Go 专家编程
进阶
编译原理
Token -> 语法树 AST -> 中间码 -> 机器码
词法与语法分析
词法分析的作用就是解析源代码文件,它将文件中的字符串序列转换成 Token 序列,方便后面的处理和解析
语法分析器会按照顺序解析 Token 序列,并转换成语法树
该过程会将词法分析生成的 Token 按照编程语言定义好的文法(Grammar)自下而上或者自上而下的规约,每一个 Go 的源代码文件最终会被归纳成一个 SourceFile 结构
1SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
词法分析会返回一个不包含空格、换行等字符的 Token 序列,例如:
package, json, import, (, io, ), …,而语法分析会把 Token 序列转换成有意义的结构体,即语法树:1 2 3 4 5 6 7"json.go": SourceFile { PackageName: "json", ImportDecl: []Import{ "io", }, TopLevelDecl: ... }语法解析的过程中发生的任何语法错误都会被语法解析器发现并将消息打印到标准输出上,整个编译过程也会随着错误的出现而被中止。
类型检查
Go 语言的编译器会对语法树中定义和使用的类型进行检查,类型检查会按照以下的顺序分别验证和处理不同类型的节点:
- 常量、类型和函数名及类型;
- 变量的赋值和初始化;
- 函数和闭包的主体;
- 哈希键值对的类型;
- 导入函数体;
- 外部的声明;
通过对整棵抽象语法树的遍历,我们在每个节点上都会对当前子树的类型进行验证,以保证节点不存在类型错误,所有的类型错误和不匹配都会在这一个阶段被暴露出来,其中包括:结构体对接口的实现。
类型检查阶段不止会对节点的类型进行验证,还会展开和改写一些内建的函数,例如 make 关键字在这个阶段会根据子树的结构被替换成
runtime.makeslice或者runtime.makechan等函数。
中间代码生成
- 当我们将源文件转换成了抽象语法树、对整棵树的语法进行解析并进行类型检查之后,就可以认为当前文件中的代码不存在语法错误和类型错误的问题了,Go 语言的编译器就会将输入的抽象语法树转换成中间代码。
- 在类型检查之后,编译器会通过
cmd/compile/internal/gc.compileFunctions编译整个 Go 语言项目中的全部函数,这些函数会在一个编译队列中等待几个 Goroutine 的消费,并发执行的 Goroutine 会将所有函数对应的抽象语法树转换成中间代码。 - 由于 Go 语言编译器的中间代码使用了 SSA 的特性,所以在这一阶段我们能够分析出代码中的无用变量和片段并对代码进行优化
机器码生成
- Go 语言源代码的
src/cmd/compile/internal目录中包含了很多机器码生成相关的包,不同类型的 CPU 分别使用了不同的包生成机器码,其中包括 amd64、arm、arm64、mips、mips64、ppc64、s390x、x86 和 wasm
- Go 语言源代码的
数据结构
chan
环形队列、两个等待队列
src/runtime/chan.go:hchan 定义了 channel 的数据结构:
| |
结构
环形队列
chan 内部实现了一个环形队列作为其缓冲区,队列的长度是创建 chan 时指定的。
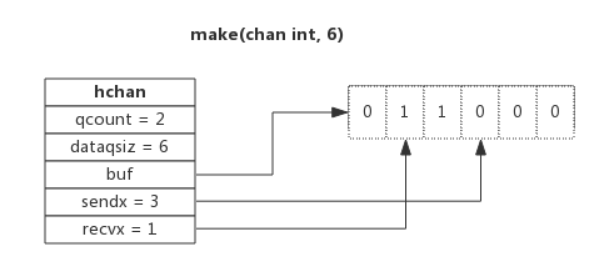
dataqsiz指示了队列长度为 6,即可缓存 6 个元素;buf指向队列的内存,队列中还剩余两个元素;qcount表示队列中还有两个元素;sendx指示后续写入的数据存储的位置,取值[0, 6);recvx指示从该位置读取数据, 取值[0, 6)
等待队列
从 channel 读数据,如果 channel 缓冲区为空或者没有缓冲区,当前 goroutine 会被阻塞。
向 channel 写数据,如果 channel 缓冲区已满或者没有缓冲区,当前 goroutine 会被阻塞。
被阻塞的 goroutine 将会挂在 channel 的等待队列中:
- 因读阻塞的 goroutine 会被向 channel 写入数据的 goroutine 唤醒;
- 因写阻塞的 goroutine 会被从 channel 读数据的 goroutine 唤醒;
下图展示了一个没有缓冲区的 channel,有几个 goroutine 阻塞等待读数据:
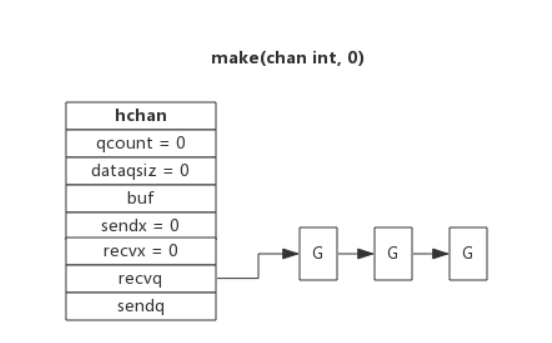
注意,一般情况下 recvq 和 sendq 至少有一个为空。只有一个例外,那就是同一个 goroutine 使用 select 语句向 channel 一边写数据,一边读数据(?
类型信息
一个 channel 只能传递一种类型的值,类型信息存储在 hchan 数据结构中。
elemtype代表类型,用于数据传递过程中的赋值;elemsize代表类型大小,用于在buf中定位元素位置。
锁
channel 不支持并发读写,一个 channel 同时仅允许被一个 goroutine 读写,为简单起见,后续部分说明读写过程时不再涉及加锁和解锁。
channel 操作
创建
创建 channel 的过程实际上是初始化 hchan 结构。其中类型信息和缓冲区长度由 make 语句传入,buf 的大小则与元素大小和缓冲区长度共同决定。
创建 channel 的伪代码如下所示:
| |
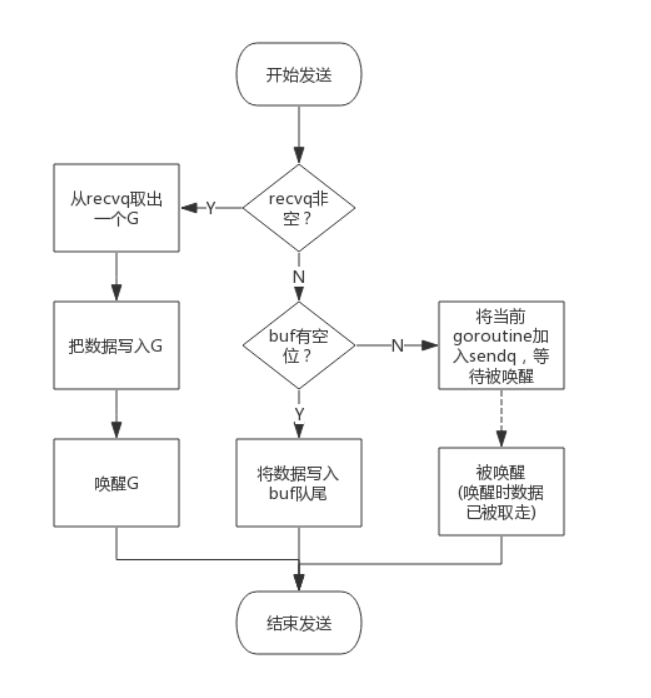
向 channel 中写
向一个 channel 中写数据简单过程如下:
- 如果等待接收队列
recvq不为空,说明缓冲区中没有数据或者没有缓冲区,此时直接从recvq取出 G,并把数据写入,最后把该 G 唤醒,结束发送过程; - 如果缓冲区中有空余位置,将数据写入缓冲区,结束发送过程;
- 如果缓冲区中没有空余位置,将待发送数据写入 G,将当前 G 加入
sendq,进入睡眠,等待被读 goroutine 唤醒;
简单流程图如下:
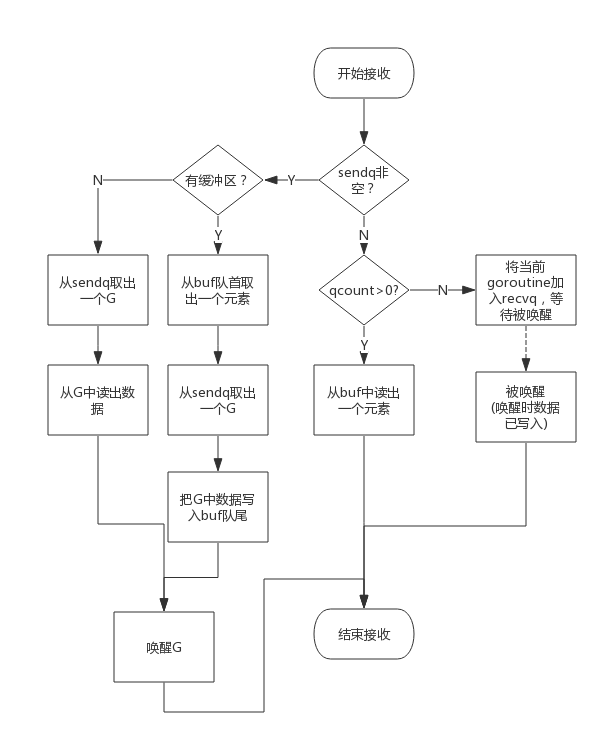
向 channel 中读
从一个 channel 读数据简单过程如下:
- 如果等待发送队列 sendq 不为空,且没有缓冲区,直接从 sendq 中取出 G,把 G 中数据读出,最后把 G 唤醒,结束读取过程;
- 如果等待发送队列 sendq 不为空,此时说明缓冲区已满,从缓冲区中首部读出数据,把 G 中数据写入缓冲区尾部,把 G 唤醒,结束读取过程;
- 如果缓冲区中有数据,则从缓冲区取出数据,结束读取过程;
- 将当前 goroutine 加入
recvq,进入睡眠,等待被写 goroutine 唤醒;
简单流程图如下:
关闭
关闭 channel 时会把 recvq 中的 G 全部唤醒,本该写入 G 的数据位置为 nil。
把 sendq 中的 G 全部唤醒,但这些 G 会 panic。
除此之外,panic 出现的常见场景还有:
- 关闭值为 nil 的 channel
- 关闭已经被关闭的 channel
- 向已经关闭的 channel 写数据
常见用法
单项 channel
顾名思义,单向 channel 指只能用于发送或接收数据,实际上也没有单向 channel。
我们知道 channel 可以通过参数传递,所谓单向 channel 只是对 channel 的一种使用限制,这跟 C 语言使用 const 修饰函数参数为只读是一个道理。
func readChan(chanName <-chan int): 通过形参限定函数内部只能从 channel 中读取数据func writeChan(chanName chan<- int): 通过形参限定函数内部只能向 channel 中写入数据
一个简单的示例程序如下:
| |
mychan 是个正常的 channel,而 readChan() 参数限制了传入的 channel 只能用来读,writeChan() 参数限制了传入的 channel 只能用来写。
select
使用 select 可以监控多 channel,比如监控多个 channel,当其中某一个 channel 有数据时,就从其读出数据。
一个简单的示例程序如下:
| |
程序中创建两个 channel: chan1 和 chan2。函数 addNumberToChan() 函数会向两个 channel 中周期性写入数据。通过 select 可以监控两个 channel,任意一个可读时就从其中读出数据。
程序输出如下:
| |
从输出可见,从 channel 中读出数据的顺序是随机的,事实上 select 语句的多个 case 执行顺序是随机的。
range
通过 range 可以持续从 channel 中读出数据,好像在遍历一个数组一样,当 channel 中没有数据时会阻塞当前 goroutine,与读 channel 时阻塞处理机制一样。
| |
注意:如果向此 channel 写数据的 goroutine 退出时,系统检测到这种情况后会 panic,否则 range 将会永久阻塞。
slice
Slice 依托数组实现,底层数组对用户屏蔽,在底层数组容量不足时可以实现自动重分配并生成新的 Slice。
源码包中 src/runtime/slice.go:slice 定义了 Slice 的数据结构:
| |
从数据结构看 Slice 很清晰,array 指针指向底层数组,len 表示切片长度,cap 表示底层数组容量。
使用 make 创建 Slice
使用 make 来创建 Slice 时,可以同时指定长度和容量,创建时底层会分配一个数组,数组的长度即容量。
例如,语句 slice := make([]int, 5, 10) 所创建的 Slice,结构如下图所示:

该 Slice 长度为 5,即可以使用下标 slice[0] ~ slice[4] 来操作里面的元素,capacity 为 10,表示后续向 slice 添加新的元素时可以不必重新分配内存,直接使用预留内存即可。
使用数组创建 Slice
使用数组来创建 Slice 时,Slice 将与原数组共用一部分内存。
例如,语句 slice := array[5:7] 所创建的 Slice,结构如下图所示:

切片从数组 array[5] 开始,到数组 array[7] 结束(不含 array[7]),即切片长度为 2,数组后面的内容都作为切片的预留内存,即 capacity 为 5。
数组和切片操作可能作用于同一块内存,这也是使用过程中需要注意的地方。
Slice 扩容
使用 append 向 Slice 追加元素时,如果 Slice 空间不足,将会触发 Slice 扩容
扩容实际上重新一配一块更大的内存,将原 Slice 数据拷贝进新 Slice,然后返回新 Slice,扩容后再将数据追加进去。
例如,当向一个 capacity 为 5,且 length 也为 5 的 Slice 再次追加 1 个元素时,就会发生扩容,如下图所示:

扩容操作只关心容量,会把原 Slice 数据拷贝到新 Slice,追加数据由 append() 在扩容结束后完成。
上图可见,扩容后新的 Slice 长度仍然是 5,但容量由 5 提升到了 10,原 Slice 的数据也都拷贝到了新 Slice 指向的数组中。
⭐ 扩容容量的选择遵循以下规则:
当新 Slice 需要的容量大于原 Slice 容量的两倍,则直接按照新切片需要的容量扩容;
如果原 Slice 容量小于 1024,则新 Slice 容量将扩大为原来的 2 倍;
如果原 Slice 容量大于等于 1024,则新 Slice 容量将扩大为原来的 1.25 倍;

使用 append() 向 Slice 添加一个元素的实现步骤如下:
- 假如 Slice 容量够用,则将新元素追加进去,
Slice.len++,返回原 Slice - 原 Slice 容量不够,则
- 将 Slice 先扩容,扩容后得到新 Slice
- 将新元素追加进新 Slice,
Slice.len++,返回新的 Slice。
Slice Copy
使用 copy() 内置函数拷贝两个切片时,会将源切片的数据逐个拷贝到目的切片指向的数组中,拷贝数量取两个切片长度的最小值。
例如长度为 10 的切片拷贝到长度为 5 的切片时,将会拷贝 5 个元素。
也就是说,copy 过程中不会发生扩容。
特殊切片
跟据数组或切片生成新的切片一般使用 slice := array[start:end] 方式,这种新生成的切片并没有指定切片的容量,实际上新切片的容量是从 start 开始直至 array 的结束。
比如下面两个切片,长度和容量都是一致的,使用共同的内存地址:
| |
根据数组或切片生成切片还有另一种写法,即切片同时也指定容量,即 slice[start:end:cap], 其中 cap 即为新切片的容量,当然容量不能超过原切片实际值,如下所示:
| |
这切片方法不常见,在 Golang 源码里能够见到,不过非常利于切片的理解。
Tips
- 创建切片时可跟据实际需要预分配容量,尽量避免追加过程中扩容操作,有利于提升性能;
- 切片拷贝时需要判断实际拷贝的元素个数
- ⭐ 谨慎使用多个切片操作同一个数组,以防读写冲突(slice 和 map 都不是并发安全的)
总结
- 每个切片都指向一个底层数组
- 每个切片都保存了当前切片的长度、底层数组可用容量
- 使用
len()计算切片长度时间复杂度为 O(1),不需要遍历切片 - 使用
cap()计算切片容量时间复杂度为 O(1),不需要遍历切片 - 通过函数传递切片时,不会拷贝整个切片,因为切片本身只是个结构体而已
- 使用
append()向切片追加元素时有可能触发扩容,扩容后将会生成新的切片
map
buckets:8个键值对、overflow、哈希值低位找桶高位找 key
扩容:增量扩容(负载因子太高、翻倍),等量扩容(overflow太多)

