Docker
Docker
摘自:https://yeasy.gitbook.io/docker_practice/
什么是 Docker
摘自:https://zhuanlan.zhihu.com/p/187505981
容器技术 vs 虚拟机
从空间和时间两个维度考虑
和一个单纯的应用程序相比,操作系统是一个很重而且很笨的程序
操作系统运行起来是需要占用很多资源的,刚装好的系统还什么都没有部署,单纯的操作系统其磁盘占用至少几十 G 起步,内存要几个 G 起步。
假设我有一台机器,16G 内存,需要部署三个应用,那么使用虚拟机技术可以这样划分:

在这台机器上开启三个虚拟机,每个虚拟机上部署一个应用,其中 VM1 占用 2G 内存,VM2 占用 1G 内存,VM3 占用了 4G 内存。
我们可以看到虚拟本身就占据了总共 7G 内存,因此我们没有办法划分出更多虚拟机从而部署更多的应用程序,可是我们部署的是应用程序,要用的也是应用程序而不是操作系统。
如果有一种技术可以让我们避免把内存浪费在 “无用” 的操作系统上岂不是太香?这是问题一,主要原因在于操作系统太重了。
还有另一个问题,那就是启动时间问题,我们知道操作系统重启是非常慢的,因为操作系统要从头到尾把该检测的都检测了该加载的都加载上,这个过程非常缓慢,动辄数分钟,因此操作系统还是太笨了。
那么有没有一种技术可以让我们获得虚拟机的好处又能克服这些缺点从而一举实现鱼和熊掌的兼得呢?
答案是肯定的,这就是容器技术。
什么是容器
容器一词的英文是 container,其实 container 还有集装箱的意思,而容器和集装箱在概念上是很相似的。
现代软件开发的一大目的就是隔离,应用程序在运行时相互独立互不干扰,这种隔离实现起来是很不容易的,其中一种解决方案就是上面提到的虚拟机技术,通过将应用程序部署在不同的虚拟机中从而实现隔离:
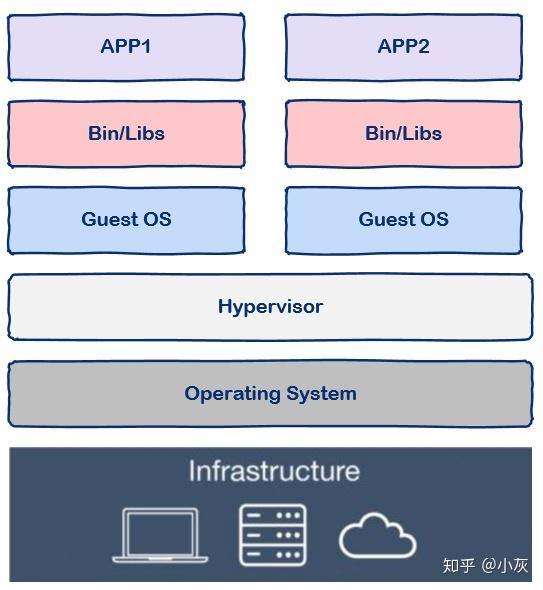
但是虚拟机技术有上述提到的各种缺点,那么容器技术又怎么样呢?
与虚拟机通过操作系统实现隔离不同,容器技术
- 只隔离应用程序的运行时环境
- 容器之间可以共享同一个操作系统
这里的运行时环境指的是程序运行依赖的各种库以及配置。
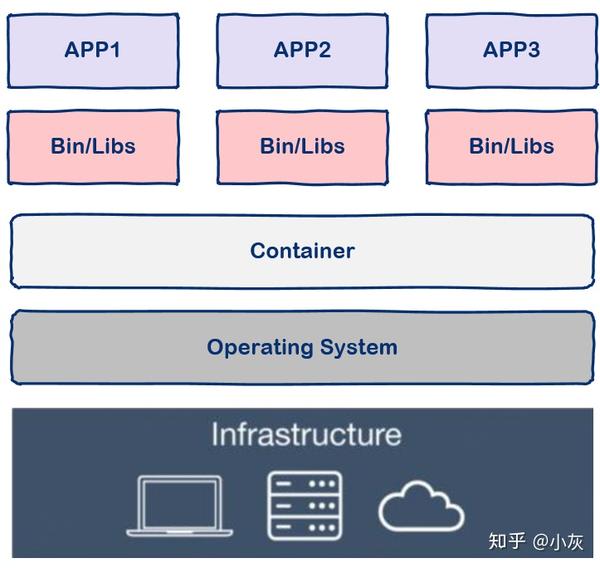
从图中我们可以看到容器更加的轻量级且占用的资源更少,与操作系统动辄几 G 的内存占用相比,容器技术只需数 M 空间,因此我们可以在同样规格的硬件上大量部署容器,这是虚拟机所不能比拟的,而且不同于操作系统数分钟的启动时间容器几乎瞬时启动,容器技术为打包服务栈提供了一种更加高效的方式,So cool。
那么我们该怎么使用容器呢?这就要讲到 docker 了。
注意,容器是一种通用技术,docker 只是其中的一种实现。
什么是 docker
docker 是一个用 Go 语言实现的开源项目,可以让我们方便的创建和使用容器,docker 将程序以及程序所有的依赖都打包到 docker container,这样你的程序可以在任何环境都会有一致的表现,这里程序运行的依赖也就是容器。
就好比集装箱,容器所处的操作系统环境就好比货船或港口,程序的表现只和集装箱有关系(容器),和集装箱放在哪个货船或者哪个港口 (操作系统) 没有关系。
因此我们可以看到 docker 可以屏蔽环境差异,也就是说,只要你的程序打包到了 docker 中,那么无论运行在什么环境下程序的行为都是一致的,程序员再也无法施展表演才华了,不会再有 “在我的环境上可以运行”,真正实现 “build once, run everywhere”。
此外 docker 的另一个好处就是快速部署,这是当前互联网公司最常见的一个应用场景,一个原因在于容器启动速度非常快,另一个原因在于只要确保一个容器中的程序正确运行,那么你就能确信无论在生产环境部署多少都能正确运行。
如何使用 docker
docker 中有这样几个概念:
- dockerfile
- image
- container
实际上你可以简单的把
- dockerfile 理解为源代码
- image 理解为可执行程序
- container 就是运行起来的进程
- docker 就是 " 编译器 “。
官方文档的术语解释:
A Dockerfile is simply a text-based script of instructions that is used to create a container image.
A container is a sandboxed process on your machine that is isolated from all other processes on the host machine.
因此我们只需要在 dockerfile 中指定需要哪些程序、依赖什么样的配置,之后把 dockerfile 交给“编译器” docker 进行“编译”,也就是 docker build 命令,生成的可执行程序就是 image,之后就可以运行这个 image 了,这就是 docker run 命令,image 运行起来后就是 docker container。
docker 是如何工作的
实际上 docker 使用了常见的 CS 架构,也就是 client-server 模式,docker client 负责处理用户输入的各种命令,比如 docker build、docker run,真正工作的其实是 server,也就是 docker daemon
值得注意的是,docker client 和 docker demon 可以运行在同一台机器上。
接下来我们用几个命令来讲解一下 docker 的工作流程:
docker build
当我们写完 dockerfile 交给 docker “编译” 时使用这个命令,那么 client 在接收到请求后转发给 docker daemon,接着 docker daemon 根据 dockerfile 创建出 “可执行程序” image。

docker run
有了 “可执行程序” image 后就可以运行程序了,接下来使用命令 docker run,docker daemon 接收到该命令后找到具体的 image,然后加载到内存开始执行,image 执行起来就是所谓的 container。

docker pull
其实 docker build 和 docker run 是两个最核心的命令,会用这两个命令基本上 docker 就可以用起来了,剩下的就是一些补充。
那么 docker pull 是什么意思呢?
