于删除中间的元素,需要对剩余的元素进行一次整体挪动,同样可以用 append() 或 copy() 原地完成:
1
2
3
4
5
| a = []int{1, 2, 3, ...}a = append(a[:i], a[i+1:]...) // 删除中间1个元素
a = append(a[:i], a[i+N:]...) // 删除中间N个元素
a = a[:i+copy(a[i:], a[i+1:])] // 删除中间1个元素
a = a[:i+copy(a[i:], a[i+N:])] // 删除中间N个元素
|
从尾部删除
1
2
3
| a = []int{1, 2, 3}
a = a[:len(a)-1] // 删除尾部1个元素
a = a[:len(a)-N] // 删除尾部N个元素
|
删除开头的元素和删除尾部的元素都可以认为是删除中间元素操作的特殊情况,下面来看一个示例。
示例:删除切片指定位置的元素。
1
2
3
4
5
6
7
8
9
| package main
import "fmt"
func main() {
seq := []string{"a", "b", "c", "d", "e"} // 指定删除位置
index := 2 // 查看删除位置之前的元素和之后的元素
fmt.Println(seq[:index], seq[index+1:]) // 将删除点前后的元素连接起来
seq = append(seq[:index], seq[index+1:]...)
fmt.Println(seq)
}
|
类型选择
switch 也可用于判断接口变量的动态类型。如 类型选择 通过圆括号中的关键字 type 使用类型断言语法。若 switch 在表达式中声明了一个变量,那么该变量的每个子句中都将有该变量对应的类型。在每一个 case 子句中,重复利用该变量名字也是惯常的做法,实际上这是在每一个 case 子句中,分别声明一个拥有相同名字,但类型不同的新变量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| var t interface{}
t = functionOfSomeType()
switch t := t.(type) {
default:
fmt.Printf("unexpected type %T\n", t) // %T 打印任何类型的 t
case bool:
fmt.Printf("boolean %t\n", t) // t 是 bool 类型
case int:
fmt.Printf("integer %d\n", t) // t 是 int 类型
case *bool:
fmt.Printf("pointer to boolean %t\n", *t) // t 是 *bool 类型
case *int:
fmt.Printf("pointer to integer %d\n", *t) // t 是 *int 类型
}
|
判断 map 中是否存在某键
1
2
3
| if seconds, ok := timeZone[tz]; ok {
return t
}
|
init 函数
每个源文件都可以通过定义自己的无参数 init 函数来设置一些必要的状态。 (其实每个文件都可以拥有多个 init 函数。)而它的结束就意味着初始化结束: 只有该包中的所有变量声明都通过它们的初始化器求值后 init 才会被调用, 而包中的变量只有在所有已导入的包都被初始化后才会被求值。
除了那些不能被表示成声明的初始化外,init 函数还常被用在程序真正开始执行前,检验或校正程序的状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
| func init() {
if user == "" {
log.Fatal("$USER not set")
}
if home == "" {
home = "/home/" + user
}
if gopath == "" {
gopath = home + "/go"
}
// gopath 可通过命令行中的 --gopath 标记覆盖掉。
flag.StringVar(&gopath, "gopath", gopath, "override default GOPATH")
}
|
runtime.Caller()
报告当前 go 程调用栈所执行的函数的文件和行号信息
获取(调用处)上 n 个函数的信息,像一个栈
1
| func Caller(skip int) (pc uintptr, file string, line int, ok bool)
|
参数
使用空白标识符进行接口检查
1
| var _ json.Marshaler = (*RawMessage)(nil)
|
在此声明中,我们调用了一个 *RawMessage 转换并将其赋予了 Marshaler,以此来*要求 RawMessage 实现 Marshaler,这时其属性就会在编译时被检测。
若 json.Marshaler 接口被更改,此包将无法通过编译, 而我们则会注意到它需要更新。
在这种结构中出现空白标识符,即表示该声明的存在只是为了类型检查。
不过请不要为满足接口就将它用于任何类型。作为约定, 只有当代码中不存在静态类型转换时才能使用这种声明,毕竟这是种非常罕见的情况。
make 和 new 的区别
可以参考:https://learnku.com/docs/effective-go/2020/data/6243
make 的作用是初始化内置的数据结构,也就是我们在前面提到的切片、哈希表和 Channelnew 的作用是根据传入的类型分配一片内存空间并返回指向这片内存空间的指针- 表达式
new(File) 和 &File{} 是等价的。
解决 Go 的相对路径问题
获取当前可执行文件路径
将配置文件的相对路径与 GetAppPath() 的结果相拼接,可解决 go build main.go 的可执行文件跨目录执行的问题(如:go build ./src/gin-blog/main.go)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import (
"path/filepath"
"os"
"os/exec"
"string"
)
func GetAppPath() string {
file, _ := exec.LookPath(os.Args[0])
path, _ := filepath.Abs(file)
index := strings.LastIndex(path, string(os.PathSeparator))
return path[:index]
}
|
但是这种方式,对于 go run 依旧无效。因为 go run 执行时会将文件放到 /tmp/go-build... 目录下,编译并运行:
Run compiles and runs the main package comprising the named Go source files.