Golang 的 map 使用哈希表作为底层实现,一个哈希表里可以有多个哈希表节点,也即 bucket,而每个 bucket 就保存了 map 中的一个或一组键值对。
map 数据结构由 runtime/map.go/hmap 定义:
| |
下图展示一个拥有 4 个 bucket 的 map:

本例中, hmap.B=2, 而 hmap.buckets 长度是 2^B^ 为 4。元素经过哈希运算后会落到某个 bucket 中进行存储。查找过程类似。
bucket 很多时候被翻译为桶,所谓的哈希桶实际上就是 bucket。
哈希函数对传进来的 key 进行哈希运算,得到一个唯一的值:
- 低位用于寻找当前 key 属于
hmap中的哪个 bucket - 高位用于寻找 bucket 中的哪个 key。

bucket 数据结构
bucket 数据结构由 runtime/map.go/bmap 定义:
| |
每个 bucket 可以存储 8 个键值对。
tophash是个长度为 8 的数组,哈希值相同的键(准确的说是哈希值低位相同的键)存入当前 bucket 时会将哈希值的高位存储在该数组中,以方便后续匹配。data区存放的是 key-value 数据,存放顺序是 key/key/key/…value/value/value,如此存放是为了节省字节对齐带来的空间浪费。overflow指针指向的是下一个 bucket,据此将所有冲突的键连接起来。
注意:上述中 data 和 overflow 并不是在结构体中显示定义的,而是直接通过指针运算(计算内存地址)进行访问的。我们能根据编译期间的 cmd/compile/internal/gc.bmap 函数重建它的结构:
| |
下图展示 bucket 存放 8 个 key-value 对:

哈希冲突
当有两个或以上数量的键被哈希到了同一个 bucket 时,我们称这些键发生了冲突。Go 使用链地址法(拉链法)来解决键冲突。 由于每个 bucket 可以存放 8 个键值对,所以同一个 bucket 存放超过 8 个键值对时就会再创建一个 bucket,用类似链表的方式将 bucket 连接起来。
下图展示产生冲突后的 map:

bucket 数据结构指示下一个 bucket 的指针称为 overflow bucket(溢出桶),意为当前 bucket 盛不下而溢出的部分。溢出桶的内存布局与常规桶相同,是为了减少扩容次数而引入的。
当一个桶存满了,还有可用的溢出桶时,就会在后面链一个溢出桶,继续往这里面存(没有可用的溢出桶时就扩容吧)
事实上哈希冲突并不是好事情,它降低了存取效率,好的哈希算法可以保证哈希值的随机性,但冲突过多也是要控制的,后面会再详细介绍。
负载因子
负载因子(loadFactor)用于衡量一个哈希表冲突情况,公式为:
| |
例如,对于一个 bucket 数量为 4,包含 4 个键值对的哈希表来说,这个哈希表的负载因子为 1.
哈希表需要将负载因子控制在合适的大小,超过其阀值需要进行 rehash,也即键值对重新组织:
- 哈希因子过小,说明空间利用率低
- 哈希因子过大,说明冲突严重,存取效率低
每个哈希表的实现对负载因子容忍程度不同
- 比如 Redis 实现中负载因子大于 1 时就会触发 rehash,而 Go 则在在负载因子达到 6.5 时才会触发 rehash,
- 因为 Redis 的每个 bucket 只能存 1 个键值对,而 Go 的 bucket 可能存 8 个键值对,所以 Go 可以容忍更高的负载因子。
渐进式扩容
扩容的前提条件
为了保证访问效率,当新元素将要添加进 map 时,都会检查是否需要扩容,扩容实际上是以空间换时间的手段。 触发扩容的条件有二个:
- 负载因子 > 6.5 时,也即平均每个 bucket 存储的键值对达到 6.5 个。
- 使用增量扩容
- overflow 数量 > 2^15^ 时,也即 overflow 数量超过 32768 时。
- 使用等量扩容
增量扩容 / 翻倍扩容
当负载因子过大时,就新建 2n 个 bucket(n 为原来 buckets 的个数),然后旧 buckets 数据搬迁到新的 buckets。 考虑到如果 map 存储了数以亿计的 key-value,一次性搬迁将会造成比较大的延时,Go 采用逐步搬迁策略,即每次访问 map 时都会触发一次搬迁,每次搬迁 2 个键值对。
下图展示了包含一个 bucket 满载的 map (为了描述方便,图中 bucket 省略了 value 区域):

当前 map 存储了 7 个键值对,只有 1 个 bucket。此时负载因子为 7。再次插入数据时将会触发扩容操作,扩容之后再将新插入键写入新的 bucket。
当第 8 个键值对插入时,将会触发扩容,扩容后示意图如下:

hmap 数据结构中 oldbuckets 成员指身原 bucket,而 buckets 指向了新申请的 bucket。新的键值对被插入新的 bucket 中。 后续对 map 的访问操作会触发迁移,将 oldbuckets 中的键值对逐步的搬迁过来。当 oldbuckets 中的键值对全部搬迁完毕后,删除 oldbuckets。
搬迁完成后的示意图如下:

数据搬迁过程中原 bucket 中的键值对将存在于新 bucket 的前面,新插入的键值对将存在于新 bucket 的后面。 实际搬迁过程中比较复杂,将在后续源码分析中详细介绍。
等量扩容
所谓等量扩容,实际上并不是扩大容量;创建和旧桶数目一样多的新桶,然后把原来的键值对迁移到新桶中。把松散的键值对重新排列一次,以使 bucket 的使用率更高,进而保证更快的存取。
在极端场景下,比如不断的增删,而键值对正好集中在一小部分的 bucket,这样会造成 overflow 的 bucket 数量增多,但负载因子又不高,从而无法执行增量搬迁的情况,如下图所示:

上图可见,overflow 的 bucket 中大部分是空的,访问效率会很差。此时进行一次等量扩容,即 buckets 数量不变,经过重新组织后 overflow 的 bucket 数量会减少,即节省了空间又会提高访问效率。
查找过程
查找过程如下:
- 跟据 key 值算出哈希值
- 取哈希值低位与 hmpa.B 取模确定 bucket 位置
- 取哈希值高位在 tophash 数组中查询
- 如果 tophash[i] 中存储值与哈希值相等,则去找到该 bucket 中的 key 值进行比较
- 当前 bucket 没有找到,则继续从下个 overflow 的 bucket 中查找。
- 如果当前处于搬迁过程,则优先从 oldbuckets 查找
注:如果查找不到,也不会返回空值,而是返回相应类型的 0 值。
插入过程
新员素插入过程如下:
- 跟据 key 值算出哈希值
- 取哈希值低位与 hmap.B 取模确定 bucket 位置
- 查找该 key 是否已经存在,如果存在则直接更新值
- 如果没找到将 key,将 key 插入
struct
Go 的 struct 声明允许字段附带 Tag 来对字段做一些标记。
该 Tag 不仅仅是一个字符串那么简单,因为其主要用于反射场景,reflect 包中提供了操作 Tag 的方法,所以 Tag 写法也要遵循一定的规则。
常见的 tag 用法,主要是 JSON 数据解析、ORM 映射等。
Tag 的本质
Tag 规则
Tag 本身是一个字符串,但字符串中却是:以空格分隔的 key:value 对。
key:必须是非空字符串,字符串不能包含控制字符、空格、引号、冒号。value:以双引号标记的字符串- 注意:冒号前后不能有空格
如下代码所示,如此写没有实际意义,仅用于说明 Tag 规则
| |
上述代码 ServerName 字段的 Tag 包含两个 key-value 对。ServerIP 字段的 Tag 只包含一个 key-value 对。
Tag 是 Struct 的一部分
前面说过,Tag 只有在反射场景中才有用,而反射包中提供了操作 Tag 的方法。在说方法前,有必要先了解一下 Go 是如何管理 struct 字段的。
以下是 reflect 包中的类型声明,省略了部分与本文无关的字段。
| |
可见,描述一个结构体成员的结构中包含了 StructTag,而其本身是一个 string。也就是说 Tag 其实是结构体字段的一个组成部分。
获取 Tag
StructTag 提供了 Get(key string) string 方法来获取 Tag,示例如下:
| |
程序输出如下:
| |
Tag 存在的意义
本文示例中 tag 没有任何实际意义,这是为了阐述 tag 的定义与操作方法,也为了避免与你之前见过的诸如 json:xxx 混淆。
使用反射可以动态的给结构体成员赋值,正是因为有 tag,在赋值前可以使用 tag 来决定赋值的动作。 比如,官方的 encoding/json 包,可以将一个 JSON 数据 Unmarshal 进一个结构体,此过程中就使用了 Tag。该包定义一些规则,只要参考该规则设置 tag 就可以将不同的 JSON 数据转换成结构体。
总之:正是基于 struct 的 tag 特性,才有了诸如 json、orm 等等的应用。理解这个关系是至关重要的。或许,你可以定义另一种 tag 规则,来处理你特有的数据。
iota
我们知道 iota 常用于 const 表达式中,我们还知道其值是从零开始,const 声明块中每增加一行 iota 值自增 1。
使用 iota 可以简化常量定义,但其规则必须要牢牢掌握,否则在阅读别人源码时可能会造成误解或障碍。
规则
很多书上或博客描述的规则是这样的:
- iota 在 const 关键字出现时被重置为 0
- const 声明块中每新增一行 iota 值自增 1
其实规则只有一条:
- iota 代表了 const 声明块的行索引(下标从 0 开始)
下面再来根据这个规则看下这段代码:
| |
- 第 0 行的表达式展开即
bit0, mask0 = 1 << 0, 1<<0 - 1,所以 bit0 == 1,mask0 == 0; - 第 1 行没有指定表达式,则继承第一行,即
bit1, mask1 = 1 << 1, 1<<1 - 1,所以 bit1 == 2,mask1 == 1; - 第 2 行没有定义常量
- 第 3 行没有指定表达式,则继承第一行,即
bit3, mask3 = 1 << 3, 1<<3 - 1,所以 bit0 == 8,mask0 == 7;
编译原理
const 块中每一行在 GO 中使用 spec 数据结构描述,spec 声明如下:
| |
这里我们只关注 ValueSpec.Names, 这个切片中保存了一行中定义的常量,如果一行定义 N 个常量,那么ValueSpec.Names 切片长度即为 N。
const 块实际上是 spec 类型的切片,用于表示 const 中的多行。
所以编译期间构造常量时的伪算法如下:
| |
从上面可以更清晰的看出 iota 实际上是遍历 const 块的索引,每行中即便多次使用 iota,其值也不会递增。
string
string 标准概念
Go 标准库 builtin 给出了所有内置类型的定义。 源代码位于 src/builtin/builtin.go,其中关于 string 的描述如下:
| |
所以 string 是 8 比特字节的集合,通常但并不一定是 UTF-8 编码的文本。
另外,还提到了两点,非常重要:
- string 可以为空(长度为 0),但不会是 nil;
- string 对象不可以修改。
string 数据结构
源码包 src/runtime/string.go:stringStruct 定义了 string 的数据结构:
| |
其数据结构很简单:
stringStruct.str:字符串的首地址;stringStruct.len:字符串的长度;
string 数据结构跟切片有些类似,只不过切片还有一个表示容量的成员,事实上 string 和切片,准确的说是 byte 切片经常发生转换。
string 操作
声明
如下代码所示,可以声明一个 string 变量变赋予初值:
| |
字符串构建过程是先跟据字符串构建 stringStruct,再转换成 string。转换的源码如下:
| |
string 在 runtime 包中就是 stringStruct,对外呈现叫做 string。
[]byte 转 string
byte 切片可以很方便的转换成 string,如下所示:
| |
需要注意的是这种转换需要一次内存拷贝。
转换过程如下:
- 跟据切片的长度申请内存空间,假设内存地址为 p,切片长度为 len(b);
- 构建 string(
string.str = p;string.len = len;) - 拷贝数据 (切片中数据拷贝到新申请的内存空间)
转换示意图:

string 转 []byte
string 也可以方便的转成 byte 切片,如下所示:
| |
string 转换成 byte 切片,也需要一次内存拷贝,其过程如下:
- 申请切片内存空间
- 将 string 拷贝到切片
转换示意图:

字符串拼接
字符串可以很方便的拼接,像下面这样:
| |
即便有非常多的字符串需要拼接,性能上也有比较好的保证,因为新字符串的内存空间是一次分配完成的,所以性能消耗主要在拷贝数据上。
一个拼接语句的字符串编译时都会被存放到一个切片中,拼接过程需要遍历两次切片:
- 第一次遍历获取总的字符串长度,据此申请内存
- 第二次遍历会把字符串逐个拷贝过去。
字符串拼接伪代码如下:
| |
因为 string 是无法直接修改的,所以这里使用 rawstring() 方法初始化一个指定大小的 string,同时返回一个切片,二者共享同一块内存空间,后面向切片中拷贝数据,也就间接修改了 string。
rawstring() 源代码如下:
| |
思考
为什么字符串不允许修改?
像 C++ 语言中的 string,其本身拥有内存空间,修改 string 是支持的。但 Go 的实现中,string 不包含内存空间,只有一个内存的指针,这样做的好处是 string 变得非常轻量,可以很方便的进行传递而不用担心内存拷贝。
因为 string 通常指向字符串字面量,而字符串字面量存储位置是只读段,而不是堆或栈上,所以才有了 string 不可修改的约定。
⭐ []byte 转换成 string 一定会拷贝内存吗?
byte 切片转换成 string 的场景很多,为了性能上的考虑,有时候只是临时需要字符串的场景下,byte 切片转换成 string 时并不会拷贝内存,而是直接返回一个 string,这个 string 的指针 (string.str) 指向切片的内存。
比如,编译器会识别如下临时场景:
- 使用
m[string(b)]来查找 map(map 是 string 为 key,临时把切片 b 转成 string); - 字符串拼接,如
"<" + "string(b)" + ">"; - 字符串比较:
string(b) == "foo"
因为是临时把 byte 切片转换成 string,也就避免了因 byte 切片扩容改成而导致 string 引用失败的情况,所以此时可以不必拷贝内存新建一个 string。
string 和 []byte 如何取舍
string 和 []byte 都可以表示字符串,但因数据结构不同,其衍生出来的方法也不同,要跟据实际应用场景来选择。
string 擅长的场景:
- 需要字符串比较的场景;
- 不需要 nil 字符串的场景;
[]byte 擅长的场景:
- 修改字符串的场景,尤其是修改粒度为 1 个字节;
- 函数返回值,需要用 nil 表示含义的场景;
- 需要切片操作的场景;
虽然看起来 string 适用的场景不如 []byte 多,但因为 string 直观,在实际应用中还是大量存在,在偏底层的实现中 []byte 使用更多。
常用控制结构实现原理
本章主要介绍常见的控制结构,比如 defer、select、range 等,通过对其底层实现原理的分析,来加深认识,以此避免一些使用过程中的误区。
defer
defer 语句用于延迟函数的调用,每次 defer 都会把一个函数压入栈中,函数返回前再把延迟的函数取出并执行。
为了方便描述,我们把创建 defer 的函数称为主函数,defer 语句后面的函数称为延迟函数。
延迟函数可能有输入参数,这些参数可能来源于定义 defer 的函数,延迟函数也可能引用主函数用于返回的变量,也就是说延迟函数可能会影响主函数的一些行为,这些场景下,如果不了解 defer 的规则很容易出错。
其实官方说明的 defer 的三个原则很清楚,本节试图汇总 defer 的使用场景并做简单说明。
例子
例一
下面函数输出结果是什么?
| |
输出 1。
延迟函数
fmt.Println(aInt)的参数在 defer 语句出现时就已经确定了,所以无论后面如何修改 aInt 变量都不会影响延迟函数。
例二
| |
输出 10、2、3 三个值。
延迟函数
printArray()的参数在 defer 语句出现时就已经确定了,即数组的地址,由于延迟函数执行时机是在 return 语句之前,所以对数组的最终修改值会被打印出来。
例三
下面函数输出什么?
| |
输出 2。
函数的 return 语句并不是原子的,实际执行分为
- 设置返回值
- ret
⭐ defer 语句实际执行在返回前,即拥有 defer 的函数返回过程是:
设置返回值
执行 defer
ret
所以 return 语句先把 result 设置为 i 的值,即 1,defer 语句中又把 result 递增 1,所以最终返回 2。
defer 规则
Golang 官方博客里总结了 defer 的行为规则,只有三条,我们围绕这三条进行说明。
规则一
延迟函数的参数在 defer 语句出现时就已经确定下来了
官方给出一个例子,如下所示:
| |
defer 语句中的 fmt.Println() 参数 i 值在 defer 出现时就已经确定下来,实际上是拷贝了一份。后面对变量 i 的修改不会影响 fmt.Println() 函数的执行,仍然打印 “0”。
注意:对于指针类型参数,规则仍然适用,只不过延迟函数的参数是一个地址值,这种情况下,defer 后面的语句对变量的修改可能会影响延迟函数。
规则二
延迟函数执行按后进先出顺序执行,即先出现的 defer 最后执行
这个规则很好理解,定义 defer 类似于入栈操作,执行 defer 类似于出栈操作。
设计 defer 的初衷是简化函数返回时资源清理的动作,资源往往有依赖顺序,比如先申请 A 资源,再跟据 A 资源申请 B 资源,跟据 B 资源申请 C 资源,即申请顺序是:A–>B–>C,释放时往往又要反向进行。
每申请到一个用完需要释放的资源时,立即定义一个 defer 来释放资源是个很好的习惯。
规则三
延迟函数可能操作主函数的具名返回值
定义 defer 的函数,即主函数可能有返回值,返回值有没有名字没有关系,defer 所作用的函数,即延迟函数可能会影响到返回值。
若要理解延迟函数是如何影响主函数返回值的,只要明白函数是如何返回的就足够了。
函数返回过程
有一个事实必须要了解,关键字 return 不是一个原子操作,实际上 return 只代理汇编指令 ret,即将跳转程序执行。
比如语句 return i,实际上分两步进行,即
- 将 i 值存入栈中作为返回值
- 执行跳转
而 defer 的执行时机正是跳转前,所以说 defer 执行时还是有机会操作返回值的。
举个实际的例子进行说明这个过程:
| |
该函数的 return 语句可以拆分成下面两行:
| |
而延迟函数的执行正是在 return 之前,即加入 defer 后的执行过程如下:
| |
所以上面函数实际返回 i++ 值。
关于主函数有不同的返回方式,但返回机制就如上机介绍所说,只要把 return 语句拆开都可以很好的理解,下面分别举例说明
主函数拥有匿名返回值,返回字面值
不影响
一个主函数拥有一个匿名的返回值,返回时使用字面值,比如返回 “1”、“2”、“Hello” 这样的值,这种情况下 defer 语句是无法操作返回值的。
一个返回字面值的函数,如下所示:
| |
上面的 return 语句,直接把 1 写入栈中作为返回值,延迟函数无法操作该返回值,所以就无法影响返回值。
主函数拥有匿名返回值,返回变量
不影响
一个主函数拥有一个匿名的返回值,返回使用本地或全局变量,这种情况下 defer 语句可以引用到返回值,但不会改变返回值。
一个返回本地变量的函数,如下所示:
| |
上面的函数,返回一个局部变量,同时 defer 函数也会操作这个局部变量。
对于匿名返回值来说,可以假定仍然有一个变量存储返回值,假定返回值变量为 “anony”,上面的返回语句可以拆分成以下过程:
| |
由于 i 是整型,会将值拷贝给 anony,所以 defer 语句中修改 i 值,对函数返回值不造成影响。
主函数拥有具名返回值
影响
主函声明语句中带名字的返回值,会被初始化成一个局部变量,函数内部可以像使用局部变量一样使用该返回值。如果 defer 语句操作该返回值,可能会改变返回结果。
一个影响函返回值的例子:
| |
上面的函数拆解出来,如下所示:
| |
函数真正返回前,在 defer 中对返回值做了 +1 操作,所以函数最终返回 1
defer 实现原理
本节我们尝试了解一些 defer 的实现机制。
defer 数据结构
源码包 src/src/runtime/runtime2.go:_defer 定义了 defer 的数据结构:
| |
我们知道 defer 后面一定要接一个函数的,所以 defer 的数据结构跟一般函数类似,也有栈地址、程序计数器、函数地址等等。
与函数不同的一点是它含有一个指针,可用于指向另一个 defer
每个 goroutine 数据结构中实际上也有一个 defer 指针,该指针指向一个 defer 的单链表
- 每次声明一个 defer 时就将 defer 插入到单链表表头
- 每次执行 defer 时就从单链表表头取出一个 defer 执行。
函数返回前执行 defer 则是从链表首部依次取出执行,不再赘述。
一个 goroutine 可能连续调用多个函数,defer 添加过程跟上述流程一致,进入函数时添加 defer,离开函数时取出 defer,所以即便调用多个函数,也总是能保证 defh 后进先出方式执行的。
defer 的创建和执行
源码包 src/runtime/panic.go 定义了两个方法分别用于创建 defer 和执行 defer。
deferproc(): 在声明 defer 处调用,其将 defer 函数存入 goroutine 的链表中;deferreturn():在 return 指令,准确的讲是在 ret 指令前调用,其将 defer 从 goroutine 链表中取出并执行。
可以简单这么理解:在编译阶段,声明 defer 处插入了函数 deferproc();在函数 return 前插入了函数 deferreturn()
总结
- defer 定义的延迟函数参数在 defer 语句出时就已经确定下来了
- defer 定义顺序与实际执行顺序相反
- return 不是原子操作,执行过程是:保存返回值(若有) –> 执行 defer(若有)–> 执行 ret 跳转
- 申请资源后立即使用 defer 关闭资源是好习惯
recover
项目中,有时为了让程序更健壮,也即不 panic,我们或许会使用 recover() 来接收异常并处理。
比如以下代码:
| |
func NoPanic() 会自动接收异常,并打印相关日志,算是一个通用的异常处理函数。
业务处理函数中只要使用了 defer NoPanic(),那么就不会再有 panic 发生。
关于是否应该使用 recover 接收异常,以及什么场景下使用等问题不在本节讨论范围内。 本节关注的是这种用法的一个变体,在该变体下,recover 再也无法接收异常。
recover 使用误区
在项目中,有众多的数据库更新操作,正常的更新操作需要提交,而失败的就需要回滚,如果异常分支比较多, 就会有很多重复的回滚代码,所以有人尝试了一个做法:即在 defer 中判断是否出现异常,有异常则回滚,否则提交。
简化代码如下所示:
| |
func IsPanic() bool 用来接收异常,返回值用来说明是否发生了异常。func UpdateTable() 函数中,使用 defer 来判断最终应该提交还是回滚。
上面代码初步看起来还算合理,但是此处的 IsPanic() 再也不会返回 true,不是 IsPanic() 函数的问题,而是其调用的位置不对。
recover 失效的条件
上面代码 IsPanic() 失效了,其原因是违反了 recover 的一个限制,导致 recover() 失效(永远返回 nil)。
以下三个条件会让 recover() 返回 nil:
- panic 时指定的参数为
nil;(一般 panic 语句如panic("xxx failed...")) - 当前协程没有发生 panic;
- recover 没有被 defer 方法直接调用;
前两条都比较容易理解,上述例子正是匹配第 3 个条件。
本例中,recover() 调用栈为 “defer (匿名)函数” --> IsPanic() --> recover()。也就是说,recover 并没有被 defer 方法直接调用。符合第 3 个条件,所以 recover() 永远返回 nil
select
select 是 Golang 在语言层面提供的多路 IO 复用的机制,其可以检测多个 channel 是否 ready (即是否可读或可写),使用起来非常方便。
实现原理
Golang 实现 select 时,定义了一个数据结构表示每个 case 语句 (含 defaut,default 实际上是一种特殊的 case),select 执行过程可以类比成一个函数,函数输入 case 数组,输出选中的 case,然后程序流程转到选中的 case 块。
case 数据结构
源码包 src/runtime/select.go:scase 定义了表示 case 语句的数据结构:
| |
scase.c 为当前 case 语句所操作的 channel 指针,这也说明了一个 case 语句只能操作一个 channel。
scase.kind 表示该 case 的类型,分为读 channel、写 channel 和 default,三种类型分别由常量定义:
caseRecv:case 语句中尝试读取scase.c中的数据;caseSend:case 语句中尝试向scase.c中写入数据;caseDefault: default 语句
scase.elem 表示缓冲区地址,跟据 scase.kind 不同,有不同的用途:
scase.kind == caseRecv:scase.elem表示读出 channel 的数据存放地址;scase.kind == caseSend:scase.elem表示将要写入 channel 的数据存放地址;
select 实现逻辑
源码包 src/runtime/select.go:selectgo() 定义了 select 选择 case 的函数:
| |
函数参数:
cas0为 scase 数组的首地址,selectgo()就是从这些 scase 中找出一个返回。order0为一个两倍cas0数组长度的 buffer,保存 scase 随机序列pollorder和 scase 中 channel 地址序列lockorderpollorder:每次 selectgo 执行都会把 scase 序列打乱,以达到随机检测 case 的目的。lockorder:所有 case 语句中 channel 序列,以达到去重防止对 channel 加锁时重复加锁的目的。
ncases表示 scase 数组的长度
函数返回值:
int: 选中 case 的编号,这个 case 编号跟代码一致bool: 是否成功从 channle 中读取了数据,如果选中的 case 是从 channel 中读数据,则该返回值表示是否读取成功。
selectgo() 实现伪代码如下:
| |
特别说明:对于读 channel 的 case 来说,如 case elem, ok := <-chan1:,如果 channel 有可能被其他协程关闭的情况下,一定要检测读取是否成功,因为 close 的 channel 也有可能返回,此时 ok == false。
总结
- select 语句中除 default 外,每个 case 操作一个 channel,要么读要么写
- select 语句中除 default 外,各 case 执行顺序是随机的
- select 语句中如果没有 default 语句,则会阻塞等待任一 case
- select 语句中读操作要判断是否成功读取,关闭的 channel 也可以读取
range
range 是 Golang 提供的一种迭代遍历手段,可操作的类型有数组、切片、Map、channel 等,实际使用频率非常高。
探索 range 的实现机制是很有意思的事情,这可能会改变你使用 range 的习惯。
例子
切片遍历
下面函数通过遍历切片,打印切片的下标和元素值,请问性能上有没有可优化的空间?
| |
遍历过程中每次迭代会对 index 和 value 进行赋值
如果数据量大或者 value 类型为 string 时,对 value 的赋值操作可能是多余的
可以在 for-range 中忽略 value 值,使用 slice[index] 引用 value 值。
Map 遍历
下面函数通过遍历 Map,打印 Map 的 key 和 value,请问性能上有没有可优化的空间?
| |
函数中 for-range 语句中只获取 key 值,然后跟据 key 值获取 value 值
虽然看似减少了一次赋值,但通过 key 值查找 value 值的性能消耗可能高于赋值消耗。能否优化取决于 map 所存储数据结构特征、结合实际情况进行。
动态遍历
请问如下程序是否能正常结束?
| |
能够正常结束。循环内改变切片的长度,不影响循环次数,⭐ 循环次数在循环开始前就已经确定了。
实现原理
对于 for-range 语句的实现,可以从编译器源码中找到答案。
编译器源码 gofrontend/go/statements.cc/For_range_statement::do_lower() 方法中有如下注释。
| |
可见 range 实际上是一个 C 风格的循环结构。range 支持数组、数组指针、切片、map 和 channel 类型,对于不同类型有些细节上的差异。
range for slice
下面的注释解释了遍历 slice 的过程:
| |
遍历 slice 前会先获取以 slice 的长度 len_temp 作为循环次数,循环体中,每次循环会先获取元素值,如果 for-range 中接收 index 和 value 的话,则会对 index 和 value 进行一次赋值。
由于循环开始前循环次数就已经确定了,所以循环过程中新添加的元素是没办法遍历到的。
另外,数组与数组指针的遍历过程与 slice 基本一致,不再赘述。
range for map
下面的注释解释了遍历 map 的过程:
| |
遍历 map 时没有指定循环次数,循环体与遍历 slice 类似。由于 map 底层实现与 slice 不同,map 底层使用 hash 表实现,插入数据位置是随机的,所以遍历过程中新插入的数据不能保证遍历到。
range for channel
遍历 channel 是最特殊的,这是由 channel 的实现机制决定的:
| |
channel 遍历是依次从 channel 中读取数据;读取前是不知道里面有多少个元素的。如果 channel 中没有元素,则会阻塞等待,如果 channel 已被关闭,则会解除阻塞并退出循环。
注:
- 上述注释中 index_temp 实际上描述是有误的,应该为 value_temp,因为 index 对于 channel 是没有意义的。
- 使用 for-range 遍历 channel 时只能获取一个返回值。
编程 Tips
- 遍历过程中可以适情况放弃接收 index 或 value,可以一定程度上提升性能
- 遍历 channel 时,如果 channel 中没有数据,可能会阻塞
- 尽量避免遍历过程中修改原数据
总结
- for-range 的实现实际上是 C 风格的 for 循环
- 使用 index, value 接收 range 返回值会发生一次数据拷贝
mutex
互斥锁是并发程序中对共享资源进行访问控制的主要手段,对此 Go 语言提供了非常简单易用的 Mutex,Mutex 为一结构体类型,对外暴露两个方法 Lock() 和 Unlock() 分别用于加锁和解锁。
Mutex 使用起来非常方便,但其内部实现却复杂得多,这包括 Mutex 的几种状态。另外,我们也想探究一下 Mutex 重复解锁引起 panic 的原因。
按照惯例,本节内容从源码入手,提取出实现原理,又不会过分纠结于实现细节。
Mutex 数据结构
Mutex 结构体
源码包 src/sync/mutex.go:Mutex 定义了互斥锁的数据结构:
| |
Mutex.state表示互斥锁的状态,比如是否被锁定等。Mutex.sema表示信号量,协程阻塞等待该信号量,解锁的协程释放信号量从而唤醒等待信号量的协程。
我们看到 Mutex.state 是 32 位的整型变量,内部实现时把该变量分成四份,用于记录 Mutex 的四种状态。
下图展示 Mutex 的内存布局:

- Locked: 表示该 Mutex 是否已被锁定
- 0:没有锁定
- 1:已被锁定。
- Woken: 表示是否有协程已被唤醒
- 0:没有协程唤醒
- 1:已有协程唤醒,正在加锁过程中。
- Starving:表示该 Mutex 是否处理饥饿状态
- 0:没有饥饿
- 1:饥饿状态,说明有协程阻塞了超过 1ms。
- Waiter: 表示阻塞等待锁的协程个数,协程解锁时根据此值来判断是否需要释放信号量。
协程之间抢锁实际上是抢给 Locked 赋值的权利
- 能给 Locked 域置 1,就说明抢锁成功。
- 抢不到的话就阻塞等待 Mutex.sema 信号量
- 一旦持有锁的协程解锁,等待的协程会依次被唤醒。
Woken 和 Starving 主要用于控制协程间的抢锁过程,后面再进行了解。
Mutex 方法
Mutext 对外提供两个方法,实际上也只有这两个方法:
Lock():加锁方法Unlock():解锁方法
下面我们分析一下加锁和解锁的过程,加锁分成功和失败两种情况,成功的话直接获取锁,失败后当前协程被阻塞,同样,解锁时跟据是否有阻塞协程也有两种处理。
加解锁过程
简单加锁
假定当前只有一个协程在加锁,没有其他协程干扰,那么过程如下图所示:

加锁过程会去判断 Locked 标志位是否为 0,如果是 0 则把 Locked 位置 1,代表加锁成功。
从上图可见,加锁成功后,只是 Locked 位置 1,其他状态位没发生变化。
加锁被阻塞
假定加锁时,锁已被其他协程占用了,此时加锁过程如下图所示:

从上图可看到,当协程 B 对一个已被占用的锁再次加锁时,Waiter 计数器增加了 1,此时协程 B 将被阻塞,直到 Locked 值变为 0 后才会被唤醒。
简单解锁
假定解锁时,没有其他协程阻塞,此时解锁过程如下图所示:

由于没有其他协程阻塞等待加锁,所以此时解锁时只需要把 Locked 位置为 0 即可,不需要释放信号量。
解锁并唤醒协程
假定解锁时,有 1 个或多个协程阻塞,此时解锁过程如下图所示:

协程 A 解锁过程分为两个步骤
- Locked 位置 0
- 查看到 Waiter > 0,所以释放一个信号量,唤醒一个阻塞的协程,被唤醒的协程 B 把 Locked 位置 1,于是协程 B 获得锁。
自旋过程
加锁时,如果当前 Locked 位为 1,说明该锁当前由其他协程持有,尝试加锁的协程并不是马上转入阻塞,而是会持续地探测 Locked 位是否变为 0,这个过程即为自旋过程。
自旋时间很短,但如果在自旋过程中发现锁已被释放,那么协程可以立即获取锁。此时即便有协程被唤醒也无法获取锁,只能再次阻塞。
自旋的好处是,当加锁失败时不必立即转入阻塞,有一定机会获取到锁,这样可以避免协程的切换。
什么是自旋
自旋对应于 CPU 的 “PAUSE” 指令,CPU 对该指令什么都不做,相当于 CPU 空转,对程序而言相当于 sleep 了一小段时间,时间非常短,当前实现是 30 个时钟周期。
自旋过程中会持续探测 Locked 是否变为 0,连续两次探测间隔就是执行这些 PAUSE 指令,它不同于 sleep,不需要将协程转为睡眠状态。
自旋条件
加锁时程序会自动判断是否可以自旋,无限制的自旋将会给 CPU 带来巨大压力,所以判断是否可以自旋就很重要了。
自旋必须满足以下所有条件:
- 自旋次数要足够小,通常为 4,即自旋最多 4 次
- CPU 核数要大于 1,否则自旋没有意义,因为此时不可能有其他协程释放锁
- 协程调度机制中的 Process 数量要大于 1,比如使用
GOMAXPROCS()将处理器设置为 1 就不能启用自旋 - 协程调度机制中的可运行队列必须为空,否则会延迟协程调度
可见,自旋的条件是很苛刻的,总而言之就是不忙的时候才会启用自旋。
自旋的优势
自旋的优势是更充分地利用 CPU,尽量避免协程切换。
因为当前申请加锁的协程拥有 CPU,如果经过短时间的自旋可以获得锁,当前协程可以继续运行,不必进入阻塞状态。
自旋的问题
如果自旋过程中获得锁,那么之前被阻塞的协程将无法获得锁,如果加锁的协程特别多,每次都通过自旋获得锁,那么之前被阻塞的进程将很难获得锁,从而进入饥饿状态。
为了避免协程长时间无法获取锁,自 1.8 版本以来增加了一个状态,即 Mutex 的 Starving 状态。这个状态下不会自旋,一旦有协程释放锁,那么一定会唤醒一个协程并成功加锁。
Mutex 模式
前面分析加锁和解锁过程中只关注了 Waiter 和 Locked 位的变化,现在我们看一下 Starving 位的作用。
每个 Mutex 都有两个模式,称为 Normal 和 Starving。下面分别说明这两个模式。
normal 模式
默认情况下,Mutex 的模式为 normal。
该模式下,协程如果加锁不成功不会立即转入阻塞排队,而是判断是否满足自旋的条件,如果满足则会启动自旋过程,尝试抢锁。
starvation 模式
自旋过程中能抢到锁,一定意味着同一时刻有协程释放了锁,我们知道释放锁时如果发现有阻塞等待的协程,还会释放一个信号量来唤醒一个等待协程,被唤醒的协程得到 CPU 后开始运行,此时发现锁已被抢占了,自己只好再次阻塞,不过阻塞前会判断自上次阻塞到本次阻塞经过了多长时间,如果超过 1ms 的话,会将 Mutex 标记为"饥饿"模式,然后再阻塞。
处于饥饿模式下,不会启动自旋过程,也即一旦有协程释放了锁,那么一定会唤醒协程,被唤醒的协程将会成功获取锁,同时也会把等待计数减 1。
Woken 状态
Woken 状态用于加锁和解锁过程的通信,举个例子,同一时刻,两个协程一个在加锁,一个在解锁,在加锁的协程可能在自旋过程中,此时把 Woken 标记为 1,用于通知解锁协程不必释放信号量了,好比在说:你只管解锁好了,不必释放信号量,我马上就拿到锁了。
为什么重复解锁要 panic
可能你会想,为什么 Go 不能实现得更健壮些,多次执行 Unlock() 也不要 panic?
仔细想想 Unlock 的逻辑就可以理解,这实际上很难做到。Unlock 过程分为将 Locked 置为 0,然后判断 Waiter 值,如果值 >0,则释放信号量。
如果多次 Unlock(),那么可能每次都释放一个信号量,这样会唤醒多个协程,多个协程唤醒后会继续在 Lock() 的逻辑里抢锁,势必会增加 Lock() 实现的复杂度,也会引起不必要的协程切换。
编程 Tips
使用 defer 避免死锁
加锁后立即使用 defer 对其解锁,可以有效的避免死锁。
加锁和解锁应该成对出现
加锁和解锁最好出现在同一个层次的代码块中,比如同一个函数。
重复解锁会引起 panic,应避免这种操作的可能性。
rwmutex
所谓读写锁 RWMutex,完整的表述应该是读写互斥锁,可以说是 Mutex 的一个改进版,在某些场景下可以发挥更加灵活的控制能力,比如:读取数据频率远远大于写数据频率的场景。
例如,程序中写操作少而读操作多,简单的说,如果执行过程是 1 次写然后 N 次读的话,使用 Mutex,这个过程将是串行的,因为即便 N 次读操作互相之间并不影响,但也都需要持有 Mutex 后才可以操作。如果使用读写锁,多个读操作可以同时持有锁,并发能力将大大提升。
实现读写锁需要解决如下几个问题:
- 写锁需要阻塞写锁:一个协程拥有写锁时,其他协程写锁定需要阻塞
- 写锁需要阻塞读锁:一个协程拥有写锁时,其他协程读锁定需要阻塞
- 读锁需要阻塞写锁:一个协程拥有读锁时,其他协程写锁定需要阻塞
- 读锁不能阻塞读锁:一个协程拥有读锁时,其他协程也可以拥有读锁
下面我们将按照这个思路,即读写锁如何解决这些问题的,来分析读写锁的实现。
读写锁基于 Mutex 实现,实现源码非常简单和简洁,又有一定的技巧在里面。
读写锁数据结构
类型定义
源码包 src/sync/rwmutex.go:RWMutex 定义了读写锁数据结构:
| |
由以上数据结构可见,读写锁内部仍有一个互斥锁,用于将两个写操作隔离开来,其他的几个都用于隔离读操作和写操作。
下面我们简单看下 RWMutex 提供的 4 个接口,后面再跟据使用场景具体分析这几个成员是如何配合工作的。
接口定义
RWMutex 提供 4 个简单的接口来提供服务:
RLock():读锁定RUnlock():解除读锁定Lock():写锁定,与 Mutex 完全一致Unlock():解除写锁定,与 Mutex 完全一致
Lock() 实现逻辑
写锁定操作需要做两件事:
- 获取互斥锁
- 阻塞等待所有读操作结束(如果有的话)
所以 func (rw *RWMutex) Lock() 接口实现流程如下图所示:

Unlock() 实现逻辑
解除写锁定要做两件事:
- 唤醒因读锁定而被阻塞的协程(如果有的话)
- 解除互斥锁
所以 func (rw *RWMutex) Unlock() 接口实现流程如下图所示:

RLock() 实现逻辑
读锁定需要做两件事:
- 增加读操作计数,即
readerCount++ - 阻塞等待写操作结束(如果有的话)
所以 func (rw *RWMutex) RLock() 接口实现流程如下图所示:

RUnlock() 实现逻辑
解除读锁定需要做两件事:
- 减少读操作计数,即
readerCount-- - 唤醒等待写操作的协程(如果有的话)
所以func (rw *RWMutex) RUnlock()接口实现流程如下图所示:

注意:即便有协程阻塞等待写操作,并不是所有的解除读锁定操作都会唤醒该协程,而是最后一个解除读锁定的协程才会释放信号量将该协程唤醒,因为只有当所有读操作的协程释放锁后才可以唤醒协程。
场景分析
上面我们简单看了下 4 个接口实现原理,接下来我们看一下是如何解决前面提到的几个问题的。
写操作是如何阻止写操作的
读写锁包含一个互斥锁 (Mutex),写锁定必须要先获取该互斥锁,如果互斥锁已被协程 A 获取(或者协程 A 在阻塞等待读结束),意味着协程 A 获取了互斥锁,那么协程 B 只能阻塞等待该互斥锁。
所以,写操作依赖互斥锁阻止其他的写操作。
写操作是如何阻止读操作的
这个是读写锁实现中最精华的技巧。
我们知道 RWMutex.readerCount 是个整型值,用于表示读者数量,不考虑写操作的情况下,每次读锁定将该值 +1,每次解除读锁定将该值 -1,所以 readerCount 取值为 [0, N],N 为读者个数,实际上最大可支持 2^30^ 个并发读者。
当写锁定进行时,会先将 readerCount 减去 2^30^,从而 readerCount 变成了负值,此时再有读锁定到来时检测到readerCount 为负值,便知道有写操作在进行,只好阻塞等待。而真实的读操作个数并不会丢失,只需要将readerCount 加上 2^30^ 即可获得。
所以,写操作将 readerCount 变成负值来阻止读操作的。
读操作是如何阻止写操作的
读锁定会先将 RWMutext.readerCount 加 1,此时写操作到来时发现读者数量不为 0,会阻塞等待所有读操作结束。
所以,读操作通过 readerCount 来将来阻止写操作的。
为什么写锁定不会被饿死
我们知道,写操作要等待读操作结束后才可以获得锁,写操作等待期间可能还有新的读操作持续到来,如果写操作等待所有读操作结束,很可能被饿死。然而,通过 RWMutex.readerWait 可完美解决这个问题。
写操作到来时,会把 RWMutex.readerCount 值拷贝到 RWMutex.readerWait 中,用于标记排在写操作前面的读者个数。
前面的读操作结束后,除了会递减 RWMutex.readerCount,还会递减 RWMutex.readerWait 值,当 RWMutex.readerWait 值变为 0 时唤醒写操作。
所以以,写操作就相当于把一段连续的读操作划分成两部分,前面的读操作结束后唤醒写操作,写操作结束后唤醒后面的读操作。如下图所示:

关于源码
源码地址注解:https://github.com/RainbowMango/GoComments
Goroutine
本章主要介绍协程及其调度机制。
协程是 GO 语言最大的特色之一,本章我们从协程的概念、GO 协程的实现、GO 协程调度机制等角度来分析。
Goroutine 调度是一个很复杂的机制,尽管 Go 源码中提供了大量的注释,但对其原理没有一个好的理解的情况下去读源码收获不会很大。下面尝试用简单的语言描述一下 Goroutine 调度机制,在此基础上再去研读源码效果可能更好一些。
线程池的缺陷
我们知道,在高并发应用中频繁创建线程会造成不必要的开销,所以有了线程池。线程池中预先保存一定数量的线程,而新任务将不再以创建线程的方式去执行,而是将任务发布到任务队列,线程池中的线程不断的从任务队列中取出任务并执行,可以有效的减少线程创建和销毁所带来的开销。
下图展示一个典型的线程池:

为了方便下面的叙述,我们把任务队列中的每一个任务称作 G,而 G 往往代表一个函数。 线程池中的 worker 线程不断的从任务队列中取出任务并执行。而 worker 线程的调度则交给操作系统进行调度。
如果 worker 线程执行的 G 任务中发生系统调用,则操作系统会将该线程置为阻塞状态,也意味着该线程在怠工,也意味着消费任务队列的 worker 线程变少了,也就是说线程池消费任务队列的能力变弱了。
如果任务队列中的大部分任务都会进行系统调用,则会让这种状态恶化,大部分 worker 线程进入阻塞状态,从而任务队列中的任务产生堆积。
解决这个问题的一个思路就是重新审视线程池中线程的数量,增加线程池中线程数量可以一定程度上提高消费能力,但随着线程数量增多,由于过多线程争抢 CPU,消费能力会有上限,甚至出现消费能力下降。 如下图所示:

Goroutine 调度器
线程数过多,意味着操作系统会不断的切换线程,频繁的上下文切换就成了性能瓶颈。
Go 提供一种机制,可以在线程中自己实现调度,上下文切换更轻量,从而达到了线程数少,而并发数并不少的效果。而线程中调度的就是 Goroutine.
早期 Go 版本,比如 1.9.2 版本的源码注释中有关于调度器的解释。 Goroutine 调度器的工作就是把 “ready-to-run” 的 goroutine 分发到线程中。
常见的线程模型
目前有三个常见的线程模型。
- 一个是 N:1 的,即多个用户空间线程运行在一个 OS 线程上。这个模型可以很快的进行上下文切换,但是不能利用多核系统(multi-core systems)的优势。
- 另一个模型是 1:1 的,即可执行程序的一个线程匹配一个 OS 线程。这个模型能够利用机器上的所有核心的优势,但是上下文切换非常慢,因为它不得不陷入 OS(trap through the OS)。
Go 试图通过 M:N 的调度器去获取这两个世界的全部优势。它在任意数目的 OS 线程上调用任意数目的 goroutines。你可以快速进行上下文切换,并且还能利用你系统上所有的核心的优势。这个模型主要的缺点是它增加了调度器的复杂性。
GMP 模型
Goroutine 主要概念如下:

M (Machine):
- 工作线程,在 Go 中称为 Machine。
- 一个
M直接关联了一个内核线程
G (Goroutine):
- 即 Go 协程,每个 go 关键字都会创建一个协程。
- 本质上也是一种轻量级的线程。
P (Processor)
- 代表了
M所需的上下文环境,也是处理用户级代码逻辑的处理器 - 它包含运行 Go 代码的必要资源,也有调度 goroutine 的能力。
- 它是让我们从 N:1 调度器转到 M:N 调度器的重要部分
- 代表了
M 必须拥有 P 才可以执行 G 中的代码,P 含有一个包含多个 G 的队列(runqueue),P 可以调度 G 交由 M 执行。
换句话来说:一个 M 会对应一个内核线程,一个 M 也会连接一个上下文 P,一个上下文 P 相当于一个“处理器”,一个上下文连接一个或者多个 Goroutine。
其关系如下图所示:

称为 MPG 模型
图中 M 是交给操作系统调度的线程,M 持有一个 P,P 将 G 调度进 M 中执行。P 同时还维护着一个包含 G 的队列(图中灰色部分,runqueue),可以按照一定的策略将 G 调度到 M 中执行。
为了降低 mutex 竞争,每一个上下文都有它自己的 runqueue。Go 调度器曾经的一个版本只有一个通过 mutex 来保护的全局 runqueue,线程们经常被阻塞来等待 mutex 被解除阻塞。当你有许多 32 核的机器而且想尽可能地压榨它们的性能时,情况就会变得相当坏。
P 的个数在程序启动时决定,默认情况下等同于 CPU 的核数,由于 M 必须持有一个 P 才可以运行 Go 代码,所以同时运行的 M 个数,也即线程数一般等同于 CPU 的个数,以达到尽可能的使用 CPU 而又不至于产生过多的线程切换开销。
程序中可以使用 runtime.GOMAXPROCS() 设置 P 的个数,在某些 IO 密集型的场景下可以在一定程度上提高性能。这个后面再详细介绍。
Goroutine 调度策略
队列轮转、系统调用、工作量窃取
队列轮转
上图中可见每个 P 维护着一个包含 G 的队列,不考虑 G 进入系统调用或 IO 操作的情况下,P 周期性的将 G 调度到 M 中执行,执行一小段时间,将上下文保存下来,然后将 G 放到队列尾部,然后从队列中重新取出一个 G 进行调度。
除了每个 P 维护的 G 队列以外,还有一个全局的队列,每个 P 会周期性的查看全局队列中是否有 G 待运行并将其调度到 M 中执行,全局队列中 G 的来源,主要有从系统调用中恢复的 G。之所以 P 会周期性的查看全局队列,也是为了防止全局队列中的 G 被饿死。
系统调用
你现在可能想知道,为什么一定要有上下文(P)?我们能不能丢掉上下文而仅仅把 runqueue 放到线程上?不尽然。我们用上下文的原因是如果正在运行的线程因为某种原因需要阻塞的时候,我们可以把这些上下文移交给其它线程。
上面说到 P 的个数默认等于 CPU 核数,每个 M 必须持有一个 P 才可以执行 G,一般情况下 M 的个数会略大于 P 的个数,这多出来的 M 将会在 G 产生系统调用时发挥作用。
类似线程池,Go 也提供一个 M 的池子,需要时从池子中获取,用完放回池子,不够用时就再创建一个。
当 M 运行的某个 G 产生系统调用时,如下图所示:
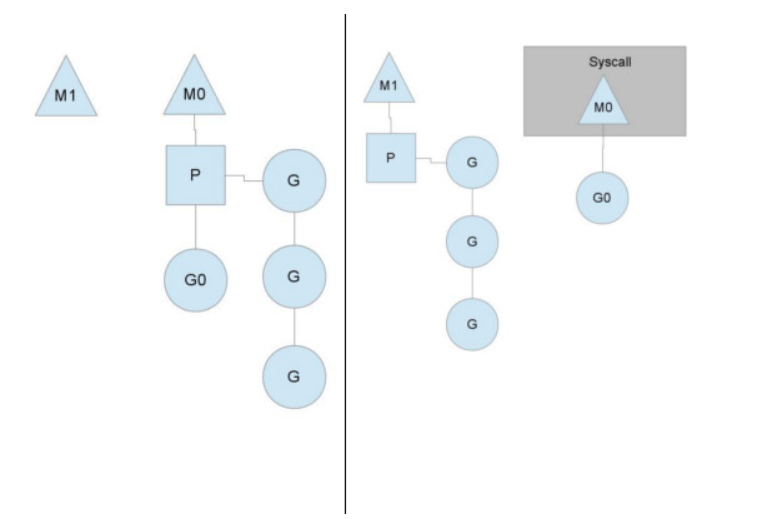
如图所示,M~0~ 中的 G~0~ 执行了 syscall,然后就创建了一个 M~1~ (也有可能本身就存在,没创建),当 G~0~ 即将进入系统调用时,M~0~ 将释放 P,进而某个空闲的 M~1~ 获取 P,继续执行 P 队列中剩下的 G。而 M0 由于陷入系统调用而进被阻塞,M1 接管 M0 的工作,只要 P 不空闲,就可以保证充分利用 CPU。
M1 的来源有可能是 M 的缓存池,也可能是新建的。当 G~0~ 系统调用结束后,跟据 M~0~ 是否能获取到 P,将会将 G~0~ 做不同的处理:
- 如果有空闲的 P,则获取一个 P,继续执行 G~0~。
- 如果没有空闲的 P,则将 G~0~ 放入全局队列,等待被其他的 P 调度。然后 M~0~ 将进入缓存池睡眠。
工作量窃取
多个 P 中维护的 G 队列有可能是不均衡的,比如下图:

竖线左侧中右边的 P 已经将 G 全部执行完,然后去查询全局队列,全局队列中也没有 G,而另一个 M 中除了正在运行的 G 外,队列中还有 3 个 G 待运行。此时,空闲的 P 会将其他 P 中的 G 偷取一部分过来,一般每次偷取一半。偷取完如右图所示。
GOMAXPROCS 设置对性能的影响
一般来讲,程序运行时就将 GOMAXPROCS 大小设置为 CPU 核数,可让 Go 程序充分利用 CPU。 在某些 IO 密集型的应用里,这个值可能并不意味着性能最好。
理论上当某个 Goroutine 进入系统调用时,会有一个新的 M 被启用或创建,继续占满 CPU。 但由于 Go 调度器检测到 M 被阻塞是有一定延迟的,也即旧的 M 被阻塞和新的 M 得到运行之间是有一定间隔的,所以在 IO 密集型应用中不妨把 GOMAXPROCS 设置的大一些,或许会有好的效果。
内存管理
本章主要介绍 GO 语言的自动垃圾回收机制。
自动垃圾回收是 GO 语言最大的特色之一,也是很有争议的话题。因为自动垃圾回收解放了程序员,使其不用担心内存泄露的问题,争议在于垃圾回收的性能,在某些应用场景下垃圾回收会暂时停止程序运行。
本章从内存分配原理讲起,然后再看垃圾回收原理,最后再聊一些与垃圾回收性能优化相关的话题。
内存分配原理
编写过 C 语言程序的肯定知道通过 malloc() 方法动态申请内存,其中内存分配器使用的是 glibc 提供的 ptmalloc2。
除了 glibc,业界比较出名的内存分配器有 Google 的 tcmalloc 和 Facebook 的 jemalloc。二者在避免内存碎片和性能上均比 glic 有比较大的优势,在多线程环境中效果更明显。
Golang 中也实现了内存分配器,原理与 tcmalloc 类似,简单的说就是维护一块大的全局内存,每个线程 (Golang 中为 P) 维护一块小的私有内存,私有内存不足再从全局申请。
另外,内存分配与 GC(垃圾回收)关系密切,所以了解 GC 前有必要了解内存分配的原理。
TCMalloc
引入虚拟内存后,让内存的并发访问问题的粒度从多进程级别,降低到多线程级别。
然而同一进程下的所有线程共享相同的内存空间,它们申请内存时需要加锁,如果不加锁就存在同一块内存被 2 个线程同时访问的问题。
TCMalloc 的做法是什么呢?为每个线程预分配一块缓存,线程申请小内存时,可以从缓存分配内存,这样有 2 个好处:
- 为线程预分配缓存需要进行 1 次系统调用,后续线程申请小内存时直接从缓存分配,都是在用户态执行的,没有了系统调用,缩短了内存总体的分配和释放时间,这是快速分配内存的第二个层次。
- 多个线程同时申请小内存时,从各自的缓存分配,访问的是不同的地址空间,从而无需加锁,把内存并发访问的粒度进一步降低了,这是快速分配内存的第三个层次。
下面就简单介绍下 TCMalloc,细致程度够我们理解 Go 的内存管理即可。

结合上图,介绍 TCMalloc 的几个重要概念:
- Page
操作系统对内存管理以页为单位,TCMalloc 也是这样,只不过 TCMalloc 里的 Page 大小与操作系统里的大小并不一定相等,而是倍数关系。《TCMalloc 解密》里称 x64 下 Page 大小是 8KB。
- Span
一组连续的 Page 被称为 Span,比如可以有 2 个页大小的 Span,也可以有 16 页大小的 Span,Span 比 Page 高一个层级,是为了方便管理一定大小的内存区域,Span 是 TCMalloc 中内存管理的基本单位。
- ThreadCache
ThreadCache 是每个线程各自的 Cache,一个 Cache 包含多个空闲内存块链表,每个链表连接的都是内存块,同一个链表上内存块的大小是相同的,也可以说按内存块大小,给内存块分了个类,这样可以根据申请的内存大小,快速从合适的链表选择空闲内存块。
由于每个线程有自己的 ThreadCache,所以 ThreadCache 访问是无锁的。
- CentralCache
CentralCache 是所有线程共享的缓存,也是保存的空闲内存块链表,链表的数量与 ThreadCache 中链表数量相同。
当 ThreadCache 的内存块不足时,可以从 CentralCache 获取内存块;
当 ThreadCache 内存块过多时,可以放回 CentralCache。
由于 CentralCache 是共享的,所以它的访问是要加锁的。
- PageHeap
PageHeap 是对堆内存的抽象,PageHeap 存的也是若干链表,链表保存的是 Span。
当 CentralCache 的内存不足时,会从 PageHeap 获取空闲的内存 Span,然后把 1 个 Span 拆成若干内存块,添加到对应大小的链表中并分配内存;
当 CentralCache 的内存过多时,会把空闲的内存块放回 PageHeap 中。
如下图所示,分别是 1 页 Page 的 Span 链表,2 页 Page 的 Span 链表等,最后是 large span set,这个是用来保存中大对象的。
毫无疑问,PageHeap 也是要加锁的。

前文提到了小、中、大对象,Go 内存管理中也有类似的概念,我们看一眼 TCMalloc 的定义:
小对象大小:0~256KB
中对象大小:257~1MB
大对象大小:>1MB
小对象的分配流程:
ThreadCache -> CentralCache -> HeapPage,大部分时候,ThreadCache 缓存都是足够的,不需要去访问 CentralCache 和 HeapPage,无系统调用配合无锁分配,分配效率是非常高的。中对象分配流程:直接在 PageHeap 中选择适当的大小即可,128 Page 的 Span 所保存的最大内存是 1MB。
大对象分配流程:从 large span set 选择合适数量的页面组成 span,用来存储数据。
通过本节的介绍,你应当对 TCMalloc 主要思想有一定了解了,我建议再回顾一下上面的内容。
基本概念
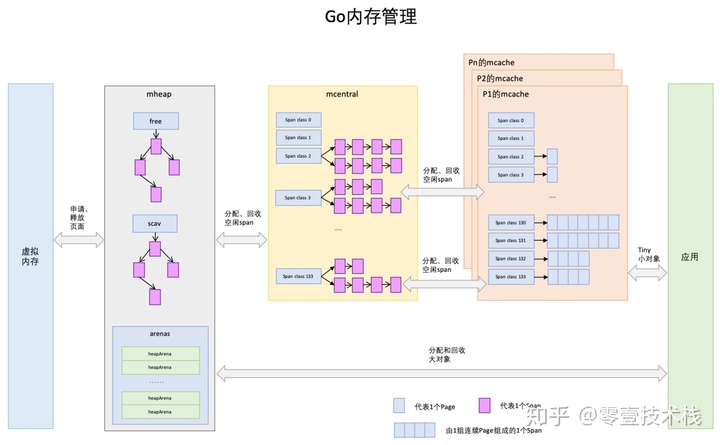
- Page
与 TCMalloc 中的 Page 相同,x64 架构下 1 个 Page 的大小是 8KB。上图的最下方,1 个浅蓝色的长方形代表 1 个 Page。
- Span
Span 与 TCMalloc 中的 Span 相同,Span 是内存管理的基本单位,代码中为 mspan,一组连续的 Page 组成 1 个 Span,所以上图最下方,一组连续的浅蓝色长方形代表的是一组 Page 组成的 1 个 Span,另外,1 个淡紫色长方形为 1 个 Span。
- mcache
mcache 与 TCMalloc 中的 ThreadCache 类似,mcache 保存的是各种大小的 Span,并按 Span class 分类,小对象直接从 mcache 分配内存,它起到了缓存的作用,并且可以无锁访问。
但是 mcache 与 ThreadCache 也有不同点,TCMalloc 中是每个线程 1 个 ThreadCache,Go 中是每个 P 拥有 1 个 mcache(其实是一样的)。因为在 Go 程序中,当前最多有 GOMAXPROCS 个线程在运行,所以最多需要 GOMAXPROCS 个 mcache 就可以保证各线程对 mcache 的无锁访问,线程的运行又是与 P 绑定的,把 mcache 交给 P 刚刚好。
- mcentral
mcentral 与 TCMalloc 中的 CentralCache 类似,是所有线程共享的缓存,需要加锁访问。
它按 Span 级别对 Span 分类,然后串联成链表,当 mcache 的某个级别 Span 的内存被分配光时,它会向 mcentral 申请 1 个当前级别的 Span。
但是 mcentral 与 CentralCache 也有不同点,CentralCache 是每个级别的 Span 有 1 个 链表,mcache 是每个级别的 Span 有 2 个链表,这和 mcache 申请内存有关,稍后再解释。
- mheap
mheap 与 TCMalloc 中的 PageHeap 类似,它是堆内存的抽象,把从 OS 申请出的内存页组织成 Span,并保存起来。
当 mcentral 的 Span 不够用时会向 mheap 申请内存,而 mheap 的 Span 不够用时会向 OS 申请内存。mheap 向 OS 的内存申请是按页来的,然后把申请来的内存页生成 Span 组织起来,同样也是需要加锁访问的。
但是 mheap 与 PageHeap 也有不同点:mheap 把 Span 组织成了树结构,而不是链表,并且还是 2 棵树,然后把 Span 分配到 heapArena 进行管理,它包含地址映射和 span 是否包含指针等位图,这样做的主要原因是为了更高效的利用内存:分配、回收和再利用。

- object size:代码里简称
size,指申请内存的对象大小。 - size class:代码里简称
class,它是 size 的级别,相当于把 size 归类到一定大小的区间段,比如 size[1,8] 属于 size class 1,size(8,16] 属于 size class 2。 - span class:指 span 的级别,但 span class 的大小与 span 的大小并没有正比关系。span class 主要用来和 size class 做对应,1 个 size class 对应 2 个 span class,2 个 span class 的 span 大小相同,只是功能不同,1 个用来存放包含指针的对象,一个用来存放不包含指针的对象,不包含指针对象的 Span 就无需 GC 扫描了。
- num of page:代码里简称
npage,代表 Page 的数量,其实就是 Span 包含的页数,用来分配内存。
内存分配
Go 中的内存分类并不像 TCMalloc 那样分成小、中、大对象,但是它的小对象里又细分了一个 Tiny 对象,Tiny 对象指大小在 1Byte 到 16Byte 之间并且不包含指针的对象。
小对象和大对象只用大小划定,无其他区分。

小对象是在 mcache 中分配的,而大对象是直接从 mheap 分配的,从小对象的内存分配看起。
概览
针对待分配对象的大小不同有不同的分配逻辑:
- (0, 16B) 且不包含指针的对象: Tiny 分配
- (0, 16B) 包含指针的对象:正常分配
- [16B, 32KB] : 正常分配
- (32KB, -) : 大对象分配
以申请 size 为 n 的内存为例,分配步骤如下:
- 获取当前线程的私有缓存 mcache
- 跟据 size 计算出适合的 class 的 ID
- 从 mcache 的 alloc[class] 链表中查询可用的 span
- 如果 mcache 没有可用的 span 则从 mcentral 申请一个新的 span 加入 mcache 中
- 如果 mcentral 中也没有可用的 span 则从 mheap 中申请一个新的 span 加入 mcentral
- 从该 span 中获取到空闲对象地址并返回
小对象的内存分配