我们之前说过,docker 中 image 的概念就类似于“可执行程序”,我们可以从哪里下载到别人写好的应用程序呢?很简单,就是 Docker Hub,docker 官方的“应用商店”,你可以在这里下载到别人编写好的 image,这样你就不用自己编写 dockerfile 了。
docker registry 可以用来存放各种 image,公共的可以供任何人下载 image 的仓库就是 docker Hub。那么该怎么从 Docker Hub 中下载 image 呢,就是这里的 docker pull 命令了。
因此,这个命令的实现也很简单,那就是用户通过 docker client 发送命令,docker daemon 接收到命令后向 docker registry 发送 image 下载请求,下载后存放在本地,这样我们就可以使用 image 了。

最后,让我们来看一下 docker 的底层实现。
docker 的底层实现
docker 基于 Linux 内核提供这样几项功能实现的:
- NameSpace 我们知道 Linux 中的 PID、IPC、网络等资源是全局的,而 NameSpace 机制是一种资源隔离方案,在该机制下这些资源就不再是全局的了,而是属于某个特定的 NameSpace,各个 NameSpace 下的资源互不干扰,这就使得每个 NameSpace 看上去就像一个独立的操作系统一样,但是只有 NameSpace 是不够。
- Control groups 虽然有了 NameSpace 技术可以实现资源隔离,但进程还是可以不受控的访问系统资源,比如 CPU、内存、磁盘、网络等,为了控制容器中进程对资源的访问,Docker 采用 control groups 技术(也就是 cgroup),有了 cgroup 就可以控制容器中进程对系统资源的消耗了,比如你可以限制某个容器使用内存的上限、可以在哪些 CPU 上运行等等。
有了这两项技术,容器看起来就真的像是独立的操作系统了。
安装
Ubuntu
使用 APT 安装
由于 apt 源使用 HTTPS 以确保软件下载过程中不被篡改。因此,我们首先需要添加使用 HTTPS 传输的软件包以及 CA 证书。
| |
为了确认所下载软件包的合法性,需要添加软件源的 GPG 密钥。
| |
然后,我们需要向 sources.list 中添加 Docker 软件源
| |
以上命令会添加稳定版本的 Docker APT 镜像源,如果需要测试版本的 Docker 请将 stable 改为 test。
更新 apt 软件包缓存,并安装 docker-ce:
| |
启动 Docker
| |
测试
| |
若能正常输出以上信息,则说明安装成功。
建立 docker 用户组
默认情况下,docker 命令会使用 Unix socket 与 Docker 引擎通讯。而只有 root 用户和 docker 组的用户才可以访问 Docker 引擎的 Unix socket。出于安全考虑,一般 Linux 系统上不会直接使用 root 用户。因此,更好地做法是将需要使用 docker 的用户加入 docker 用户组。
建立 docker 组:
| |
将当前用户加入 docker 组:
| |
使用镜像
Docker 镜像 是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。镜像 不包含 任何动态数据,其内容在构建之后也不会被改变。
获取镜像 docker pull
从 Docker 镜像仓库获取镜像的命令是 docker pull。其命令格式为:
| |
具体的选项可以通过 docker pull --help 命令看到,这里我们说一下镜像名称的格式。
- Docker 镜像仓库地址:地址的格式一般是
<域名/IP>[:端口号]。- 默认地址是 Docker Hub (
docker.io)
- 默认地址是 Docker Hub (
- 仓库名:两段式名称,即 <用户名>/<软件名>。
- 对于 Docker Hub,如果不给出用户名,则默认为
library,也就是官方镜像。
- 对于 Docker Hub,如果不给出用户名,则默认为
例
| |
上面的命令中没有给出 Docker 镜像仓库地址,因此将会从 Docker Hub (docker.io)获取镜像。镜像名称是 ubuntu:18.04,因此将会获取官方镜像 library/ubuntu 仓库中标签为 18.04 的镜像。
下载过程:
| |
从下载过程中可以看到我们之前提及的分层存储的概念,镜像是由多层存储所构成。下载也是一层层的去下载,并非单一文件。
下载过程中给出了每一层的 ID 的前 12 位。并且下载结束后,给出该镜像完整的 sha256 的摘要,以确保下载一致性。
试运行
以上面的 ubuntu:18.04 为例,如果我们打算启动里面的 bash 并且进行交互式操作的话,可以执行下面的命令。
| |
-it:这是两个参数-i:交互式操作-t终端。我们这里打算进入bash执行一些命令并查看返回结果,因此我们需要交互式终端。
--rm:这个参数是说容器退出后随之将其删除。- 默认情况下,为了排障需求,退出的容器并不会立即删除,除非手动
docker rm。 - 我们这里只是随便执行个命令,看看结果,不需要排障和保留结果,因此使用
--rm可以避免浪费空间。
- 默认情况下,为了排障需求,退出的容器并不会立即删除,除非手动
ubuntu:18.04:这是指用ubuntu:18.04镜像为基础来启动容器。bash:放在镜像名后的是 命令,这里我们希望有个交互式 Shell,因此用的是bash。
列出镜像 docker image ls
要想列出已经下载下来的镜像,可以使用 docker image ls 命令。
| |
列表包含了 仓库名、标签、镜像 ID、创建时间 以及 所占用的空间。
镜像 ID 则是镜像的唯一标识,一个镜像可以对应多个 标签。因此,在上面的例子中,我们可以看到 ubuntu:18.04 和 ubuntu:bionic 拥有相同的 ID,因为它们对应的是同一个镜像。
镜像体积
如果仔细观察,会注意到,这里标识的所占用空间和在 Docker Hub 上看到的镜像大小不同。比如,ubuntu:18.04 镜像大小,在这里是 63.3MB,但是在 Docker Hub 显示的却是 25.47 MB。
这是因为 Docker Hub 中显示的体积是压缩后的体积。在镜像下载和上传过程中镜像是保持着压缩状态的,因此 Docker Hub 所显示的大小是网络传输中更关心的流量大小。
而 docker image ls 显示的是镜像下载到本地后,展开的大小,准确说,是展开后的各层所占空间的总和,因为镜像到本地后,查看空间的时候,更关心的是本地磁盘空间占用的大小。
另外一个需要注意的问题是,docker image ls 列表中的镜像体积总和并非是所有镜像实际硬盘消耗。由于 Docker 镜像是多层存储结构,并且可以继承、复用,因此不同镜像可能会因为使用相同的基础镜像,从而拥有共同的层。由于 Docker 使用 Union FS,相同的层只需要保存一份即可,因此实际镜像硬盘占用空间很可能要比这个列表镜像大小的总和要小的多。
你可以通过 docker system df 命令来便捷的查看镜像、容器、数据卷所占用的空间。
| |
虚悬镜像
上面的镜像列表中,还可以看到一个特殊的镜像,这个镜像既没有仓库名,也没有标签,均为 <none>。
| |
这个镜像原本是有镜像名和标签的,原来为 mongo:3.2,随着官方镜像维护,发布了新版本后,重新 docker pull mongo:3.2 时,mongo:3.2 这个镜像名被转移到了新下载的镜像身上,而旧的镜像上的这个名称则被取消,从而成为了 <none>。
除了 docker pull 可能导致这种情况,docker build 也同样可以导致这种现象。由于新旧镜像同名,旧镜像名称被取消,从而出现仓库名、标签均为 <none> 的镜像。这类无标签镜像也被称为虚悬镜像(dangling image) ,可以用下面的命令专门显示这类镜像:
| |
一般来说,虚悬镜像已经失去了存在的价值,是可以随意删除的,可以用下面的命令删除。
| |
中间层镜像
为了加速镜像构建、重复利用资源,Docker 会利用 中间层镜像。所以在使用一段时间后,可能会看到一些依赖的中间层镜像。默认的 docker image ls 列表中只会显示顶层镜像,如果希望显示包括中间层镜像在内的所有镜像的话,需要加 -a 参数。
| |
这样会看到很多无标签的镜像,与之前的虚悬镜像不同,这些无标签的镜像很多都是中间层镜像,是其它镜像所依赖的镜像。
这些无标签镜像不应该删除,否则会导致上层镜像因为依赖丢失而出错。
实际上,这些镜像也没必要删除,因为之前说过,相同的层只会存一遍,而这些镜像是别的镜像的依赖,因此并不会因为它们被列出来而多存了一份,无论如何你也会需要它们。只要删除那些依赖它们的镜像后,这些依赖的中间层镜像也会被连带删除。
列出部分镜像
不加任何参数的情况下,docker image ls 会列出所有顶层镜像,但是有时候我们只希望列出部分镜像。docker image ls 有好几个参数可以帮助做到这个事情。