A Go source file is defined to be a file ending in a literal “.go” suffix.
通过传递参数指定路径,可解决 go run 的问题
1
2
3
4
5
6
7
8
9
10
11
12
13
| package main
import (
"flag"
"fmt"
)
func main() {
var appPath string
flag.StringVar(&appPath, "app-path", "app-path")
flag.Parse()
fmt.Printf("App path: %s", appPath)
}
|
1
| go run main.go --app-path "Your project address"
|
增加 os.Getwd() 进行多层判断
参见 beego 读取 app.conf 的代码
该写法可兼容 go build 和在项目根目录执行 go run ,但是若跨目录执行 go run 就不行
配置全局系统变量
我们可以通过 os.Getenv 来获取系统全局变量,然后与相对路径进行拼接
1、 设置项目工作区
简单来说,就是设置项目(应用)的工作路径,然后与配置文件、日志文件等相对路径进行拼接,达到相对的绝对路径来保证路径一致
参见 gogs 读取 GOGS_WORK_DIR 进行拼接的代码
2、 利用系统自带变量
简单来说就是通过系统自带的全局变量,例如 $HOME 等,将配置文件存放在 $HOME/conf 或 /etc/conf 下
这样子就能更加固定的存放配置文件,不需要额外去设置一个环境变量
go test 在一些场景下也会遇到路径问题,因为 go test 只能够在当前目录执行,所以在执行测试用例的时候,你的执行目录已经是测试目录了
包装错误
使用 errors.Wrap
1
| errors.Wrap(err, "additional message to a given error")
|
不要忘记为 iota 指定一种类型
1
2
3
4
| const (
_ = iota
testvar // testvar 将是 int 类型
)
|
vs
1
2
3
4
5
| type myType int
const (
_ myType = iota
testvar // testvar 将是 myType 类型
)
|
防止结构体字段用纯值方式初始化,添加 _ struct {} 字段:
当你的结构体要求强制给出所有参数才允许初始化时:
1
2
3
4
| type Point struct {
X, Y float64
_ struct{} // to prevent unkeyed literals
}
|
上例结构体的初始化,允许有 Point {X:1,Y:1} ,但是对于 Point {1,1} 则会出现编译错误:
1
| ./file.go:1:11: too few values in Point literal
|
当在你所有的结构体中添加了 _ struct{} 后,使用 go vet 命令进行检查,(原来声明的方式)就会提示没有足够的参数。
二维数组的创建方法
有时必须分配一个二维数组,例如在处理像素的扫描行时,这种情况就会发生。 我们有两种方式来达到这个目的。
- 独立地分配每一个切片;
- 只分配一个数组, 将各个切片都指向它。
采用哪种方式取决于你的应用。若切片会增长或收缩, 就应该通过独立分配来避免覆盖下一行;若不会,用单次分配来构造对象会更加高效。
一次一行:
1
2
3
4
5
6
| // 分配底层切片.
picture := make([][]uint8, YSize) // y每一行的大小
//循环遍历每一行
for i := range picture {
picture[i] = make([]uint8, XSize)
}
|
一次分配,对行进行切片:
1
2
3
4
5
6
7
8
| // 分配底层切片
picture := make([][]uint8, YSize) // 每 y 个单元一行。
// 分配一个大一些的切片以容纳所有的元素
pixels := make([]uint8, XSize*YSize) // 指定类型[]uint8, 即便图片是 [][]uint8.