大小转换这一小节,我们介绍了转换表,size class 从 1 到 66 共 66 个,代码中 _NumSizeClasses=67 代表了实际使用的 size class 数量,即 67 个,从 0 到 67,size class 0 实际并未使用到。
上文提到 1 个 size class 对应 2 个 span class:
| |
numSpanClasses 为 span class 的数量为 134 个,所以 span class 的下标是从 0 到 133,所以上图中 mcache 标注了的 span class 是:span class 0 到 span class 133。每 1 个 span class 都指向 1 个 span,也就是 mcache 最多有 134 个 span。
- 为对象寻找 span
寻找 span 的流程如下:
- 计算对象所需内存大小 size
- 根据 size 到 size class 映射,计算出所需的 size class
- 根据 size class 和对象是否包含指针计算出 span class
- 获取该 span class 指向的 span
以分配一个不包含指针的,大小为 24Byte 的对象为例,根据映射表:
| |
对应的 size class 为 3,它的对象大小范围是 (16,32]Byte,24Byte 刚好在此区间,所以此对象的 size class 为 3
Size class 到 span class 的计算如下:
| |
所以对应的 span class 为 7,所以该对象需要的是 span class 7 指向的 span。
| |
- 从 span 分配对象空间
Span 可以按对象大小切成很多份,这些都可以从映射表上计算出来,以 size class 3 对应的 span 为例,span 大小是 8KB,每个对象实际所占空间为 32Byte,这个 span 就被分成了 256 块,可以根据 span 的起始地址计算出每个对象块的内存地址。

随着内存的分配,span 中的对象内存块,有些被占用,有些未被占用,比如上图,整体代表 1 个 span,蓝色块代表已被占用内存,绿色块代表未被占用内存。当分配内存时,只要快速找到第一个可用的绿色块,并计算出内存地址即可,如果需要还可以对内存块数据清零。
当 span 内的所有内存块都被占用时,没有剩余空间继续分配对象,mcache 会向 mcentral 申请 1 个 span,mcache 拿到 span 后继续分配对象。
- mcache 向 mcentral 申请 span
mcentral 和 mcache 一样,都是 0~133 这 134 个 span class 级别,但每个级别都保存了 2 个 span list,即 2 个 span 链表:
- nonempty:这个链表里的 span,所有 span 都至少有 1 个空闲的对象空间。这些 span 是 mcache 释放 span 时加入到该链表的。
- empty:这个链表里的 span,所有的 span 都不确定里面是否有空闲的对象空间。当一个 span 交给 mcache 的时候,就会加入到 empty 链表。
这两个东西名称一直有点绕,建议直接把 empty 理解为没有对象空间就好了。

mcache 向 mcentral 申请 span 时,mcentral 会先从 nonempty 搜索满足条件的 span,如果没有找到再从 emtpy 搜索满足条件的 span,然后把找到的 span 交给 mcache。
- mheap 的 span 管理
mheap 里保存了两棵二叉排序树,按 span 的 page 数量进行排序:
- free:free 中保存的 span 是空闲并且非垃圾回收的 span。
- scav:scav 中保存的是空闲并且已经垃圾回收的 span。
如果是垃圾回收导致的 span 释放,span 会被加入到 scav,否则加入到 free,比如刚从 OS 申请的的内存也组成的 Span。

mheap 中还有 arenas,由一组 heapArena 组成,每一个 heapArena 都包含了连续的 pagesPerArena 个 span,这个主要是为 mheap 管理 span 和垃圾回收服务。mheap 本身是一个全局变量,它里面的数据,也都是从 OS 直接申请来的内存,并不在 mheap 所管理的那部分内存以内。
- mcentral 向 mheap 申请 span
当 mcentral 向 mcache 提供 span 时,如果 empty 里也没有符合条件的 span,mcentral 会向 mheap 申请 span。
此时,mcentral 需要向 mheap 提供需要的内存页数和 span class 级别,然后它优先从 free 中搜索可用的 span。
如果没有找到,会从 scav 中搜索可用的 span。
如果还没有找到,mheap 会向 OS 申请内存,再重新搜索 2 棵树,必然能找到 span。
如果找到的 span 比需要的 span 大,则把 span 进行分割成 2 个 span,其中 1 个刚好是需求大小,把剩下的 span 再加入到 free 中去,然后设置需要的 span 的基本信息,然后交给 mcentral。
- mheap 向 OS 申请内存
当 mheap 没有足够的内存时,mheap 会向 OS 申请内存,把申请的内存页保存为 span,然后把 span 插入到 free 树。
在 32 位系统中,mheap 还会预留一部分空间,当 mheap 没有空间时,先从预留空间申请,如果预留空间内存也没有了,才向 OS 申请。
大对象的内存分配
大对象的分配比小对象省事多了,99% 的流程与 mcentral 向 mheap 申请内存的相同,所以不重复介绍了。不同的一点在于 mheap 会记录一点大对象的统计信息,详情见 mheap.alloc_m()。
Go 垃圾回收和内存释放
如果只申请和分配内存,内存终将枯竭。Go 使用垃圾回收收集不再使用的 span,调用 mspan.scavenge() 把 span 释放还给 OS(并非真释放,只是告诉 OS 这片内存的信息无用了,如果你需要的话,收回去好了),然后交给 mheap,mheap 对 span 进行 span 的合并,把合并后的 span 加入 scav 树中,等待再分配内存时,由 mheap 进行内存再分配,Go 垃圾回收也是一个很强的主题,详见下一部分。
现在我们关注一下,Go 程序是怎么把内存释放给操作系统的?释放内存的函数是 sysUnused,它会被mspan.scavenge() 调用:
| |
注释说 _MADV_FREE_REUSABLE 与 MADV_FREE 的功能类似,它的功能是给内核提供一个建议:这个内存地址区间的内存已经不再使用,可以进行回收。但内核是否回收,以及什么时候回收,这就是内核的事情了。
如果内核真把这片内存回收了,当 Go 程序再使用这个地址时,内核会重新进行虚拟地址到物理地址的映射。所以在内存充足的情况下,内核也没有必要立刻回收内存。
Go 的栈内存
最后提一下栈内存。从一个宏观的角度看,内存管理不应当只有堆,也应当有栈。每个 goroutine 都有自己的栈,栈的初始大小是 2KB,100 万的 goroutine 会占用 2G,但 goroutine 的栈会在 2KB 不够用时自动扩容,当扩容为 4KB 的时候,百万 goroutine 会占用 4GB。
相关数据结构
为了方便自主管理内存,做法便是先向系统申请一块内存,然后将内存切割成小块,通过一定的内存分配算法管理内存。
以 64 位系统为例,Golang 程序启动时会向系统申请的内存如下图所示:

预申请的内存划分为 spans、bitmap、arena 三部分。其中 arena 即为所谓的堆区,应用中需要的内存从这里分配。其中 spans 和 bitmap 是为了管理 arena 区而存在的。
- arena 的大小为 512G,为了方便管理把 arena 区域划分成一个个的 page,每个 page 为 8KB,一共有 512GB/8KB 个页;
- spans 区域存放 span 的指针,每个指针对应一个 page,所以 span 区域的大小为 (512GB/8KB) * 指针大小 8byte = 512M
- bitmap 区域大小也是通过 arena 计算出来,不过主要用于 GC。
span
span 是用于管理 arena 页的关键数据结构,每个 span 中包含 1 个或多个连续页,为了满足小对象分配,span 中的一页会划分更小的粒度,而对于大对象比如超过页大小,则通过多页实现。
class
跟据对象大小,Golang 划分了一系列 class,每个 class 都代表一个固定大小的对象,以及每个 span 的大小。
如下表所示:
| |
上表中每列含义如下:
class:class ID,每个 span 结构中都有一个 class ID, 表示该 span 可处理的对象类型bytes/obj:该 class 代表对象的字节数bytes/span:每个 span 占用堆的字节数,也即:页数 * 页大小objects:每个 span 可分配的对象个数,也即(bytes/spans)/(bytes/obj)waste bytes:每个 span 产生的内存碎片,也即(bytes/spans)%(bytes/obj)
上表可见最大的对象是 32K 大小,超过 32K 大小的由特殊的 class 表示,该 class ID 为 0,每个 class 只包含一个对象。
span 数据结构
span 是内存管理的基本单位,每个 span 用于管理特定的 class 对象, 跟据对象大小,span 将一个或多个页拆分成多个块进行管理。
src/runtime/mheap.go:mspan 定义了其数据结构:
| |
以 class 10 为例:
- spanclass 为 10,参照 class 表可得出 npages=1, nelems=56, elemsize 为 144。
- 其中 startAddr 是在 span 初始化时就指定了某个页的地址。
- allocBits 指向一个位图,每位代表一个块是否被分配,若有两个块已经被分配,其 allocCount 也为 2。
next 和 prev 用于将多个 span 链接起来,这有利于管理多个 span,接下来会进行说明。
cache
有了管理内存的基本单位 span,还要有个数据结构来管理 span,这个数据结构叫 mcentral,各线程需要内存时从 mcentral 管理的 span 中申请内存,为了避免多线程申请内存时不断的加锁,Golang 为每个线程分配了 span 的缓存,这个缓存即是 cache。
src/runtime/mcache.go:mcache 定义了 cache 的数据结构:
| |
alloc 为 mspan 的指针数组,数组大小为 class 总数的 2 倍。
数组中每个元素代表了一种 class 类型的 span 列表,每种 class 类型都有两组 span 列表,第一组列表中所表示的对象中包含了指针,第二组列表中所表示的对象不含有指针,这么做是为了提高 GC 扫描性能,对于不包含指针的 span 列表,没必要去扫描。
根据对象是否包含指针,将对象分为 noscan 和 scan 两类,其中 noscan 代表没有指针,而 scan 则代表有指针,需要 GC 进行扫描。
mchache 在初始化时是没有任何 span 的,在使用过程中会动态的从 central 中获取并缓存下来,跟据使用情况,每种 class 的 span 个数也不相同。上图所示,class 0 的 span 数比 class1 的要多,说明本线程中分配的小对象要多一些。
central
cache 作为线程的私有资源为单个线程服务,而 central 则是全局资源,为多个线程服务,当某个线程内存不足时会向 central 申请,当某个线程释放内存时又会回收进 central。
src/runtime/mcentral.go:mcentral 定义了 central 数据结构:
| |
lock: 线程间互斥锁,防止多线程读写冲突spanclass: 每个 mcentral 管理着一组有相同 class 的 span 列表nonempty: 指还有内存可用的 span 列表empty: 指没有内存可用的 span 列表nmalloc: 指累计分配的对象个数
线程从 central 获取 span 步骤如下:
- 加锁
- 从 nonempty 列表获取一个可用 span,并将其从链表中删除
- 将取出的 span 放入 empty 链表
- 将 span 返回给线程
- 解锁
- 线程将该 span 缓存进 cache
线程将 span 归还步骤如下:
- 加锁
- 将 span 从 empty 列表删除
- 将 span 加入 noneempty 列表
- 解锁
上述线程从 central 中获取 span 和归还 span 只是简单流程,为简单起见,并未对具体细节展开。
heap
从 mcentral 数据结构可见,每个 mcentral 对象只管理特定的 class 规格的 span。事实上每种 class 都会对应一个 mcentral,这个 mcentral 的集合存放于 mheap 数据结构中。
src/runtime/mheap.go:mheap 定义了 heap 的数据结构:
| |
lock: 互斥锁spans: 指向 spans 区域,用于映射 span 和 page 的关系bitmap:bitmap 的起始地址arena_start: arena 区域首地址arena_used: 当前 arena 已使用区域的最大地址central: 每种 class 对应的两个 mcentral
从数据结构可见,mheap 管理着全部的内存,事实上 Golang 就是通过一个 mheap 类型的全局变量进行内存管理的。
系统预分配的内存分为 spans、bitmap、arean 三个区域,通过 mheap 管理起来。接下来看内存分配过程。
总结
Golang 内存分配是个相当复杂的过程,其中还掺杂了 GC 的处理。
- Golang 程序启动时申请一大块内存,并划分成 spans、bitmap、arena 区域
- arena 区域按页划分成一个个小块
- span 管理一个或多个页
- mcentral 管理多个 span 供线程申请使用
- mcache 作为线程私有资源,资源来源于 mcentral
Go 的内存分配原理主要强调两个重要的思想:
- 使用缓存提高效率。在存储的整个体系中到处可见缓存的思想,Go 内存分配和管理也使用了缓存,利用缓存一是减少了系统调用的次数,二是降低了锁的粒度、减少加锁的次数,从这 2 点提高了内存管理效率。
- 以空间换时间,提高内存管理效率。空间换时间是一种常用的性能优化思想,这种思想其实非常普遍,比如 Hash、Map、二叉排序树等数据结构的本质就是空间换时间,在数据库中也很常见,比如数据库索引、索引视图和数据缓存等,再如 Redis 等缓存数据库也是空间换时间的思想。
垃圾回收 GC
所谓垃圾就是不再需要的内存块,这些垃圾如果不清理就没办法再次被分配使用,在不支持垃圾回收的编程语言里,这些垃圾内存就是泄露的内存。
Golang 的垃圾回收(GC)也是内存管理的一部分,了解垃圾回收最好先了解前面介绍的内存分配原理。
常见的 GC 算法
业界常见的垃圾回收算法有以下几种:
- 引用计数:对每个对象维护一个引用计数,当引用该对象的对象被销毁时,引用计数减 1,当引用计数器为 0 是回收该对象。
- 优点:对象可以很快的被回收,不会出现内存耗尽或达到某个阀值时才回收。
- 缺点:不能很好的处理循环引用,而且实时维护引用计数,有也一定的代价。
- 代表语言:Python、PHP、Swift
- 标记 - 清除(mark and sweep):从根变量开始遍历所有引用的对象,引用的对象标记为"被引用",没有被标记的进行回收。
- 优点:解决了引用计数的缺点。
- 缺点:需要 STW,即要暂时停掉程序运行。
- 代表语言:Golang (其采用三色标记法)
- 分代收集:按照对象生命周期长短划分不同的代空间,生命周期长的放入老年代,而短的放入新生代,不同代有不能的回收算法和回收频率。
- 优点:回收性能好
- 缺点:算法复杂
- 代表语言: JAVA
Golang 的 GC
垃圾回收原理
简单的说,垃圾回收的核心就是以供后续内存分配时使用。
下图展示了一段内存,内存中即有已分配掉的内存,也有未分配的内存,垃圾回收的目标就是把那些已经分配的但没有对象引用的内存找出来并回收掉:

上图中,内存块 1、2、4 号位上的内存块已被分配(数字 1 代表已被分配,0 未分配)。
变量 a, b 为一指针,指向内存的 1、2 号位。内存块的 4 号位曾经被使用过,但现在没有任何对象引用了,就需要被回收掉。
垃圾回收开始时从 root 对象开始扫描,把 root 对象引用的内存标记为"被引用",考虑到内存块中存放的可能是指针,所以还需要递归的进行标记,全部标记完成后,只保留被标记的内存,未被标记的全部标识为未分配即完成了回收。
内存标记 (Mark)
前面介绍内存分配时,介绍过 span 数据结构,span 中维护了一个个内存块,并由一个位图 allocBits 表示每个内存块的分配情况。在 span 数据结构中还有另一个位图 gcmarkBits 用于标记内存块被引用情况。

如上图所示,allocBits 记录了每块内存分配情况,而 gcmarkBits 记录了每块内存标记情况。标记阶段对每块内存进行标记,有对象引用的的内存标记为 1 (如图中灰色所示),没有引用到的保持默认为 0。
allocBits 和 gcmarkBits 数据结构是完全一样的,标记结束就是内存回收,回收时将 allocBits 指向 gcmarkBits,则代表标记过的才是存活的,gcmarkBits 则会在下次标记时重新分配内存,非常的巧妙。
三色标记法
前面介绍了对象标记状态的存储方式,还需要有一个标记队列来存放待标记的对象,可以简单想象成把对象从标记队列中取出,将对象的引用状态标记在 span 的 gcmarkBits,把对象引用到的其他对象再放入队列中。
三色只是为了叙述上方便抽象出来的一种说法,实际上对象并没有颜色之分。这里的三色,对应了垃圾回收过程中对象的三种状态:
- 灰色:对象还在标记队列中等待
- 黑色:对象已被标记,gcmarkBits 对应的位为 1(该对象不会在本次 GC 中被清理)
- 白色:对象未被标记,gcmarkBits 对应的位为 0(该对象将会在本次 GC 中被清理)
✔️ 最开始所有对象都是白色的,然后把其中全局变量和函数栈里的对象置为灰色。第二步把灰色的对象全部置为黑色,然后把原先灰色对象指向的变量都置为灰色,以此类推。等发现没有对象可以被置为灰色时,所有的白色变量就一定是需要被清理的垃圾了。
例如,当前内存中有 A~F 一共 6 个对象,根对象 a,b 本身为栈上分配的局部变量,根对象 a、b 分别引用了对象 A、B, 而 B 对象又引用了对象 D,则 GC 开始前各对象的状态如下图所示:

初始状态下所有对象都是白色的。
接着开始扫描根对象 a、b:

由于根对象引用了对象 A、B,那么 A、B 变为灰色对象,接下来就开始分析灰色对象,分析 A 时,A 没有引用其他对象很快就转入黑色,B 引用了 D,则 B 转入黑色的同时还需要将 D 转为灰色,进行接下来的分析。如下图所示:

上图中灰色对象只有 D,由于 D 没有引用其他对象,所以 D 转入黑色。标记过程结束:

最终,黑色的对象会被保留下来,白色对象会被回收掉。
三色标记法因为多了一个白色的状态来存放不确定的对象,所以可以异步地执行。
Stop The World
对于垃圾回收来说,回收过程中需要控制住内存的变化,否则回收过程中指针传递会引起内存引用关系变化,如果错误地回收了还在使用的内存,结果将是灾难性的。
Golang 中的 STW(Stop The World)就是停掉所有的 goroutine,专心做垃圾回收,待垃圾回收结束后再恢复 goroutine。
STW 时间的长短直接影响了应用的执行,时间过长对于一些 web 应用来说是不可接受的,这也是广受诟病的原因之一。
为了缩短 STW 的时间,Golang 不断优化垃圾回收算法,这种情况得到了很大的改善。
GC 优化
写屏障 (Write Barrier)
前面说过 STW 目的是防止 GC 扫描时内存变化而停掉 goroutine,而写屏障就是让 goroutine 与 GC 同时运行的手段。虽然写屏障不能完全消除 STW,但是可以大大减少 STW 的时间。
写屏障类似一种开关,在 GC 的特定时机开启,开启后指针传递时会把指针标记,即本轮不回收,下次 GC 时再确定。
开始 gc 时启动内存写屏障,所有修改对象的操作加入一个写屏障,通知 gc 将受影响的对象变为灰色;然后在第一次 gc 后,重新对 gc 过程中变灰的对象再扫描一次
辅助 GC (Mutator Assist)
为了防止内存分配过快,在 GC 执行过程中,如果 goroutine 需要分配内存,那么这个 goroutine 会参与一部分 GC 的工作,即帮助 GC 做一部分工作,这个机制叫作 Mutator Assist。
GC 触发时机
内存分配量达到阀值触发 GC
每次内存分配时都会检查当前内存分配量是否已达到阀值,如果达到阀值则立即启动 GC。
| |
内存增长率由环境变量 GOGC 控制,默认为 100,即每当内存扩大一倍时启动 GC。
定期触发 GC
默认情况下,最长 2 分钟触发一次 GC,这个间隔在 src/runtime/proc.go:forcegcperiod 变量中被声明:
| |
手动触发
程序代码中也可以使用 runtime.GC() 来手动触发 GC。这主要用于 GC 性能测试和统计。
GC 性能优化
GC 性能与对象数量负相关,对象越多 GC 性能越差,对程序影响越大。
所以 GC 性能优化的思路之一就是减少对象分配个数,比如对象复用或使用大对象组合多个小对象等等。
另外,由于内存逃逸现象,有些隐式的内存分配也会产生,也有可能成为 GC 的负担。
关于 GC 性能优化的具体方法,后面单独介绍。
逃逸分析
所谓逃逸分析(Escape analysis)是指由编译器决定内存分配的位置,不需要程序员指定。 函数中申请一个新的对象
- 如果分配在栈中,则函数执行结束时,内存会自动回收;
- 如果分配在堆中,则函数执行结束可交给 GC(垃圾回收)处理;
有了逃逸分析,返回函数局部变量将变得可能,除此之外,逃逸分析还跟闭包息息相关,了解哪些场景下对象会逃逸至关重要。
逃逸策略
每当函数中申请新的对象,编译器会跟据该对象是否被函数外部引用来决定是否逃逸:
- 如果函数外部没有引用,则优先放到栈中;
- 如果函数外部存在引用,则必定放到堆中;
注意,对于函数外部没有引用的对象,也有可能放到堆中,比如内存过大超过栈的存储能力。
逃逸场景
指针逃逸
我们知道 Go 可以返回局部变量指针,这其实是一个典型的变量逃逸案例,示例代码如下:
| |
函数 StudentRegister() 内部 s 为局部变量,其值通过函数返回值返回,s 本身为一指针,其指向的内存地址不会是栈而是堆,这就是典型的逃逸案例。
通过编译参数 -gcflag=-m 可以查询编译过程中的逃逸分析:
| |
可见在 StudentRegister() 函数中,也即代码第 9 行显示 “escapes to heap”,代表该行内存分配发生了逃逸现象。
栈空间不足逃逸
看下面的代码,是否会产生逃逸呢?
| |
上面代码 Slice() 函数中分配了一个 1000 个长度的切片,是否逃逸取决于栈空间是否足够大。 直接查看编译提示,如下:
| |
我们发现此处并没有发生逃逸。那么把切片长度扩大 10 倍即 10000 会如何呢?
| |
我们发现当切片长度扩大到 10000 时就会逃逸。
实际上当栈空间不足以存放当前对象时或无法判断当前切片长度时会将对象分配到堆中。
动态类型逃逸
很多函数参数为 interface 类型,比如 fmt.Println(a ...interface{}),编译期间很难确定其参数的具体类型,也容易产生逃逸。 如下代码所示:
| |
上述代码 s 变量只是一个 string 类型变量,调用 fmt.Println() 时会产生逃逸:
| |
闭包引用对象逃逸
某著名的开源框架实现了某个返回 Fibonacci 数列的函数:
| |
该函数返回一个闭包,闭包引用了函数的局部变量 a 和 b,使用时通过该函数获取该闭包,然后每次执行闭包都会依次输出 Fibonacci 数列。 完整的示例程序如下所示:
| |
上述代码通过 Fibonacci() 获取一个闭包,每次执行闭包就会打印一个 Fibonacci 数值。输出如下所示:
| |
Fibonacci() 函数中原本属于局部变量的 a 和 b 由于闭包的引用,不得不将二者放到堆上,以致产生逃逸:
| |
逃逸总结
- 栈上分配内存比在堆中分配内存有更高的效率
- 栈上分配的内存不需要 GC 处理
- 堆上分配的内存使用完毕会交给 GC 处理
- 逃逸分析目的是决定内分配地址是栈还是堆
- 逃逸分析在编译阶段完成
编程 Tips
思考一下这个问题:函数传递指针真的比传值效率高吗? 我们知道传递指针可以减少底层值的拷贝,可以提高效率,但是如果拷贝的数据量小,由于指针传递会产生逃逸,可能会使用堆,也可能会增加 GC 的负担,所以传递指针不一定是高效的。
并发控制
本章主要介绍 GO 语言开发过程中经常使用的并发控制手段。
我们考虑这么一种场景,协程 A 执行过程中需要创建子协程 A1、A2、A3…An,协程 A 创建完子协程后就等待子协程退出。 针对这种场景,GO 提供了三种解决方案:
- Channel:使用 channel 控制子协程
- WaitGroup:使用信号量机制控制子协程
- Context:使用上下文控制子协程
三种方案各有优劣,比如 Channel 优点是实现简单,清晰易懂,WaitGroup 优点是子协程个数动态可调整,Context 优点是对子协程派生出来的孙子协程的控制。 缺点是相对而言的,要结合实例应用场景进行选择。
channel 一般用于协程之间的通信,channel 也可以用于并发控制。比如主协程启动 N 个子协程,主协程等待所有子协程退出后再继续后续流程,这种场景下 channel 也可轻易实现。
channel
下面程序展示一个使用 channel 控制子协程的例子:
| |
上面程序通过创建 N 个 channel 来管理 N 个协程,每个协程都有一个 channel 用于跟父协程通信,父协程创建完所有协程中等待所有协程结束。
这个例子中,父协程仅仅是等待子协程结束,其实父协程也可以向管道中写入数据通知子协程结束,这时子协程需要定期的探测管道中是否有消息出现。
总结
使用 channel 来控制子协程的优点是实现简单,缺点是当需要大量创建协程时就需要有相同数量的 channel,而且对于子协程继续派生出来的协程不方便控制。
后面继续介绍的 WaitGroup、Context 看起来比 channel 优雅一些,在各种开源组件中使用频率比 channel 高得多。
WaitGroup
WaitGroup 是 Golang 应用开发过程中经常使用的并发控制技术。
WaitGroup,可理解为 Wait-Goroutine-Group,即等待一组 goroutine 结束。比如某个 goroutine 需要等待其他几个 goroutine 全部完成,那么使用 WaitGroup 可以轻松实现。
下面程序展示了一个 goroutine 等待另外两个 goroutine 结束的例子:
| |
简单的说,上面程序中 wg 内部维护了一个计数器:
- 启动 goroutine 前将计数器通过
Add(2)将计数器设置为待启动的 goroutine 个数。 - 启动 goroutine 后,使用
Wait()方法阻塞自己,等待计数器变为 0。 - 每个 goroutine 执行结束通过
Done()方法将计数器减 1。 - 计数器变为 0 后,阻塞的 goroutine 被唤醒。
其实 WaitGroup 也可以实现一组 goroutine 等待另一组 goroutine,这有点像玩杂技,很容易出错,如果不了解其实现原理更是如此。实际上,WaitGroup 的实现源码非常简单。
基础知识
信号量
信号量是 Unix 系统提供的一种保护共享资源的机制,用于防止多个线程同时访问某个资源。
可简单理解为信号量为一个数值:
- 当信号量 > 0 时,表示资源可用,获取信号量时系统自动将信号量减 1;
- 当信号量 == 0 时,表示资源暂不可用,获取信号量时,当前线程会进入睡眠,当信号量为正时被唤醒;
由于 WaitGroup 实现中也使用了信号量,在此做个简单介绍。
WaitGroup
数据结构
源码包中 src/sync/waitgroup.go:WaitGroup 定义了其数据结构:
| |
state1 是个长度为 3 的数组,其中包含了 state 和一个信号量,而 state 实际上是两个计数器:
- counter:当前还未执行结束的 goroutine 计数器
- waiter count:等待 goroutine-group 结束的 goroutine 数量,即有多少个等候者
- semaphore:信号量
考虑到字节是否对齐,三者出现的位置不同,为简单起见,依照字节已对齐情况下,三者在内存中的位置如下所示:

WaitGroup 对外提供三个接口:
Add(delta int):将 delta 值加到 counter 中Wait():waiter 递增 1,并阻塞等待信号量 semaphoreDone():counter 递减 1,按照 waiter 数值释放相应次数信号量
下面分别介绍这三个函数的实现细节。
Add(delta int)
Add() 做了两件事,一是把 delta 值累加到 counter 中,因为 delta 可以为负值,也就是说 counter 有可能变成 0 或负值,所以第二件事就是当 counter 值变为 0 时,跟据 waiter 数值释放等量的信号量,把等待的 goroutine 全部唤醒,如果 counter 变为负值,则 panic。
Add() 伪代码如下:
| |
Wait()
Wait() 方法也做了两件事,一是累加 waiter,二是阻塞等待信号量
| |
这里用到了 CAS 算法保证有多个 goroutine 同时执行 Wait() 时也能正确累加 waiter。
Done()
Done() 只做一件事,即把 counter 减 1,我们知道 Add() 可以接受负值,所以 Done() 实际上只是调用了Add(-1)。
源码如下:
| |
Done() 的执行逻辑就转到了 Add(),实际上也正是最后一个完成的 goroutine 把等待者唤醒的。
编程 Tips
Add()操作必须早于Wait(),否则会 panicAdd()设置的值必须与实际等待的 goroutine 个数一致,否则会 panic
Context
Context 也叫作 “上下文”,是一个比较抽象的概念,一般理解为程序单元的一个运行状态、现场、快照。其中上下是指存在上下层的传递,上会把内容传递给下,程序单元则指的是 Goroutine。
Golang context 是 Golang 应用开发常用的并发控制技术,它与 WaitGroup 最大的不同点是 context 对于派生 goroutine 有更强的控制力,它可以控制多级的 goroutine。
每个 Goroutine 在执行之前,都要先知道程序当前的执行状态,通常将这些执行状态封装在一个 Context 变量中,传递给要执行的 Goroutine 中。
context 实际上只定义了接口,凡是实现该接口的类都可称为是一种 context,官方包中实现了几个常用的 context,分别可用于不同的场景。
典型的使用场景如下图所示:

上图中由于 goroutine 派生出子 goroutine,而子 goroutine 又继续派生新的 goroutine,这种情况下使用 WaitGroup 就不太容易,因为子 goroutine 个数不容易确定。而使用 context 就可以很容易实现。
接口定义
源码包中 src/context/context.go:Context 定义了该接口:
| |
基础的 context 接口只定义了 4 个方法,下面分别简要说明一下:
Deadline()
该方法返回一个 deadline 和标识是否已设置 deadline 的 bool 值,如果没有设置 deadline,则 ok == false,此时 deadline 为一个初始值的 time.Time 值
Done()
该方法返回一个 channel,需要在 select-case 语句中使用,如 case <-context.Done()
当 context 关闭后,
Done()返回一个被关闭的管道,关闭的管理仍然是可读的,据此 goroutine 可以收到关闭请求;当 context 还未关闭时,
Done()返回 nil。
Err()
该方法描述 context 关闭的原因。关闭原因由 context 实现控制,不需要用户设置。比如 Deadline context,关闭原因可能是因为 deadline,也可能提前被主动关闭,那么关闭原因就会不同:
- 因 deadline 关闭:“context deadline exceeded”;
- 因主动关闭: “context canceled”。
当 context 关闭后,Err() 返回 context 的关闭原因; 当 context 还未关闭时,Err() 返回 nil;
Value()
有一种 context,它不是用于控制呈树状分布的 goroutine,而是用于在树状分布的 goroutine 间传递信息。
Value() 方法就是用于此种类型的 context,该方法根据 key 值查询 map 中的 value。具体使用后面示例说明。
空 context
context 包中定义了一个空的 context, 名为 emptyCtx,用于 context 的根节点,空的 context 只是简单的实现了 Context,本身不包含任何值,仅用于其他 context 的父节点。
它是一个不可取消,没有设置截止时间,没有携带任何值的 Context。
emptyCtx 类型定义如下代码所示:
| |
context 包中定义了一个公用的 emptCtx 全局变量,名为 background,可以使用 context.Background() 获取它,实现代码如下所示:
| |
context 包提供了 4 个方法创建不同类型的 context,使用这四个方法时如果没有父 context,都需要传入 backgroud,即 backgroud 作为其父节点:
WithCancel()WithDeadline()WithTimeout()WithValue()
context 包中实现 Context 接口的 struct,除了 emptyCtx 外,还有 cancelCtx、timerCtx 和 valueCtx 三种,正是基于这三种 context 实例,实现了上述 4 种类型的 context。
context 包中各 context 类型之间的关系,如下图所示:
struct cancelCtx、timerCtx、valueCtx 都继承于 Context,下面分别介绍这三个 struct。
cancelCtx
源码包中 src/context/context.go:cancelCtx 定义了该类型 context:
| |
children 中记录了由此 context 派生的所有 child,此 context 被 cancle 时会把其中的所有 child 都 cancle 掉。
cancelCtx 与 deadline 和 value 无关,所以只需要实现 Done() 和 Err() 接口外露接口即可。
Done() 接口实现
按照 Context 定义,Done() 接口只需要返回一个 channel 即可,对于 cancelCtx 来说只需要返回成员变量 done 即可。
这里直接看下源码,非常简单:
| |
由于 cancelCtx 没有指定初始化函数,所以 cancelCtx.done 可能还未分配,所以需要考虑初始化。
cancelCtx.done 会在 context 被 cancel 时关闭,所以 cancelCtx.done 的值一般经历如三个阶段: nil –> chan struct{} –> closed chan。
Err() 接口实现
按照 Context 定义,Err() 只需要返回一个 error 告知 context 被关闭的原因。对于 cancelCtx 来说只需要返回成员变量 err 即可。
还是直接看下源码:
| |
cancelCtx.err 默认是 nil,在 context 被 cancel 时指定一个 error 变量: var Canceled = errors.New("context canceled")。
cancel() 接口实现
cancel() 内部方法是理解 cancelCtx 的最关键的方法,其作用是关闭自己和其后代,其后代存储在cancelCtx.children 的 map 中,其中 key 值即后代对象,value 值并没有意义,这里使用 map 只是为了方便查询而已。
cancel 方法实现伪代码如下所示:
| |
实际上,WithCancel() 返回的第二个用于 cancel context 的方法正是此 cancel()。
WithCancel() 方法实现
WithCancel() 方法作了三件事:
- 初始化一个 cancelCtx 实例
- 将 cancelCtx 实例添加到其父节点的 children 中 (如果父节点也可以被 cancel 的话)
- 返回 cancelCtx 实例和
cancel()方法
其实现源码如下所示:
| |
这里将自身添加到父节点的过程有必要简单说明一下:
- 如果父节点也支持 cancel,也就是说其父节点肯定有 children 成员,那么把新 context 添加到 children 里即可;
- 如果父节点不支持 cancel,就继续向上查询,直到找到一个支持 cancel 的节点,把新 context 添加到 children 里;
- 如果所有的父节点均不支持 cancel,则启动一个协程等待父节点结束,然后再把当前 context 结束。
典型使用案例
一个典型的使用 cancel context 的例子如下所示:
| |
上面代码中协程 HandelRequest() 用于处理某个请求,其又会创建两个协程:WriteRedis()、WriteDatabase(),main 协程创建创建 context,并把 context 在各子协程间传递,main 协程在适当的时机可以 cancel 掉所有子协程。
程序输出如下所示:
| |
timerCtx
源码包中 src/context/context.go:timerCtx 定义了该类型 context:
| |
timerCtx 在 cancelCtx 基础上增加了 deadline 用于标示自动 cancel 的最终时间,而 timer 就是一个触发自动 cancel 的定时器。
由此,衍生出 WithDeadline() 和 WithTimeout()。实现上这两种类型实现原理一样,只不过使用语境不一样:
- deadline: 指定最后期限,比如 context 将 2018.10.20 00:00:00 之时自动结束
- timeout: 指定最长存活时间,比如 context 将在 30s 后结束。
对于接口来说,timerCtx 在 cancelCtx 基础上还需要实现 Deadline() 和 cancel() 方法,其中 cancel() 方法是重写的。
Deadline() 接口实现
Deadline() 方法仅仅是返回 timerCtx.deadline 而已。而 timerCtx.deadline 是 WithDeadline() 或 WithTimeout() 方法设置的。
cancel() 接口实现
cancel() 方法基本继承 cancelCtx,只需要额外把 timer 关闭。
timerCtx 被关闭后,timerCtx.cancelCtx.err 将会存储关闭原因:
- 如果 deadline 到来之前手动关闭,则关闭原因与 cancelCtx 显示一致;
- 如果 deadline 到来时自动关闭,则原因为:“context deadline exceeded”
WithDeadline() 方法实现
WithDeadline() 方法实现步骤如下:
- 初始化一个 timerCtx 实例
- 将 timerCtx 实例添加到其父节点的 children 中(如果父节点也可以被 cancel 的话)
- 启动定时器,定时器到期后会自动 cancel 本 context
- 返回 timerCtx 实例和
cancel()方法
也就是说,timerCtx 类型的 context 不仅支持手动 cancel,也会在定时器到来后自动 cancel。
WithTimeout() 方法实现
WithTimeout() 实际调用了 WithDeadline,二者实现原理一致。
看代码会非常清晰:
| |
典型使用案例
下面例子中使用 WithTimeout() 获得一个 context 并在其子协程中传递:
| |
主协程中创建一个 10s 超时的 context,并将其传递给子协程,10s 自动关闭 context。程序输出如下:
| |
valueCtx
源码包中 src/context/context.go:valueCtx 定义了该类型 context:
| |
valueCtx 只是在 Context 基础上增加了一个 key-value 对,用于在各级协程间传递一些数据。
由于 valueCtx 既不需要 cancel,也不需要 deadline,那么只需要实现 Value() 接口即可。
Value() 接口实现
由 valueCtx 数据结构定义可见,valueCtx.key 和 valueCtx.val 分别代表其 key 和 value 值。 实现也很简单:
| |
这里有个细节需要关注一下,即当前 context 查找不到 key 时,会向父节点查找,如果查询不到则最终返回interface{}。也就是说,可以通过子 context 查询到父的 value 值。
WithValue() 方法实现
WithValue() 实现也是非常的简单, 伪代码如下:
| |
典型使用案例
下面示例程序展示 valueCtx 的用法:
| |
上例 main() 中通过 WithValue() 方法获得一个 context,需要指定一个父 context、key 和 value。然后将该 context 传递给子协程 HandelRequest,子协程可以读取到 context 的 key-value。
注意:本例中子协程无法自动结束,因为 context 是不支持 cancel 的,也就是说 <-ctx.Done() 永远无法返回。如果需要返回,需要在创建 context 时指定一个可以 cancel 的 context 作为父节点,使用父节点的 cancel() 在适当的时机结束整个 context。
总结
- Context 仅仅是一个接口定义,跟据实现的不同,可以衍生出不同的 context 类型;
cancelCtx实现了 Context 接口,通过WithCancel()创建cancelCtx实例;timerCtx实现了 Context 接口,通过WithDeadline()和WithTimeout()创建timerCtx实例;valueCtx实现了 Context 接口,通过WithValue()创建valueCtx实例;- 三种 context 实例可互为父节点,从而可以组合成不同的应用形式;
反射概念
官方对此有个非常简明的介绍,两句话耐人寻味:
- 反射提供一种让程序检查自身结构的能力
- 反射是困惑的源泉
第 1 条,再精确点的描述是 “反射是一种检查 interface 变量的底层类型和值的机制”。 第 2 条,很有喜感的自嘲,不过往后看就笑不出来了,因为你很可能产生困惑.
想深入了解反射,必须深入理解类型和接口概念。下面开始复习一下这些基础概念。
关于静态类型
你肯定知道 Go 是静态类型语言,比如 “int"、"float32"、"[]byte” 等等。每个变量都有一个静态类型,且在编译时就确定了。 那么考虑一下如下一种类型声明:
| |
Q: i 和 j 类型相同吗? A:i 和 j 类型是不同的。 二者拥有不同的静态类型,没有类型转换的话是不可以互相赋值的,尽管二者底层类型是一样的。
特殊的静态类型 interface
interface 类型是一种特殊的类型,它代表方法集合。 它可以存放任何实现了其方法的值。
经常被拿来举例的是 io 包里的这两个接口类型:
| |
任何类型,比如某 struct,只要实现了其中的 Read() 方法就被认为是实现了 Reader 接口,只要实现了 Write() 方法,就被认为是实现了 Writer 接口,不过方法参数和返回值要跟接口声明的一致。
接口类型的变量可以存储任何实现该接口的值。
特殊的 interface 类型
最特殊的 interface 类型为空 interface 类型,即 interface {}
interface 类型的方法集合为空,也就是说所有类型都可以认为是实现了该接口。
一个类型实现空 interface 并不重要,重要的是一个空 interface 类型变量可以存放所有值,记住是所有值,这才是最最重要的。 这也是有些人认为 Go 是动态类型的原因,这是个错觉。
interface 类型是如何表示的
前面讲了,interface 类型的变量可以存放任何实现了该接口的值。还是以上面的 io.Reader 为例进行说明,io.Reader 是一个接口类型,os.OpenFile() 方法返回一个 File 结构体类型变量,该结构体类型实现了io.Reader 的方法,那么 io.Reader 类型变量就可以用来接收该返回值。如下所示:
| |
那么问题来了。 Q: r 的类型是什么? A: r 的类型始终是 io.Reader interface 类型,无论其存储什么值。
Q:那 File 类型体现在哪里? A:r 保存了一个 (value, type) 对来表示其所存储值的信息。 value 即为 r 所持有元素的值,type 即为所持有元素的底层类型
Q:如何将 r 转换成另一个类型结构体变量?比如转换成 io.Writer A:使用类型断言,如 w = r.(io.Writer). 意思是如果 r 所持有的元素如果同样实现了 io.Writer 接口,那么就把值传递给 w。
反射三定律
前面之所以讲类型,是为了引出 interface,之所以讲 interface 是想说 interface 类型有个 (value,type) 对,而反射就是检查 interface 的这个 (value, type) 对的。
具体一点说就是 Go 提供一组方法提取 interface 的 value,提供另一组方法提取 interface 的 type.
官方提供了三条定律来说明反射,比较清晰,下面也按照这三定律来总结。
反射包里有两个接口类型要先了解一下.
reflect.Type提供一组接口处理 interface 的类型,即(value, type)中的 typereflect.Value提供一组接口处理 interface 的值,即 (value, type) 中的 value
下面会提到反射对象,所谓反射对象即反射包里提供的两种类型的对象。
reflect.Type类型对象reflect.Value类型对象
反射第一定律:反射可以将 interface 类型变量转换成反射对象
下面示例,看看是如何通过反射获取一个变量的值和类型的:
| |
程序输出如下:
| |
注意:反射是针对 interface 类型变量的,其中 TypeOf() 和 ValueOf() 接受的参数都是 interface{} 类型的,也即 x 值是被转成了 interface 传入的。
除了 reflect.TypeOf() 和 reflect.ValueOf(),还有其他很多方法可以操作,本文先不过多介绍,否则一不小心会会引起困惑。
反射第二定律:反射可以将反射对象还原成 interface 对象
之所以叫’反射’,反射对象与 interface 对象是可以互相转化的。看以下例子:
| |
对象 x 转换成反射对象 v,v 又通过 Interface() 接口转换成 interface 对象,interface 对象通过 .(float64) 类型断言获取 float64 类型的值。
反射第三定律:反射对象可修改,value 值必须是可设置的
通过反射可以将 interface 类型变量转换成反射对象,可以使用该反射对象设置其持有的值。在介绍何谓反射对象可修改前,先看一下失败的例子:
| |
如下代码,通过反射对象 v 设置新值,会出现 panic。报错如下:
| |
错误原因即是 v 是不可修改的。
反射对象是否可修改取决于其所存储的值,回想一下函数传参时是传值还是传址就不难理解上例中为何失败了。
上例中,传入 reflect.ValueOf() 函数的其实是 x 的值,而非 x 本身。即通过 v 修改其值是无法影响 x 的,也即是无效的修改,所以 golang 会报错。
想到此处,即可明白,如果构建 v 时使用 x 的地址就可实现修改了,但此时 v 代表的是指针地址,我们要设置的是指针所指向的内容,也即我们想要修改的是 *v。 那怎么通过 v 修改 x 的值呢?
reflect.Value 提供了 Elem() 方法,可以获得指针向指向的 value。看如下代码:
| |
输出为:
| |
总结
结合官方博客及本文,至少可以对反射理解个大概,还有很多方法没有涉及。 对反射的深入理解,个人觉得还需要继续看的内容:
- 参考业界,尤其是开源框架中是如何使用反射的
- 研究反射实现原理,探究其性能优化的手段
语法糖
简短变量声明 :=
题目
一
问:下面代码输出什么?
| |
程序输出如下:
| |
再进一步想一下,前一个语句中已经声明了 i, 为什么还可以再次声明呢?
二
问:下面代码为什么不能通过编译?
| |
不能通过编译原因是形参已经声明了变量 i,使用 := 再次声明是不允许的。
再进一步想一下,编译时会报 “no new variable on left side of :=” 错误,该怎么理解?
三
问:下面代码输出什么?
| |
程序输出如下:
| |
这里要注意的是,block if 中声明的 j,与上面的 j 属于不同的作用域。
规则
多变量赋值可能会重新声明
我们知道使用 := 一次可以声明多个变量,像下面这样:
| |
上面代码定义了两个变量,并用函数返回值进行赋值。
如果这两个变量中的一个再次出现在 := 左侧就会重新声明。像下面这样,offset 被重新声明:
| |
重新声明并没有什么问题,它并没有引入新的变量,只是把变量的值改变了,但要明白,这是 Go 提供的一个语法糖。
- 当
:=左侧存在新变量时(如 field2),那么已声明的变量(如 offset)则会被重新声明,不会有其他额外副作用。 - 当
:=左侧没有新变量是不允许的,编译会提示no new variable on left side of :=。
我们所说的重新声明不会引入问题要满足一个前提,变量声明要在同一个作用域中出现。
如果出现在不同的作用域,那很可能就创建了新的同名变量,同一函数不同作用域的同名变量往往不是预期做法,很容易引入缺陷。关于作用域的这个问题,我们在本节后面介绍。
不能用于函数外部
简短变量场景只能用于函数中,使用 := 来声明和初始化全局变量是行不通的。
比如,像下面这样:
| |
这里的编译错误提示 syntax error: non-declaration statement outside function body,表示非声明语句不能出现在函数外部。可以理解成 := 实际上会拆分成两个语句,即声明和赋值。赋值语句不能出现在函数外部的。
变量作用域
几乎所有的工程师都了解变量作用域,但是由于 := 使用过于频繁的话,还是有可能掉进陷阱里。
| |
注意上面声明的三个 err 变量。 2 号 err 与 1 号 err 不属于同一个作用域,:= 声明了新的变量,所以 2 号 err 与 1 号 err 属于两个变量。 2 号 err 与 3 号 err 属于同一个作用域,:= 重新声明了 err 但没创建新的变量,所以 2 号 err 与 3 号 err 是同一个变量。
如果误把 2 号 err 与 1 号 err 混淆,就很容易产生意想不到的错误。
可变参函数
可变参函数是指函数的某个参数可有可无,即这个参数个数可以是 0 个或多个。 声明可变参数函数的方式是在参数类型前加上 ... 前缀。
比如 fmt 包中的 Println:
| |
函数特征
我们先写一个可变参函数:
| |
Greeting 函数负责给指定的人打招呼,其参数 who 为可变参数。
这个函数几乎把可变参函数的特征全部表现出来了:
- 可变参数必须在函数参数列表的尾部,即最后一个(如放前面会引起编译时歧义);
- 可变参数在函数内部是作为切片来解析的;
- 可变参数可以不填,不填时函数内部当成
nil切片处理; - 可变参数必须是相同类型的(如果需要是不同类型的可以定义为
interface{}类型);
使用举例
我们使用 testing 包中的 Example 函数来说明上面 Greeting 函数(函数位于 sugar 包中)用法。
不传值
调用可变参函数时,可变参部分是可以不传值的,例如:
| |
这里没有传递第二个参数。可变参数不传递的话,默认为 nil。
传递多个参数
调用可变参函数时,可变参数部分可以传递多个值,例如:
| |
可变参数可以有多个。多个参数将会生成一个切片传入,函数内部按照切片来处理。
传递切片
调用可变参函数时,可变参数部分可以直接传递一个切片。参数部分需要使用 slice... 来表示切片。例如:
| |
此时需要注意的一点是,切片传入时不会生成新的切片,也就是说函数内部使用的切片与传入的切片共享相同的存储空间。
说得再直白一点就是,如果函数内部修改了切片,可能会影响外部调用的函数。
总结
- 可变参数必须要位于函数列表尾部;
- 可变参数是被当作切片来处理的;
- 函数调用时,可变参数可以不填;
- 函数调用时,可变参数可以填入切片;