根据仓库名列出镜像
| |
列出特定的某个镜像,也就是说指定仓库名和标签
| |
除此以外,docker image ls 还支持强大的过滤器参数 --filter,或者简写 -f。
之前我们已经看到了使用过滤器来列出虚悬镜像的用法,它还有更多的用法。比如,我们希望看到在 mongo:3.2 之后建立的镜像,可以用下面的命令:
| |
想查看某个位置之前的镜像也可以,只需要把 since 换成 before 即可。
此外,如果镜像构建时,定义了 LABEL,还可以通过 LABEL 来过滤。
| |
删除本地镜像 docker image rm
如果要删除本地的镜像,可以使用 docker image rm 命令,其格式为:
| |
用 ID、镜像名、摘要删除镜像
其中,<镜像> 可以是 镜像短 ID、镜像长 ID、镜像名 或者 镜像摘要。
比如我们有这么一些镜像:
| |
我们可以用镜像的完整 ID,也称为 长 ID,来删除镜像。使用脚本的时候可能会用长 ID,但是人工输入就太累了,所以更多的时候是用 短 ID 来删除镜像。
docker image ls 默认列出的就已经是短 ID 了,一般取前 3 个字符以上,只要足够区分于别的镜像就可以了。
比如这里,如果我们要删除 redis:alpine 镜像,可以执行:
| |
我们也可以用 镜像名,也就是 <仓库名>:<标签>,来删除镜像。
| |
当然,更精确的是使用
镜像摘要删除镜像。
Untagged 和 Deleted
如果观察上面这几个命令的运行输出信息的话,你会注意到删除行为分为两类,一类是 Untagged,另一类是 Deleted。我们之前介绍过,镜像的唯一标识是其 ID 和摘要,而一个镜像可以有多个标签。
因此当我们使用上面命令删除镜像的时候,实际上是在要求删除某个标签的镜像。这就是我们看到的 Untagged 的信息。
因为一个镜像可以对应多个标签,因此当我们删除了所指定的标签后,可能还有别的标签指向了这个镜像,如果是这种情况,那么 Delete 行为就不会发生。所以并非所有的 docker image rm 都会产生删除镜像的行为,有可能仅仅是取消了某个标签而已。
当该镜像所有的标签都被取消了,该镜像很可能会失去了存在的意义,因此会触发删除行为。
镜像是多层存储结构,因此在删除的时候也是从上层向基础层方向依次进行判断删除。镜像的多层结构让镜像复用变得非常容易,因此很有可能某个其它镜像正依赖于当前镜像的某一层。这种情况,依旧不会触发删除该层的行为。**直到没有任何层依赖当前层时,才会真实的删除当前层。**这就是为什么,有时候会奇怪,为什么明明没有别的标签指向这个镜像,但是它还是存在的原因,也是为什么有时候会发现所删除的层数和自己 docker pull 看到的层数不一样的原因。
除了镜像依赖以外,还需要注意的是容器对镜像的依赖。如果有用这个镜像启动的容器存在(即使容器没有运行),那么同样不可以删除这个镜像。之前讲过,容器是以镜像为基础,再加一层容器存储层,组成这样的多层存储结构去运行的。因此该镜像如果被这个容器所依赖的,那么删除必然会导致故障。如果这些容器是不需要的,应该先将它们删除,然后再来删除镜像。
用 docker image ls 命令来配合
像其它可以承接多个实体的命令一样,可以使用 docker image ls -q 来配合使用 docker image rm,这样可以成批的删除希望删除的镜像。
比如,我们需要删除所有仓库名为 redis 的镜像:
| |
或者删除所有在 mongo:3.2 之前的镜像:
| |
操作容器
镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的 命名空间。因此容器可以拥有自己的 root 文件系统、自己的网络配置、自己的进程空间,甚至自己的用户 ID 空间。
容器内的进程是运行在一个隔离的环境里,使用起来,就好像是在一个独立于宿主的系统下操作一样
这种特性使得容器封装的应用比直接在宿主运行更加安全。也因为这种隔离的特性,很多人初学 Docker 时常常会混淆容器和虚拟机
按照 Docker 最佳实践的要求,容器不应该向其存储层内写入任何数据,容器存储层要保持无状态化。所有的文件写入操作,都应该使用 数据卷(Volume)、或者 绑定宿主目录,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。
数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。因此,使用数据卷后,容器删除或者重新运行之后,数据却不会丢失。
启动
启动容器有两种方式,一种是基于镜像新建一个容器并启动,另外一个是将在终止状态(exited)的容器重新启动。
因为 Docker 的容器实在太轻量级了,很多时候用户都是随时删除和新创建容器。
新建并启动 docker run
所需要的命令主要为 docker run。
例如,下面的命令输出一个 “Hello World”,之后终止容器。
| |
这跟在本地直接执行 /bin/echo 'hello world' 几乎感觉不出任何区别。
下面的命令则启动一个 bash 终端,允许用户进行交互。
| |
其中,-t 选项让 Docker 分配一个伪终端(pseudo-tty)并绑定到容器的标准输入上, -i 则让容器的标准输入保持打开。
当利用 docker run 来创建容器时,Docker 在后台运行的标准操作包括:
- 检查本地是否存在指定的镜像,不存在就从 registry 下载
- 利用镜像创建并启动一个容器
- 分配一个文件系统,并在只读的镜像层外面挂载一层可读写层
- 从宿主主机配置的网桥接口中桥接一个虚拟接口到容器中去
- 从地址池配置一个 ip 地址给容器
- 执行用户指定的应用程序
- 执行完毕后容器被终止
容器的核心为所执行的应用程序,所需要的资源都是应用程序运行所必需的。除此之外,并没有其它的资源。可以在伪终端中利用 ps 或 top 来查看进程信息。
| |
可见,容器中仅运行了指定的 bash 应用。这种特点使得 Docker 对资源的利用率极高,是货真价实的轻量级虚拟化。
守护态运行 -d
更多的时候,需要让 Docker 在后台运行而不是直接把执行命令的结果输出在当前宿主机下。此时,可以通过添加 -d 参数来实现。
下面举两个例子来说明一下。
如果不使用 -d 参数运行容器。
| |
容器会把输出的结果 (STDOUT) 打印到宿主机上面
如果使用了 -d 参数运行容器。
| |
此时容器会在后台运行并不会把输出的结果 (STDOUT) 打印到宿主机上面 (输出结果可以用 docker logs 查看)。
注: 容器是否会长久运行,是和 docker run 指定的命令有关,和 -d 参数无关。
使用 -d 参数启动后会返回一个唯一的 id,也可以通过 docker container ls 命令来查看容器信息。
| |
要获取容器的输出信息,可以通过 docker container logs 命令。
| |
终止 docker container stop
可以使用 docker container stop <id>(或 docker stop <id>) 来终止一个运行中的容器。
此外,当 Docker 容器中指定的应用终结时,容器也自动终止。
例如对于上一章节中只启动了一个终端的容器,用户通过 exit 命令或 Ctrl+d 来退出终端时,所创建的容器立刻终止。
终止状态的容器可以用 docker container ls -a 命令看到。例如
| |
处于终止状态的容器,可以通过 docker container start 命令来重新启动。
此外,docker container restart 命令会将一个运行态的容器终止,然后再重新启动它。
进入容器
在使用 -d 参数时,容器启动后会进入后台。
某些时候需要进入容器进行操作,包括使用 docker attach 命令或 docker exec 命令,推荐大家使用 docker exec 命令,原因会在下面说明。
docker attach
下面示例如何使用 docker attach 命令。
| |
注意: 如果从这个 stdin 中 exit,会导致容器的停止。
docker exec
docker exec 后边可以跟多个参数,这里主要说明 -i -t 参数。
只用 -i 参数时,由于没有分配伪终端,界面没有我们熟悉的 Linux 命令提示符,但命令执行结果仍然可以返回。
当 -i -t 参数一起使用时,则可以看到我们熟悉的 Linux 命令提示符。
| |
如果从这个 stdin 中 exit,不会导致容器的停止。这就是为什么推荐大家使用 docker exec 的原因。
导出和导入
导出容器 docker export
如果要导出本地某个容器,可以使用 docker export 命令。
| |
这样将导出容器快照到本地文件。
导入容器快照 docker import
可以使用 docker import 从容器快照文件中再导入为镜像,例如
| |
此外,也可以通过指定 URL 或者某个目录来导入,例如
| |
用户既可以使用