//循环遍历图片所有行,从剩余像素切片的前面对每一行进行切片。
for i := range picture {
picture[i], pixels = pixels[:XSize], pixels[XSize:]
}
|
集合的实现
集合可实现成一个值类型为 bool 的映射。将该映射中的项置为 true 可将该值放入集合中,此后通过简单的索引操作即可判断是否存在。
1
2
3
4
5
6
7
8
9
| attended := map[string]bool{
"Ann": true,
"Joe": true,
...
}
if attended[person] { // person不在集合中,返回 false
fmt.Println(person, "was at the meeting")
}
|
字符串拼接的 7 种姿势
String Concat
简单
String Sprintf
1
| str = fmt.Sprintf("%s%s", str, "test-string")
|
String Join
1
| str = strings.Join([]string{str, "test-string"}, "")
|
Buffer Write
1
2
3
| buf := new(bytes.Buffer)
buf.WriteString("test-string")
str := buf.String()
|
Bytes Append
1
2
3
4
| var b []byte
s := "test-string"
b = append(b, s...)
str := string(b)
|
String Copy
奇奇怪怪,但是快
1
2
3
4
5
6
7
8
9
10
11
| ts := "test-string"
n := 5
tsl := len(ts) * n
bs := make([]byte, tsl)
bl := 0
for bl < tsl {
bl += copy(bs[bl:], ts)
}
str := string(bs)
|
String Builder
好用
1
2
3
| var builder strings.Builder
builder.WriteString("test-string")
str := builder.String()
|
性能测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
| package main
import (
"bytes"
"fmt"
"strings"
"testing"
)
const (
sss = "hello world!"
cnt = 10000
)
var expected = strings.Repeat(sss, cnt)
func BenchmarkStringConcat(b *testing.B) {
var result string
for n := 0; n < b.N; n++ {
var str string
for i := 0; i < cnt; i++ {
str += sss
}
result = str
}
b.StopTimer()
if result != expected {
b.Errorf("unexpected result; got=%s, want=%s", string(result), expected)
}
}
func BenchmarkStringSprintf(b *testing.B) {
var result string
for n := 0; n < b.N; n++ {
var str string
for i := 0; i < cnt; i++ {
str = fmt.Sprintf("%s%s", str, sss)
}
result = str
}
b.StopTimer()
if result != expected {
b.Errorf("unexpected result; got=%s, want=%s", string(result), expected)
}
}
func BenchmarkStringJoin(b *testing.B) {
var result string
for n := 0; n < b.N; n++ {
var str string
for i := 0; i < cnt; i++ {
str = strings.Join([]string{str, sss}, "")
}
result = str
}
b.StopTimer()
if result != expected {
b.Errorf("unexpected result; got=%s, want=%s", string(result), expected)
}
}
func BenchmarkBufferWrite(b *testing.B) {
var result string
for n := 0; n < b.N; n++ {
buf := new(bytes.Buffer)
for i := 0; i < cnt; i++ {
buf.WriteString(sss)
}
result = buf.String()
}
b.StopTimer()
if result != expected {
b.Errorf("unexpected result; got=%s, want=%s", string(result), expected)
}
}
func BenchmarkBytesAppend(b *testing.B) {
var result string
for n := 0; n < b.N; n++ {
var bbb []byte
for i := 0; i < cnt; i++ {
bbb = append(bbb, sss...)