docker load来导入镜像存储文件到本地镜像库,也可以使用docker import来导入一个容器快照到本地镜像库。这两者的区别在于容器快照文件将丢弃所有的历史记录和元数据信息(即仅保存容器当时的快照状态),而镜像存储文件将保存完整记录,体积也要大。
此外,从容器快照文件导入时可以重新指定标签等元数据信息。
删除
删除容器 docker container rm
可以使用 docker container rm(或 docker rm)来删除一个处于终止状态的容器。例如
| |
如果要删除一个运行中的容器,可以添加 -f 参数。Docker 会发送 SIGKILL 信号给容器。
清理所有处于终止状态的容器
用 docker container ls -a 命令可以查看所有已经创建的包括终止状态的容器,如果数量太多要一个个删除可能会很麻烦,用下面的命令可以清理掉所有处于终止状态的容器。
| |
重启
重新启动容器:
| |
访问仓库
镜像构建完成后,可以很容易的在当前宿主机上运行,但是,如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,Docker Registry 就是这样的服务。
一个 Docker Registry 中可以包含多个 仓库(Repository);每个仓库可以包含多个 标签(Tag);每个标签对应一个镜像。
通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本。我们可以通过 <仓库名>:<标签> 的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签。
仓库(Repository)是集中存放镜像的地方。
一个容易混淆的概念是注册服务器(Registry)。实际上注册服务器是管理仓库的具体服务器,每个服务器上可以有多个仓库,而每个仓库下面有多个镜像。从这方面来说,仓库可以被认为是一个具体的项目或目录。例如对于仓库地址 docker.io/ubuntu 来说,docker.io 是注册服务器地址,ubuntu 是仓库名。
大部分时候,并不需要严格区分这两者的概念。
Docker Hub
目前 Docker 官方维护了一个公共仓库 Docker Hub,其中已经包括了数量超过 2,650,000 的镜像。大部分需求都可以通过在 Docker Hub 中直接下载镜像来实现。
登录 docker login
可以通过执行 docker login 命令交互式的输入用户名及密码来完成在命令行界面登录 Docker Hub。
你可以通过 docker logout 退出登录。
拉取镜像 docker pull
你可以通过 docker search 命令来查找官方仓库中的镜像,并利用 docker pull 命令来将它下载到本地。
例如以 centos 为关键词进行搜索:
| |
可以看到返回了很多包含关键字的镜像,其中包括镜像名字、描述、收藏数(表示该镜像的受关注程度)、是否官方创建(OFFICIAL)、是否自动构建 (AUTOMATED)。
根据是否是官方提供,可将镜像分为两类。
- 一种是类似
centos这样的镜像,被称为基础镜像或根镜像。这些基础镜像由 Docker 公司创建、验证、支持、提供。这样的镜像往往使用单个单词作为名字。 - 还有一种类型,比如
ansible/centos7-ansible镜像,它是由 Docker Hub 的注册用户创建并维护的,往往带有用户名称前缀。可以通过前缀username/来指定使用某个用户提供的镜像,比如 ansible 用户。
另外,在查找的时候通过 --filter=stars=N 参数可以指定仅显示收藏数量为 N 以上的镜像。
下载官方 centos 镜像到本地。
| |
推送镜像 docker push
用户也可以在登录后通过 docker push 命令来将自己的镜像推送到 Docker Hub。
以下命令中的 username 请替换为你的 Docker 账号用户名。
| |
数据管理

这一章介绍如何在 Docker 内部以及容器之间管理数据,在容器中管理数据主要有两种方式:
- 数据卷(Volumes)
- 挂载主机目录 (Bind mounts)
实际上,Docker 提供了三种不同的方式用于将宿主的数据挂载到容器中:volumes,bind mounts,tmpfs volumes。当你不知道该选择哪种方式时,记住,volumes 总是正确的选择。
数据卷 volumn
数据卷 是一个可供一个或多个容器使用的特殊目录,它绕过 UFS,可以提供很多有用的特性:
数据卷可以在容器之间共享和重用- 对
数据卷的修改会立马生效 - 对
数据卷的更新,不会影响镜像 数据卷默认会一直存在,即使容器被删除
注意:
数据卷的使用,类似于 Linux 下对目录或文件进行 mount,镜像中的被指定为挂载点的目录中的文件会复制到数据卷中(仅数据卷为空时会复制)。
创建一个数据卷
| |
查看所有的 数据卷
| |
在主机里使用以下命令可以查看指定 数据卷 的信息
| |
启动一个挂载数据卷的容器
在用 docker run 命令的时候,使用 --mount 标记来将 数据卷 挂载到容器里。在一次 docker run 中可以挂载多个 数据卷。
下面创建一个名为 web 的容器,并加载一个 数据卷 到容器的 /usr/share/nginx/html 目录。
| |
查看数据卷的具体信息
在主机里使用以下命令可以查看 web 容器的信息
| |
数据卷 信息在 “Mounts” Key 下面
| |
删除数据卷
| |
数据卷 是被设计用来持久化数据的,它的生命周期独立于容器,Docker 不会在容器被删除后自动删除 数据卷,并且也不存在垃圾回收这样的机制来处理没有任何容器引用的 数据卷。
如果需要在删除容器的同时移除数据卷。可以在删除容器的时候使用 docker rm -v 这个命令。
无主的数据卷可能会占据很多空间,要清理请使用以下命令
| |
挂载主机目录 bind mount
挂载一个主机目录作为数据卷
使用 --mount 标记可以指定挂载一个本地主机的目录到容器中去。
| |
上面的命令加载主机的 /src/webapp 目录到容器的 /usr/share/nginx/html 目录。
这个功能在进行测试的时候十分方便,比如用户可以放置一些程序到本地目录中,来查看容器是否正常工作。本地目录的路径必须是绝对路径,以前使用 -v 参数时如果本地目录不存在 Docker 会自动为你创建一个文件夹,现在使用 --mount 参数时如果本地目录不存在,Docker 会报错。
Docker 挂载主机目录的默认权限是 读写,用户也可以通过增加 readonly 指定为 只读。
| |
加了 readonly 之后,就挂载为 只读 了。如果你在容器内 /usr/share/nginx/html 目录新建文件,会显示如下错误
| |
查看数据卷的具体信息
在主机里使用以下命令可以查看 web 容器的信息
| |
挂载主机目录 的配置信息在 “Mounts” Key 下面
| |
挂载一个本地主机文件作为数据卷
--mount 标记也可以从主机挂载单个文件到容器中
| |
这样就可以记录在容器输入过的命令了。
volume 和 bind 的区别
- volume:如果 volume 是空的而 container 中的目录有内容,那么 docker 会将 container 目录中的内容拷贝到 volume 中,但是如果 volume 中已经有内容,则会将 container 中的目录覆盖。
- bind mount : 不管 host 目录是否有值,都会覆盖 container 映射的目录
使用网络
Docker 允许通过外部访问容器或容器互联的方式来提供网络服务。
外部访问容器
容器中可以运行一些网络应用,要让外部也可以访问这些应用,可以通过 -P 或 -p 参数来指定端口映射。
当使用 -P 标记时,Docker 会随机映射一个端口到内部容器开放的网络端口。
使用 docker container ls 可以看到,本地主机的 32768 被映射到了容器的 80 端口。此时访问本机的 32768 端口即可访问容器内 NGINX 默认页面。
| |
同样的,可以通过 docker logs 命令来查看访问记录。
| |
-p 则可以指定要映射的端口,并且,在一个指定端口上只可以绑定一个容器。
支持的格式有 ip:hostPort:containerPort | ip::containerPort | hostPort:containerPort。
映射所有接口地址
使用 hostPort:containerPort 格式本地的 80 端口映射到容器的 80 端口,可以执行
| |
此时默认会绑定本地所有接口上的所有地址。
映射到指定地址的指定端口
可以使用 ip:hostPort:containerPort 格式指定映射使用一个特定地址,比如 localhost 地址 127.0.0.1
| |
映射到指定地址的任意端口
使用 ip::containerPort 绑定 localhost 的任意端口到容器的 80 端口,本地主机会自动分配一个端口。
| |
还可以使用 udp 标记来指定 udp 端口
| |
查看映射端口配置 docker port
使用 docker port 来查看当前映射的端口配置,也可以查看到绑定的地址
| |
注意:
- 容器有自己的内部网络和 ip 地址(使用
docker inspect查看,Docker 还可以有一个可变的网络配置。) -p标记可以多次使用来绑定多个端口
例如
| |
容器互联
如果你之前有 Docker 使用经验,你可能已经习惯了使用 --link 参数来使容器互联。
随着 Docker 网络的完善,强烈建议大家将容器加入自定义的 Docker 网络来连接多个容器,而不是使用 --link 参数。
新建网络 docker network create
下面先创建一个新的 Docker 网络。
| |
-d 参数指定 Docker 网络类型,有 bridge 和 overlay。其中 overlay 网络类型用于 Swarm mode,在本小节中你可以忽略它。
连接容器
运行一个容器并连接到新建的 my-net 网络
| |
打开新的终端,再运行一个容器并加入到 my-net 网络
| |
再打开一个新的终端查看容器信息
| |
下面通过 ping 来证明 busybox1 容器和 busybox2 容器建立了互联关系。
在 busybox1 容器输入以下命令
| |
用 ping 来测试连接 busybox2 容器,它会解析成 172.19.0.3。
同理在 busybox2 容器执行 ping busybox1,也会成功连接到。
| |
这样,busybox1 容器和 busybox2 容器建立了互联关系。
Docker Compose
如果你有多个容器之间需要互相连接,推荐使用 Docker Compose。
常用命令
动态显示 Docker container 占用情况
| |
使用 Dockerfile 定制镜像 ⭐
镜像的定制实际上就是定制每一层所添加的配置、文件。如果我们可以把每一层修改、安装、构建、操作的命令都写入一个脚本,用这个脚本来构建、定制镜像,那么一些无法重复的问题、镜像构建透明性的问题、体积的问题就都会解决。这个脚本就是 Dockerfile。
Dockerfile 是一个文本文件,其内包含了一条条的指令 (Instruction),每一条指令构建一层,因此每一条指令的内容,就是描述该层应当如何构建。
还以之前定制 nginx 镜像为例,这次我们使用 Dockerfile 来定制。
在一个空白目录中,建立一个文本文件,并命名为 Dockerfile:
| |
其内容为:
| |
这个 Dockerfile 很简单,一共就两行。涉及到了两条指令,FROM 和 RUN。
FROM 指定基础镜像
所谓定制镜像,那一定是以一个镜像为基础,在其上进行定制。就像我们之前运行了一个 nginx 镜像的容器,再进行修改一样,基础镜像是必须指定的。而 FROM 就是指定 基础镜像,因此一个 Dockerfile 中 FROM 是必备的指令,并且必须是第一条指令。
在 Docker Hub 上有非常多的高质量的官方镜像,有可以直接拿来使用的服务类的镜像,如 nginx、redis、mongo、mysql、httpd、php、tomcat 等;也有一些方便开发、构建、运行各种语言应用的镜像,如 node、openjdk、python、ruby、golang 等。可以在其中寻找一个最符合我们最终目标的镜像为基础镜像进行定制。
如果没有找到对应服务的镜像,官方镜像中还提供了一些更为基础的操作系统镜像,如 ubuntu、debian、centos、fedora、alpine 等,这些操作系统的软件库为我们提供了更广阔的扩展空间。
除了选择现有镜像为基础镜像外,Docker 还存在一个特殊的镜像,名为 scratch。这个镜像是虚拟的概念,并不实际存在,它表示一个空白的镜像。
| |
如果你以 scratch 为基础镜像的话,意味着你不以任何镜像为基础,接下来所写的指令将作为镜像第一层开始存在。
不以任何系统为基础,直接将可执行文件复制进镜像的做法并不罕见,对于 Linux 下静态编译的程序来说,并不需要有操作系统提供运行时支持,所需的一切库都已经在可执行文件里了,因此直接 FROM scratch 会让镜像体积更加小巧。使用 Go 语言 开发的应用很多会使用这种方式来制作镜像,这也是为什么有人认为 Go 是特别适合容器微服务架构的语言的原因之一。
RUN 执行命令
RUN 指令是用来执行命令行命令的。由于命令行的强大能力,RUN 指令在定制镜像时是最常用的指令之一。其格式有两种:
- shell 格式:
RUN <命令>,就像直接在命令行中输入的命令一样。刚才写的 Dockerfile 中的RUN指令就是这种格式。 - exec 格式:
RUN ["可执行文件", "参数1", "参数2"],这更像是函数调用中的格式。
既然 RUN 就像 Shell 脚本一样可以执行命令,那么我们是否就可以像 Shell 脚本一样把每个命令对应一个 RUN 呢?比如这样:
| |
之前说过,Dockerfile 中每一个指令都会建立一层,RUN 也不例外。每一个 RUN 的行为,就和刚才我们手工建立镜像的过程一样:新建立一层,在其上执行这些命令,执行结束后,commit 这一层的修改,构成新的镜像。
而上面的这种写法,创建了 7 层镜像。这是完全没有意义的,而且很多运行时不需要的东西,都被装进了镜像里,比如编译环境、更新的软件包等等。结果就是产生非常臃肿、非常多层的镜像,不仅仅增加了构建部署的时间,也很容易出错。 这是很多初学 Docker 的人常犯的一个错误。
Union FS 是有最大层数限制的,比如 AUFS,曾经是最大不得超过 42 层,现在是不得超过 127 层。
上面的 Dockerfile 正确的写法应该是这样:
| |
首先,之前所有的命令只有一个目的,就是编译、安装 redis 可执行文件。因此没有必要建立很多层,这只是一层的事情。因此,这里没有使用很多个 RUN 一一对应不同的命令,而是仅仅使用一个 RUN 指令,并使用 && 将各个所需命令串联起来。将之前的 7 层,简化为了 1 层。在撰写 Dockerfile 的时候,要经常提醒自己,这并不是在写 Shell 脚本,而是在定义每一层该如何构建。
并且,这里为了格式化还进行了换行。Dockerfile 支持 Shell 类的行尾添加 \ 的命令换行方式,以及行首 # 进行注释的格式。良好的格式,比如换行、缩进、注释等,会让维护、排障更为容易,这是一个比较好的习惯。
此外,还可以看到这一组命令的最后添加了清理工作的命令,删除了为了编译构建所需要的软件,清理了所有下载、展开的文件,并且还清理了 apt 缓存文件。这是很重要的一步,我们之前说过,镜像是多层存储,每一层的东西并不会在下一层被删除,会一直跟随着镜像。因此镜像构建时,一定要确保每一层只添加真正需要添加的东西,任何无关的东西都应该清理掉。
很多人初学 Docker 制作出了很臃肿的镜像的原因之一,就是忘记了每一层构建的最后一定要清理掉无关文件。
构建镜像 docker
好了,让我们再回到之前定制的 nginx 镜像的 Dockerfile 来。现在我们明白了这个 Dockerfile 的内容,那么让我们来构建这个镜像吧。
在 Dockerfile 文件所在目录执行:
| |
从命令的输出结果中,我们可以清晰的看到镜像的构建过程。在 Step 2 中,如同我们之前所说的那样,RUN 指令启动了一个容器 9cdc27646c7b,执行了所要求的命令,并最后提交了这一层 44aa4490ce2c,随后删除了所用到的这个容器 9cdc27646c7b。
这里我们使用了 docker build 命令进行镜像构建。其格式为:
| |
在这里我们指定了最终镜像的名称 -t nginx:v3,构建成功后,我们可以像之前运行 nginx:v2 那样来运行这个镜像,其结果会和 nginx:v2 一样。
镜像构建上下文(Context)
如果注意,会看到 docker build 命令最后有一个 .。
. 表示当前目录,而 Dockerfile 就在当前目录,因此不少初学者以为这个路径是在指定 Dockerfile 所在路径,这么理解其实是不准确的。如果对应上面的命令格式,你可能会发现,这是在指定 上下文路径。那么什么是上下文呢?
首先我们要理解 docker build 的工作原理。Docker 在运行时分为 Docker 引擎(也就是服务端守护进程)和客户端工具。Docker 的引擎提供了一组 REST API,被称为 Docker Remote API,而如 docker 命令这样的客户端工具,则是通过这组 API 与 Docker 引擎交互,从而完成各种功能。因此,虽然表面上我们好像是在本机执行各种 docker 功能,但实际上,一切都是使用的远程调用形式在服务端(Docker 引擎)完成。也因为这种 C/S 设计,让我们操作远程服务器的 Docker 引擎变得轻而易举。
当我们进行镜像构建的时候,并非所有定制都会通过 RUN 指令完成,经常会需要将一些本地文件复制进镜像,比如通过 COPY 指令、ADD 指令等。而 docker build 命令构建镜像,其实并非在本地构建,而是在服务端,也就是 Docker 引擎中构建的。那么在这种客户端/服务端的架构中,如何才能让服务端获得本地文件呢?