}
result = string(bbb)
}
b.StopTimer()
if result != expected {
b.Errorf("unexpected result; got=%s, want=%s", string(result), expected)
}
}
func BenchmarkStringCopy(b *testing.B) {
var result string
for n := 0; n < b.N; n++ {
tsl := len(sss) * cnt
bs := make([]byte, tsl)
bl := 0
for bl < tsl {
bl += copy(bs[bl:], sss)
}
result = string(bs)
}
b.StopTimer()
if result != expected {
b.Errorf("unexpected result; got=%s, want=%s", string(result), expected)
}
}
func BenchmarkStringBuilder(b *testing.B) {
var result string
for n := 0; n < b.N; n++ {
var builder strings.Builder
for i := 0; i < cnt; i++ {
builder.WriteString(sss)
}
result = builder.String()
}
b.StopTimer()
if result != expected {
b.Errorf("unexpected result; got=%s, want=%s", string(result), expected)
}
}
|
测试结果:
BenchmarkStringConcat-4 19 61431933 ns/op 632845167 B/op 10005 allocs/op BenchmarkStringSprintf-4 10 109283838 ns/op 1075688336 B/op 29688 allocs/op BenchmarkStringJoin-4 15 75854431 ns/op 632844905 B/op 10003 allocs/op BenchmarkBufferWrite-4 10743 113597 ns/op 441616 B/op 13 allocs/op BenchmarkBytesAppend-4 15578 73796 ns/op 645104 B/op 24 allocs/op BenchmarkStringCopy-4 21416 55761 ns/op 245760 B/op 2 allocs/op BenchmarkStringBuilder-4 15961 74010 ns/op 522224 B/op 23 allocs/op
从测试结果来看,语法中的字符串拼接操作性能是极其低下的,对于操作频繁的大字符串,我们需考虑用更高效的方式替代。
⭐ 函数传参
Go 语言中所有的传参都是值传递(传值),都是一个副本,一个拷贝。且传参和赋值(=)的操作本质是一样的。
拷贝的内容分为 非引用类型 和 引用类型 两种类型
- 非引用类型:int、string、struct、array 这样就不能修改原内容数据。
- 引用类型:指针、map、slice、chan ,这样就可以修改原内容数据。
⭐ 切片传参时要注意扩容的影响
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| package main
import "fmt"
func Add2Slice(s []int, t int) {
s[0]++
s = append(s, t) // 扩容
s[0]++
}
func main() {
a := []int{0, 1, 2, 3}
Add2Slice(a, 4)
fmt.Println(a)
}
// output
// {1, 1, 2, 3}
// 而不是 {2, 1, 2, 3}
|
slice 会有个长度和容量。如果没有足够可用的容量,append 函数会创建一个新的底层数组,拷贝已存在的值和将要被附加的新值。
append 函数重新创建底层数组时:
- 元素个数小于 1000,容量会是现有元素的 2 倍
- 元素个数超过 1000,容量会是现有元素的 1.25 倍
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| package main
import "fmt"
func Add2Slice(s *[]int, t int) { // 传指针
// *s[0]++ /* 报错 */
*s = append(*s, t)
// s[0]++
}
func main() {
a := []int{0, 1, 2, 3}
Add2Slice(&a, 4)
fmt.Println(a)
}
// output
// {0, 1, 2, 3, 4}
|
处理 map 和 slice 的并发写
加锁
n 个 goroutine 都有可能执行写入操作,保证同一时间只能有一个在执行写操作。 加锁操作简单,适用于性能要求低和逻辑不复杂的场景。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| package main
import (
"fmt"
"sync"
)
func main() {
slc := []int{}
n := 10000
var wg sync.WaitGroup
var lock sync.Mutex
wg.Add(n)
for i := 0; i < n; i++ {
go func(a int) {
lock.Lock()
slc = append(slc, a)
lock.Unlock()
wg.Done()
}(i)
}
wg.Wait()
fmt.Println("done len:", len(slc))
}
|
Active Object 方式
本质上 n 个 goroutine 的写操作全部被写到了 channel 里,channel 里的数据再通过循环一个一个写入 slice/map 中
所以同一时间,只有 1 个 goroutine 在执行写操作。避免多个 goroutine 竞争锁。 适合业务场景复杂,性能要求高的场景。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
| package main
import (
"fmt"
"sync"
)
// active object对象
type Service struct {
channel chan int `desc:"即将加入到数据slice的数据"`
data []int `desc:"数据slice"`
}
// 新建一个size大小缓存的active object对象
func NewService(size int, done func()) *Service {
s := &Service{
channel: make(chan int, size),
data: make([]int, 0),
}
go func() {
s.schedule()
done()
}()
return s
}
// 把管道中的数据append到slice中
func (s *Service) schedule() {
for v := range s.channel {
s.data = append(s.data, v)
}
}
// 增加一个值
func (s *Service) Add(v int) {
s.channel <- v
}
// 管道使用完关闭
func (s *Service) Close() {
close(s.channel)
}
// 返回slice
func (s *Service) Slice() []int {
return s.data
}
func main() {
// 1. 新建一个active object, 并增加结束信号
c := make(chan struct{})
s := NewService(100, func() { c <- struct{}{} })
// 2. 起n个goroutine不断执行增加操作
n := 10000
var wg sync.WaitGroup
wg.Add(n)
for i := 0; i < n; i++ {
go func(a int) {
s.Add(a)
wg.Done()
}(i)
}
wg.Wait()
s.Close()
<-c
// 3. 校验所有结果是否都被添加上
fmt.Println("done len:", len(s.Slice()))
}
|