这就引入了上下文的概念。当构建的时候,用户会指定构建镜像上下文的路径,docker build 命令得知这个路径后,会将路径下的所有内容打包,然后上传给 Docker 引擎。这样 Docker 引擎收到这个上下文包后,展开就会获得构建镜像所需的一切文件。
如果在 Dockerfile 中这么写:
| |
这并不是要复制执行 docker build 命令所在的目录下的 package.json,也不是复制 Dockerfile 所在目录下的 package.json,而是复制 上下文(context) 目录下的 package.json。
因此,COPY 这类指令中的源文件的路径都是相对路径。这也是初学者经常会问的为什么 COPY ../package.json /app 或者 COPY /opt/xxxx /app 无法工作的原因,因为这些路径已经超出了上下文的范围,Docker 引擎无法获得这些位置的文件。如果真的需要那些文件,应该将它们复制到上下文目录中去。
现在就可以理解刚才的命令 docker build -t nginx:v3 . 中的这个 .,实际上是在指定上下文的目录,docker build 命令会将该目录下的内容打包交给 Docker 引擎以帮助构建镜像。
如果观察 docker build 输出,我们其实已经看到了这个发送上下文的过程:
| |
理解构建上下文对于镜像构建是很重要的,避免犯一些不应该的错误。比如有些初学者在发现 COPY /opt/xxxx /app 不工作后,于是干脆将 Dockerfile 放到了硬盘根目录去构建,结果发现 docker build 执行后,在发送一个几十 GB 的东西,极为缓慢而且很容易构建失败。那是因为这种做法是在让 docker build 打包整个硬盘,这显然是使用错误。
一般来说,应该会将 Dockerfile 置于一个空目录下,或者项目根目录下。如果该目录下没有所需文件,那么应该把所需文件复制一份过来。如果目录下有些东西确实不希望构建时传给 Docker 引擎,那么可以用 .gitignore 一样的语法写一个 .dockerignore,该文件是用于剔除不需要作为上下文传递给 Docker 引擎的。
那么为什么会有人误以为 . 是指定 Dockerfile 所在目录呢?这是因为在默认情况下,如果不额外指定 Dockerfile 的话,会将上下文目录下的名为 Dockerfile 的文件作为 Dockerfile。
这只是默认行为,实际上 Dockerfile 的文件名并不要求必须为 Dockerfile,而且并不要求必须位于上下文目录中,比如可以用 -f ../Dockerfile.php 参数指定某个文件作为 Dockerfile。
当然,一般大家习惯性的会使用默认的文件名 Dockerfile,以及会将其置于镜像构建上下文目录中。
其它 docker build 的用法
直接用 Git repo 进行构建
或许你已经注意到了,docker build 还支持从 URL 构建,比如可以直接从 Git repo 中构建:
| |
这行命令指定了构建所需的 Git repo,并且指定分支为 master,构建目录为 /amd64/hello-world/,然后 Docker 就会自己去 git clone 这个项目、切换到指定分支、并进入到指定目录后开始构建。
用给定的 tar 压缩包构建
| |
如果所给出的 URL 不是个 Git repo,而是个 tar 压缩包,那么 Docker 引擎会下载这个包,并自动解压缩,以其作为上下文,开始构建。
从标准输入中读取 Dockerfile 进行构建
| |
或
| |
如果标准输入传入的是文本文件,则将其视为 Dockerfile,并开始构建。这种形式由于直接从标准输入中读取 Dockerfile 的内容,它没有上下文,因此不可以像其他方法那样可以将本地文件 COPY 进镜像之类的事情。
从标准输入中读取上下文压缩包进行构建
| |
如果发现标准输入的文件格式是 gzip、bzip2 以及 xz 的话,将会使其为上下文压缩包,直接将其展开,将里面视为上下文,并开始构建。
Dockerfile 指令详解
COPY 复制文件
格式:
COPY [--chown=<user>:<group>] <源路径>... <目标路径>COPY [--chown=<user>:<group>] ["<源路径1>",... "<目标路径>"]
和 RUN 指令一样,也有两种格式,一种类似于命令行,一种类似于函数调用。
COPY 指令将从构建上下文目录中 <源路径> 的文件/目录复制到新的一层的镜像内的 <目标路径> 位置。比如:
| |
<源路径> 可以是多个,甚至可以是通配符,其通配符规则要满足 Go 的 filepath.Match 规则,如:
| |
<目标路径> 可以是容器内的绝对路径,也可以是相对于工作目录的相对路径(工作目录可以用 WORKDIR 指令来指定)。目标路径不需要事先创建,如果目录不存在会在复制文件前先行创建缺失目录。
此外,还需要注意一点,使用 COPY 指令,源文件的各种元数据都会保留。比如读、写、执行权限、文件变更时间等。这个特性对于镜像定制很有用。特别是构建相关文件都在使用 Git 进行管理的时候。
在使用该指令的时候还可以加上 --chown=<user>:<group> 选项来改变文件的所属用户及所属组。
| |
⭐ 如果源路径为文件夹,复制的时候不是直接复制该文件夹,而是将文件夹中的内容复制到目标路径。
ADD 更高级的复制文件
ADD 指令和 COPY 的格式和性质基本一致。但是在 COPY 基础上增加了一些功能。
比如 <源路径> 可以是一个 URL,这种情况下,Docker 引擎会试图去下载这个链接的文件放到 <目标路径> 去。下载后的文件权限自动设置为 600,如果这并不是想要的权限,那么还需要增加额外的一层 RUN 进行权限调整,另外,如果下载的是个压缩包,需要解压缩,也一样还需要额外的一层 RUN 指令进行解压缩。所以不如直接使用 RUN 指令,然后使用 wget 或者 curl 工具下载,处理权限、解压缩、然后清理无用文件更合理。因此,这个功能其实并不实用,而且不推荐使用。
如果 <源路径> 为一个 tar 压缩文件的话,压缩格式为 gzip, bzip2 以及 xz 的情况下,ADD 指令将会自动解压缩这个压缩文件到 <目标路径> 去。
在某些情况下,这个自动解压缩的功能非常有用,比如官方镜像 ubuntu 中:
| |
但在某些情况下,如果我们真的是希望复制个压缩文件进去,而不解压缩,这时就不可以使用 ADD 命令了。
在 Docker 官方的 Dockerfile 最佳实践文档 中要求,尽可能的使用 COPY,因为 COPY 的语义很明确,就是复制文件而已,而 ADD 则包含了更复杂的功能,其行为也不一定很清晰。最适合使用 ADD 的场合,就是所提及的需要自动解压缩的场合。
另外需要注意的是,ADD 指令会令镜像构建缓存失效,从而可能会令镜像构建变得比较缓慢。
因此在 COPY 和 ADD 指令中选择的时候,可以遵循这样的原则,所有的文件复制均使用 COPY 指令,仅在需要自动解压缩的场合使用 ADD。
在使用该指令的时候还可以加上 --chown=<user>:<group> 选项来改变文件的所属用户及所属组。
| |
CMD 容器启动命令
指定容器启动程序及参数
CMD 指令的格式和 RUN 相似,也是两种格式:
shell格式:CMD <命令>exec格式:CMD ["可执行文件", "参数1", "参数2"...]- 参数列表格式:
CMD ["参数1", "参数2"...]。在指定了ENTRYPOINT指令后,用CMD指定具体的参数。
之前介绍容器的时候曾经说过,Docker 不是虚拟机,容器就是进程。既然是进程,那么在启动容器的时候,需要指定所运行的程序及参数。CMD 指令就是用于指定默认的容器主进程的启动命令的。
在运行时可以指定新的命令来替代镜像设置中的这个默认命令,比如,ubuntu 镜像默认的 CMD 是 /bin/bash,如果我们直接 docker run -it ubuntu 的话,会直接进入 bash。我们也可以在运行时指定运行别的命令,如 docker run -it ubuntu cat /etc/os-release。这就是用 cat /etc/os-release 命令替换了默认的 /bin/bash 命令了,输出了系统版本信息。
在指令格式上,一般推荐使用 exec 格式,这类格式在解析时会被解析为 JSON 数组,因此一定要使用双引号 ",而不要使用单引号。
如果使用 shell 格式的话,实际的命令会被包装为 sh -c 的参数的形式进行执行。比如:
| |
在实际执行中,会将其变更为:
| |
这就是为什么我们可以使用环境变量的原因,因为这些环境变量会被 shell 进行解析处理。
提到 CMD 就不得不提容器中应用在前台执行和后台执行的问题。这是初学者常出现的一个混淆。
Docker 不是虚拟机,容器中的应用都应该以前台执行,而不是像虚拟机、物理机里面那样,用 systemd 去启动后台服务,容器内没有后台服务的概念。
一些初学者将 CMD 写为:
| |
然后发现容器执行后就立即退出了。甚至在容器内去使用 systemctl 命令结果却发现根本执行不了。这就是因为没有搞明白前台、后台的概念,没有区分容器和虚拟机的差异,依旧在以传统虚拟机的角度去理解容器。
对于容器而言,其启动程序就是容器应用进程,容器就是为了主进程而存在的,主进程退出,容器就失去了存在的意义,从而退出,其它辅助进程不是它需要关心的东西。
而使用 service nginx start 命令,则是希望 upstart 来以后台守护进程形式启动 nginx 服务。而刚才说了 CMD service nginx start 会被理解为 CMD [ "sh", "-c", "service nginx start"],因此主进程实际上是 sh。那么当 service nginx start 命令结束后,sh 也就结束了,sh 作为主进程退出了,自然就会令容器退出。
正确的做法是直接执行 nginx 可执行文件,并且要求以前台形式运行。比如:
| |
ENTRYPOINT 入口点
ENTRYPOINT 的格式和 RUN 指令格式一样,分为 exec 格式和 shell 格式。
ENTRYPOINT 的目的和 CMD 一样,都是在指定容器启动程序及参数。ENTRYPOINT 在运行时也可以替代,不过比 CMD 要略显繁琐,需要通过 docker run 的参数 --entrypoint 来指定。
当指定了 ENTRYPOINT 后,CMD 的含义就发生了改变,不再是直接的运行其命令,而是将 CMD 的内容作为参数传给 ENTRYPOINT 指令,换句话说实际执行时,将变为:
| |
那么有了 CMD 后,为什么还要有 ENTRYPOINT 呢?这种 <ENTRYPOINT> "<CMD>" 有什么好处么?让我们来看几个场景。
场景一:让镜像变成像命令一样使用
假设我们需要一个得知自己当前公网 IP 的镜像,那么可以先用 CMD 来实现:
| |
假如我们使用 docker build -t myip . 来构建镜像的话,如果我们需要查询当前公网 IP,只需要执行:
| |
嗯,这么看起来好像可以直接把镜像当做命令使用了,不过命令总有参数,如果我们希望加参数呢?比如从上面的 CMD 中可以看到实质的命令是 curl,那么如果我们希望显示 HTTP 头信息,就需要加上 -i 参数。那么我们可以直接加 -i 参数给 docker run myip 么?
| |
我们可以看到可执行文件找不到的报错,executable file not found。之前我们说过,跟在镜像名后面的是 command,运行时会替换 CMD 的默认值。因此这里的 -i 替换了原来的 CMD,而不是添加在原来的 curl -s http://myip.ipip.net 后面。而 -i 根本不是命令,所以自然找不到。
那么如果我们希望加入 -i 这参数,我们就必须重新完整的输入这个命令:
| |
这显然不是很好的解决方案,而使用 ENTRYPOINT 就可以解决这个问题。现在我们重新用 ENTRYPOINT 来实现这个镜像:
| |
这次我们再来尝试直接使用 docker run myip -i:
| |
可以看到,这次成功了。这是因为当存在 ENTRYPOINT 后,CMD 的内容将会作为参数传给 ENTRYPOINT,而这里 -i 就是新的 CMD,因此会作为参数传给 curl,从而达到了我们预期的效果。
场景二:应用运行前的准备工作
启动容器就是启动主进程,但有些时候,启动主进程前,需要一些准备工作。
比如 mysql 类的数据库,可能需要一些数据库配置、初始化的工作,这些工作要在最终的 mysql 服务器运行之前解决。
此外,可能希望避免使用 root 用户去启动服务,从而提高安全性,而在启动服务前还需要以 root 身份执行一些必要的准备工作,最后切换到服务用户身份启动服务。或者除了服务外,其它命令依旧可以使用 root 身份执行,方便调试等。
这些准备工作是和容器 CMD 无关的,无论 CMD 为什么,都需要事先进行一个预处理的工作。这种情况下,可以写一个脚本,然后放入 ENTRYPOINT 中去执行,而这个脚本会将接到的参数(也就是 <CMD>)作为命令,在脚本最后执行。比如官方镜像 redis 中就是这么做的:
| |
可以看到其中为了 redis 服务创建了 redis 用户,并在最后指定了 ENTRYPOINT 为 docker-entrypoint.sh 脚本。
| |
该脚本的内容就是根据 CMD 的内容来判断,如果是 redis-server 的话,则切换到 redis 用户身份启动服务器,否则依旧使用 root 身份执行。比如:
| |
ENV 设置环境变量
格式有两种:
ENV <key> <value>ENV <key1>=<value1> <key2>=<value2>...
这个指令很简单,就是设置环境变量而已,无论是后面的其它指令,如 RUN,还是运行时的应用,都可以直接使用这里定义的环境变量。
| |
这个例子中演示了如何换行,以及对含有空格的值用双引号括起来的办法,这和 Shell 下的行为是一致的。
定义了环境变量,那么在后续的指令中,就可以使用这个环境变量。比如在官方 node 镜像 Dockerfile 中,就有类似这样的代码:
| |
在这里先定义了环境变量 NODE_VERSION,其后的 RUN 这层里,多次使用 $NODE_VERSION 来进行操作定制。可以看到,将来升级镜像构建版本的时候,只需要更新 7.2.0 即可,Dockerfile 构建维护变得更轻松了。
下列指令可以支持环境变量展开: ADD、COPY、ENV、EXPOSE、FROM、LABEL、USER、WORKDIR、VOLUME、STOPSIGNAL、ONBUILD、RUN。
可以从这个指令列表里感觉到,环境变量可以使用的地方很多,很强大。通过环境变量,我们可以让一份 Dockerfile 制作更多的镜像,只需使用不同的环境变量即可。
ARG 构建参数
格式:ARG <参数名>[=<默认值>]
构建参数和 ENV 的效果一样,都是设置环境变量。所不同的是,ARG 所设置的构建环境的环境变量,在将来容器运行时是不会存在这些环境变量的。但是不要因此就使用 ARG 保存密码之类的信息,因为 docker history 还是可以看到所有值的。
Dockerfile 中的 ARG 指令是定义参数名称,以及定义其默认值。该默认值可以在构建命令 docker build 中用 --build-arg <参数名>=<值> 来覆盖。
灵活的使用 ARG 指令,能够在不修改 Dockerfile 的情况下,构建出不同的镜像。
ARG 指令有生效范围,如果在 FROM 指令之前指定,那么只能用于 FROM 指令中。
| |
使用上述 Dockerfile 会发现无法输出 ${DOCKER_USERNAME} 变量的值,要想正常输出,你必须在 FROM 之后再次指定 ARG
| |
对于多阶段构建,尤其要注意这个问题
| |
对于上述 Dockerfile 两个 FROM 指令都可以使用 ${DOCKER_USERNAME},对于在各个阶段中使用的变量都必须在每个阶段分别指定
| |
VOLUME 定义匿名卷
格式为:
VOLUME ["<路径1>", "<路径2>"...]VOLUME <路径>
之前我们说过,容器运行时应该尽量保持容器存储层不发生写操作,对于数据库类需要保存动态数据的应用,其数据库文件应该保存于卷 (volume) 中;为了防止运行时用户忘记将动态文件所保存目录挂载为卷,在 Dockerfile 中,我们可以事先指定某些目录挂载为匿名卷,这样在运行时如果用户不指定挂载,其应用也可以正常运行,不会向容器存储层写入大量数据。
| |
这里的 /data 目录就会在容器运行时自动挂载为匿名卷,任何向 /data 中写入的信息都不会记录进容器存储层,从而保证了容器存储层的无状态化。当然,运行容器时可以覆盖这个挂载设置。比如:
| |
在这行命令中,就使用了 mydata 这个命名卷挂载到了 /data 这个位置,替代了 Dockerfile 中定义的匿名卷的挂载配置。
EXPOSE 暴露端口
格式为 EXPOSE <端口1> [<端口2>...]。
EXPOSE 指令是声明容器运行时提供服务的端口,这只是一个声明,在容器运行时并不会因为这个声明应用就会开启这个端口的服务。
在 Dockerfile 中写入这样的声明有两个好处,一个是帮助镜像使用者理解这个镜像服务的守护端口,以方便配置映射;另一个用处则是在运行时使用随机端口映射时,也就是 docker run -P 时,会自动随机映射 EXPOSE 的端口。
应该将 EXPOSE 和在运行时使用 -p <宿主端口>:<容器端口> 区分开来。
-p,是映射宿主端口和容器端口,换句话说,就是将容器的对应端口服务公开给外界访问- 而
EXPOSE仅仅是声明容器打算使用什么端口而已,并不会自动在宿主进行端口映射。
WORKDIR 指定工作目录
格式为 WORKDIR <工作目录路径>。
使用 WORKDIR 指令可以来指定工作目录(或者称为当前目录),以后各层的当前目录就被改为指定的目录,如该目录不存在,WORKDIR 会帮你建立目录。
之前提到一些初学者常犯的错误是把 Dockerfile 等同于 Shell 脚本来书写,这种错误的理解还可能会导致出现下面这样的错误:
| |
如果将这个 Dockerfile 进行构建镜像运行后,会发现找不到 /app/world.txt 文件,或者其内容不是 hello。
原因其实很简单,在 Shell 中,连续两行是同一个进程执行环境,因此前一个命令修改的内存状态,会直接影响后一个命令;而在 Dockerfile 中,这两行 RUN 命令的执行环境根本不同,是两个完全不同的容器。这就是对 Dockerfile 构建分层存储的概念不了解所导致的错误。
之前说过每一个 RUN 都是启动一个容器、执行命令、然后提交存储层文件变更。第一层 RUN cd /app 的执行仅仅是当前进程的工作目录变更,一个内存上的变化而已,其结果不会造成任何文件变更。而到第二层的时候,启动的是一个全新的容器,跟第一层的容器更完全没关系,自然不可能继承前一层构建过程中的内存变化。
因此如果需要改变以后各层的工作目录的位置,那么应该使用 WORKDIR 指令。
| |
如果你的 WORKDIR 指令使用的相对路径,那么所切换的路径与之前的 WORKDIR 有关
| |
RUN pwd 的工作目录为 /a/b/c。
USER 指定当前用户
格式:USER <用户名>[:<用户组>]
USER 指令和 WORKDIR 相似,都是改变环境状态并影响以后的层。WORKDIR 是改变工作目录,USER 则是改变之后层的执行 RUN, CMD 以及 ENTRYPOINT 这类命令的身份。
注意,USER 只是帮助你切换到指定用户而已,这个用户必须是事先建立好的,否则无法切换。
| |
如果以 root 执行的脚本,在执行期间希望改变身份,比如希望以某个已经建立好的用户来运行某个服务进程,不要使用 su 或者 sudo,这些都需要比较麻烦的配置,而且在 TTY 缺失的环境下经常出错。建议使用 gosu。
| |
HEALTHCHECK 健康检查
格式:
HEALTHCHECK [选项] CMD <命令>:设置检查容器健康状况的命令HEALTHCHECK NONE:如果基础镜像有健康检查指令,使用这行可以屏蔽掉其健康检查指令
HEALTHCHECK 指令是告诉 Docker 应该如何进行判断容器的状态是否正常,这是 Docker 1.12 引入的新指令。
在没有 HEALTHCHECK 指令前,Docker 引擎只可以通过容器内主进程是否退出来判断容器是否状态异常。很多情况下这没问题,但是如果程序进入死锁状态,或者死循环状态,应用进程并不退出,但是该容器已经无法提供服务了。在 1.12 以前,Docker 不会检测到容器的这种状态,从而不会重新调度,导致可能会有部分容器已经无法提供服务了却还在接受用户请求。
而自 1.12 之后,Docker 提供了 HEALTHCHECK 指令,通过该指令指定一行命令,用这行命令来判断容器主进程的服务状态是否还正常,从而比较真实的反应容器实际状态。
当在一个镜像指定了 HEALTHCHECK 指令后,用其启动容器,初始状态会为 starting,在 HEALTHCHECK 指令检查成功后变为 healthy,如果连续一定次数失败,则会变为 unhealthy。
HEALTHCHECK 支持下列选项:
--interval=<间隔>:两次健康检查的间隔,默认为 30 秒;--timeout=<时长>:健康检查命令运行超时时间,如果超过这个时间,本次健康检查就被视为失败,默认 30 秒;--retries=<次数>:当连续失败指定次数后,则将容器状态视为unhealthy,默认 3 次。
和 CMD, ENTRYPOINT 一样,HEALTHCHECK 只可以出现一次,如果写了多个,只有最后一个生效。
在 HEALTHCHECK [选项] CMD 后面的命令,格式和 ENTRYPOINT 一样,分为 shell 格式,和 exec 格式。命令的返回值决定了该次健康检查的成功与否:0:成功;1:失败;2:保留,不要使用这个值。
假设我们有个镜像是个最简单的 Web 服务,我们希望增加健康检查来判断其 Web 服务是否在正常工作,我们可以用 curl 来帮助判断,其 Dockerfile 的 HEALTHCHECK 可以这么写:
| |
这里我们设置了每 5 秒检查一次(这里为了试验所以间隔非常短,实际应该相对较长),如果健康检查命令超过 3 秒没响应就视为失败,并且使用 curl -fs http://localhost/ || exit 1 作为健康检查命令。
使用 docker build 来构建这个镜像:
| |
构建好了后,我们启动一个容器:
| |
当运行该镜像后,可以通过 docker container ls 看到最初的状态为 (health: starting):
| |
在等待几秒钟后,再次 docker container ls,就会看到健康状态变化为了 (healthy):
| |
如果健康检查连续失败超过了重试次数,状态就会变为 (unhealthy)。
为了帮助排障,健康检查命令的输出(包括 stdout 以及 stderr)都会被存储于健康状态里,可以用 docker inspect 来查看。
| |
ONBUILD 为他人作嫁衣裳
格式:ONBUILD <其它指令>。
ONBUILD 是一个特殊的指令,它后面跟的是其它指令,比如 RUN, COPY 等,而这些指令,在当前镜像构建时并不会被执行。只有当以当前镜像为基础镜像,去构建下一级镜像的时候才会被执行。
Dockerfile 中的其它指令都是为了定制当前镜像而准备的,唯有 ONBUILD 是为了帮助别人定制自己而准备的。
假设我们要制作 Node.js 所写的应用的镜像。我们都知道 Node.js 使用 npm 进行包管理,所有依赖、配置、启动信息等会放到 package.json 文件里。在拿到程序代码后,需要先进行 npm install 才可以获得所有需要的依赖。然后就可以通过 npm start 来启动应用。因此,一般来说会这样写 Dockerfile:
| |
把这个 Dockerfile 放到 Node.js 项目的根目录,构建好镜像后,就可以直接拿来启动容器运行。但是如果我们还有第二个 Node.js 项目也差不多呢?好吧,那就再把这个 Dockerfile 复制到第二个项目里。那如果有第三个项目呢?再复制么?文件的副本越多,版本控制就越困难,让我们继续看这样的场景维护的问题。
如果第一个 Node.js 项目在开发过程中,发现这个 Dockerfile 里存在问题,比如敲错字了、或者需要安装额外的包,然后开发人员修复了这个 Dockerfile,再次构建,问题解决。第一个项目没问题了,但是第二个项目呢?虽然最初 Dockerfile 是复制、粘贴自第一个项目的,但是并不会因为第一个项目修复了他们的 Dockerfile,而第二个项目的 Dockerfile 就会被自动修复。
那么我们可不可以做一个基础镜像,然后各个项目使用这个基础镜像呢?这样基础镜像更新,各个项目不用同步 Dockerfile 的变化,重新构建后就继承了基础镜像的更新?好吧,可以,让我们看看这样的结果。那么上面的这个 Dockerfile 就会变为:
| |
这里我们把项目相关的构建指令拿出来,放到子项目里去。假设这个基础镜像的名字为 my-node 的话,各个项目内的自己的 Dockerfile 就变为:
| |
基础镜像变化后,各个项目都用这个 Dockerfile 重新构建镜像,会继承基础镜像的更新。
那么,问题解决了么?没有。准确说,只解决了一半。如果这个 Dockerfile 里面有些东西需要调整呢?比如 npm install 都需要加一些参数,那怎么办?这一行 RUN 是不可能放入基础镜像的,因为涉及到了当前项目的 ./package.json,难道又要一个个修改么?所以说,这样制作基础镜像,只解决了原来的 Dockerfile 的前 4 条指令的变化问题,而后面三条指令的变化则完全没办法处理。
ONBUILD 可以解决这个问题。让我们用 ONBUILD 重新写一下基础镜像的 Dockerfile:
| |
这次我们回到原始的 Dockerfile,但是这次将项目相关的指令加上 ONBUILD,这样在构建基础镜像的时候,这三行并不会被执行。然后各个项目的 Dockerfile 就变成了简单地:
| |
是的,只有这么一行。当在各个项目目录中,用这个只有一行的 Dockerfile 构建镜像时,之前基础镜像的那三行 ONBUILD 就会开始执行,成功的将当前项目的代码复制进镜像、并且针对本项目执行 npm install,生成应用镜像。
LABEL 为镜像添加元数据
LABEL 指令用来给镜像以键值对的形式添加一些元数据(metadata)。
| |
我们还可以用一些标签来申明镜像的作者、文档地址等:
| |
具体可以参考 https://github.com/opencontainers/image-spec/blob/master/annotations.md
SHELL 指令
格式:SHELL ["executable", "parameters"]
SHELL 指令可以指定 RUN ENTRYPOINT CMD 指令的 shell,Linux 中默认为 ["/bin/sh", "-c"]
| |
两个 RUN 运行同一命令,第二个 RUN 运行的命令会打印出每条命令并当遇到错误时退出。
当 ENTRYPOINT CMD 以 shell 格式指定时,SHELL 指令所指定的 shell 也会成为这两个指令的 shell
| |
| |
Dockerfile 多阶段构建
之前的做法
在 Docker 17.05 版本之前,我们构建 Docker 镜像时,通常会采用两种方式:
全部放入一个 Dockerfile
一种方式是将所有的构建过程编包含在一个 Dockerfile 中,包括项目及其依赖库的编译、测试、打包等流程,这里可能会带来的一些问题:
- 镜像层次多,镜像体积较大,部署时间变长
- 源代码存在泄露的风险
例如,编写 app.go 文件,该程序输出 Hello World!
| |
编写 Dockerfile.one 文件
| |
构建镜像
| |
分散到多个 Dockerfile
另一种方式,就是我们事先在一个 Dockerfile 将项目及其依赖库编译测试打包好后,再将其拷贝到运行环境中,这种方式需要我们编写两个 Dockerfile 和一些编译脚本才能将其两个阶段自动整合起来,这种方式虽然可以很好地规避第一种方式存在的风险,但明显部署过程较复杂。
例如,编写 Dockerfile.build 文件
| |
编写 Dockerfile.copy 文件
| |
新建 build.sh
| |
现在运行脚本即可构建镜像
| |
对比两种方式生成的镜像大小
| |
使用多阶段构建
为解决以上问题,Docker v17.05 开始支持多阶段构建 (multistage builds)。使用多阶段构建我们就可以很容易解决前面提到的问题,并且只需要编写一个 Dockerfile:
例如,编写 Dockerfile 文件
| |
构建镜像
| |
对比三个镜像大小
| |
很明显使用多阶段构建的镜像体积小,同时也完美解决了上边提到的问题。
只构建某一阶段的镜像
我们可以使用 as 来为某一阶段命名,例如
| |
例如当我们只想构建 builder 阶段的镜像时,增加 --target=builder 参数即可
| |
构建时从其他镜像复制文件
上面例子中我们使用 COPY --from=0 /go/src/github.com/go/helloworld/app . 从上一阶段的镜像中复制文件,我们也可以复制任意镜像中的文件。
| |